Den relationella modellen för datahantering utvecklades först av Dr. Edgar F. Codd 1969. Moderna relationsdatabashanteringssystem (RDBMS) är anpassade till paradigmet. Nyckelstrukturen som identifieras med RDBMS är den logiska strukturen som kallas en "tabell". Tabeller består huvudsakligen av rader och kolumner (även kallade poster och attribut eller tupler och fält). I strikt matematisk mening, termen tabell hänvisas faktiskt till som en relation och står för termen "Relationsmodell". I matematik är en relation en representation av en mängd.
Attributet expression ger en bra beskrivning av syftet med en kolumn – det kännetecknar uppsättningen rader som är associerade med den. Varje kolumn måste vara av en viss datatyp och varje rad måste ha några unika identifierande egenskaper som kallas "nycklar". Dataändring är vanligtvis effektivare när den görs med den relationella modellen medan datahämtning kan vara snabbare med den äldre hierarkiska modellen som har omdefinierats i modellens NoSQL-system.
Datanormalisering är en matematisk process för att modellera affärsdata till en form som säkerställer att varje enhet representeras av en enda relation (tabell). De tidiga förespråkarna för relationsmodellen föreslog ett koncept med normala former. Edgar Codd definierade den första, den andra och tredje normala formen. Han fick sedan sällskap av Raymond F. Boyce. Tillsammans definierade de Boyce-Codds normala form. Vid det här laget är sex normala former definierade teoretiskt, men i de flesta praktiska tillämpningar förlänger vi normalt normalisering upp till den tredje normala formen. Varje normalform strävar efter att undvika anomalier under datamodifiering, minska redundansen och beroendet av data i en tabell. Varje nivå av normalisering tenderar att introducera fler tabeller, minska redundans, öka enkelheten för varje tabell men ökar också komplexiteten i hela relationsdatabashanteringssystemet. Så strukturellt tenderar RDBM-system att vara mer komplexa än hierarkiska system.
Varför databasnormalisering:fyra anomalier
Datalagring utan normalisering orsakar ett antal problem med dataförbrukningen. Normaliseringens förespråkare kallade sådana problem anomalier. För att beskriva dessa anomalier, låt oss titta på data som presenteras i fig. 1.

Fig. 1 Staffers Table
Lista 1. Grundläggande tabell för att demonstrera databasnormalisering.
1.1. Skapa tabell
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Infoga rader
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Fråga tabellen
select * from staffers;
Denna tabell representerar i huvudsak två uppsättningar data som oavsiktligt har kombinerats:personalnamn och avdelningar. Observera att all personal kommer från samma avdelning:Engineering. Det gjordes för enkelhetens skull och för att påvisa normalisering. Det finns tre huvudproblem förknippade med att manipulera den här strukturen:
Infogningsavvikelsen
För att infoga en ny post måste vi fortsätta att upprepa avdelningens och chefsnamnen.
Delete-anomali
För att radera en personals post måste vi också ta bort den associerade chefen och avdelningen. Om det finns ett behov av att ta bort ALL personals register måste vi också ta bort alla avdelningar och alla chefer.
Uppdateringsavvikelsen
Om det finns ett behov av att byta chef för någon avdelning måste vi göra ändringen i varje enskild rad i denna tabell eftersom värdena dupliceras för varje medarbetare.
Normala databasformulär
I följande avsnitt av artikeln ska vi försöka beskriva den 1:a, 2:a och 3:e normalformen som är mycket mer sannolikt att observeras i verkliga RDBM-system. Det finns andra förlängningar av teorin som den fjärde, femte och Boyce-Codd normalformerna, men i den här artikeln ska vi begränsa oss till tre normala former.
Den första normala formen
Den första normalformen definieras av fyra regler:
Varje kolumn måste innehålla värden av samma datatyp.
tabellen Staffers uppfyller redan denna regel.
Varje kolumn i en tabell måste vara atomär.
Detta betyder i huvudsak att du bör dela upp innehållet i en kolumn tills de inte längre kan delas. Lägg märke till att rollen kolumnen i Anställda tabell bryter regel 2 för raden med StaffID=3.
Varje rad i en tabell måste vara unik.
Unikhet i normaliserade tabeller uppnås vanligtvis med hjälp av primärnycklar. En primärnyckel definierar varje rad i en tabell unikt. För det mesta definieras en primärnyckel av endast en kolumn. En primärnyckel som består av mer än en kolumn kallas en sammansatt nyckel.
Ordningen som poster lagras i spelar ingen roll.
För att anpassa data i personal tabell med grundsatserna i den första normala formen måste vi dela tabellen som visas i figurerna 2, 3 och 4.
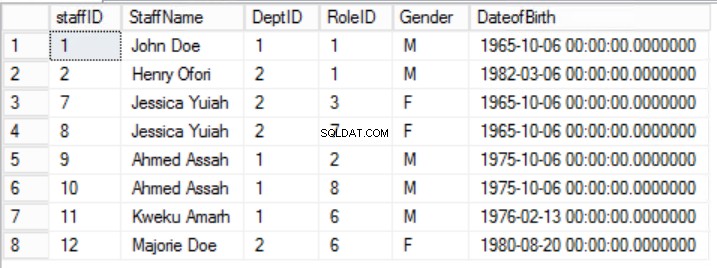
Fig. 2 Staffers Tabell
Vi har begränsat uppgifterna i Anställda tabell och implementerade en sammansatt primärnyckel för att garantera unikhet. Vi har också skapat ytterligare två tabeller Roller och avdelningar som har relationer med kärnanställda personal tabell implementerad med hjälp av främmande nycklar. Granska DDL i lista 2.
Lista 2. DDL för nya anställda Tabell för den första normala formen.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
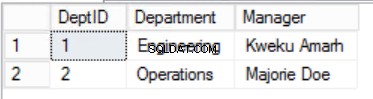
Fig. Tabell 3 avdelningar
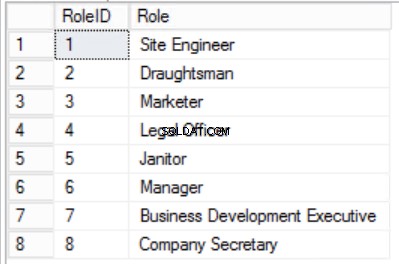
Fig. 4 rolltabell
Den andra normala formen
Formulären 1:a normala måste redan finnas på plats.
Varje icke-nyckelkolumn får inte ha partiellt beroende av den primära nyckeln.
Inriktningen i den andra regeln är att alla kolumner i tabellen måste bero på alla kolumner som utgör den primära nyckeln tillsammans. När vi ser tillbaka på tabellerna i figurerna 2, 3 och 4, finner vi att vi har uppnått alla kraven i den första normala formen. Vi har också uppnått kraven i det andra normalformuläret för två tabeller roller och avdelningar . Men i fallet med personalen tabell, vi har fortfarande ett problem. Vår primära nyckel består av kolumnerna StaffID och RollID.
Regel 2 i det andra normalformuläret bryts här av det faktum att personalens kön och födelsedatum inte beror på roll-ID. Det finns ett partiellt beroende.
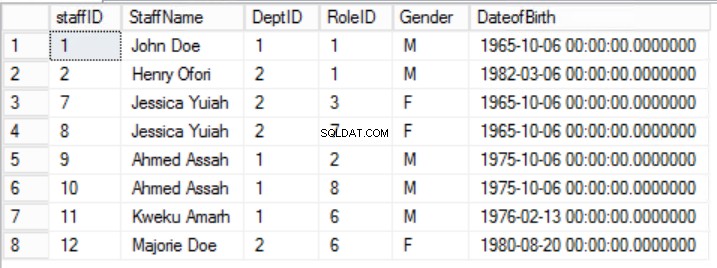
Fig. 5 anställda för den första normala formen
I det givna exemplet kan vi försöka fixa detta genom att ta bort RollID från den primära nyckeln, men om vi gör detta kommer vi att bryta en annan regel:unikhetsrollen som anges i den första normala formen. Vi måste ta ett annat tillvägagångssätt. Vi kommer att ändra personalen tabell med insikten att en personal kan spela mer än en roll. Se fig. 6.
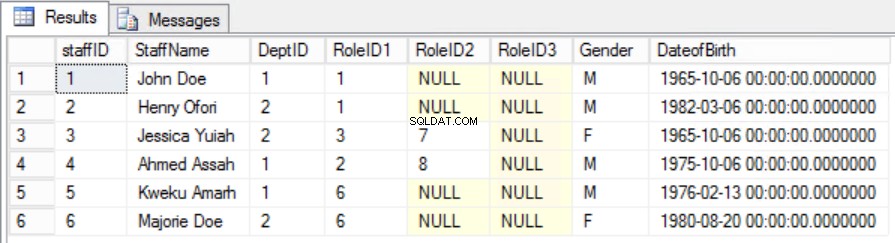
Fig. 6 Staffers Tabell för den andra normalformen
Vi har lyckats bibehålla unikhet och ta bort partiellt beroende.
Lista 3. DDL för New Staffers Tabell för den andra normala formen.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Den tredje normalformen
Formulären 2:a normala måste redan finnas på plats.
Varje icke-nyckelkolumn får inte ha transitivt beroende av den primära nyckeln.
Tyckeln i den tredje normala formen är att det inte får finnas några kolumner som är beroende av icke-nyckelkolumner, även om dessa icke-nyckelkolumner redan beror på den primära nyckeln.
Anta som ett exempel att vi bestämde oss för att lägga till ytterligare en kolumn till Anställda tabell som visas i fig. 7 för att tydligt se personalens chef. Genom att göra det skulle vi ha brutit mot den andra regeln i Third Normal Form, eftersom Manager Name beror på DeptID och DeptID i sin tur beror på StaffID. Detta är ett transitivt beroende.
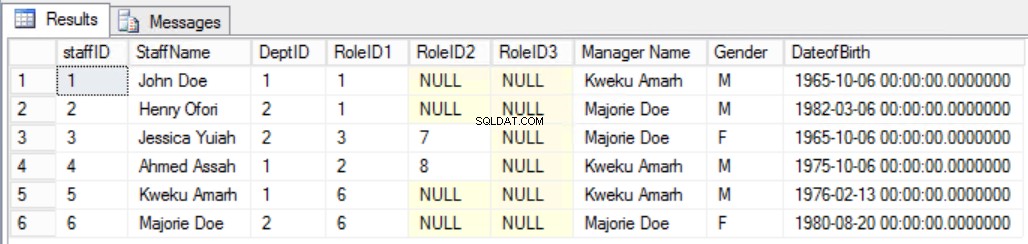
Fig. 7 Staffers Tabell för den tredje normalformen (bruten regel)
Det skulle vara bättre att behålla det gamla formuläret och visa den nödvändiga informationen med hjälp av en koppling mellan tabellen Staffers och avdelningstabellen.
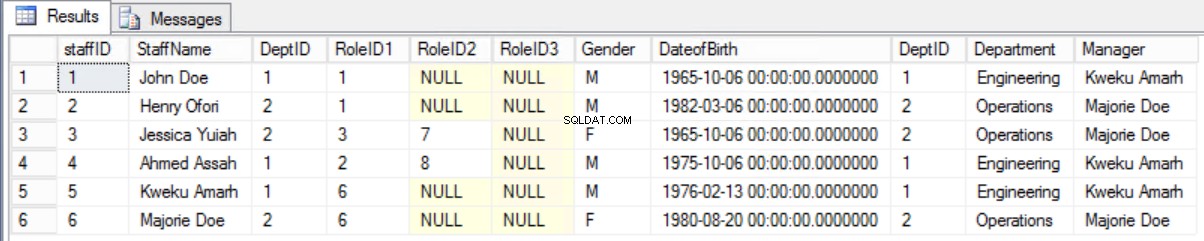
Fig. 8 Gå med mellan medarbetare och avdelning
Anteckning 4. Fråga till visningspersonal och chefer.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktisk tillämpning
De flesta mogna applikationer implementerar reglerna för normalisering i rimlig utsträckning. Vi ser att implementering av datanormalisering ger upphov till användningen av primära nyckelbegränsningar och främmande nyckelbegränsningar. Dessutom dyker sådana frågor som indexering av främmande nycklar också upp när vi går djupare in i ämnet. Tidigare nämnde vi hur bristen på normalisering kan påverka den smidiga manipuleringen av data som beskrivs i avvikelserna för infogning, radering och uppdatering. En brist på korrekt normalisering kan också indirekt påverka frågeprestanda.
Jag har nyligen stött på en tabell som hade den form som visas i tabell 1 som vi ska kalla Customer_Accounts.
S/Nej | Namn | Kontonummer | Telefonnr |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabell 1 Kundkonton
Det största problemet med den här tabellen är att den bryter mot den andra regeln i den första normalformen. Resultatet i vårt fall var att sökning efter kunder baserat på deras telefonnummer krävde användningen av en LIKE i WHERE-satsen och en ledande %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Inverkan av ovanstående konstruktion var att optimeraren aldrig använde ett index, vilket var ett stort prestandaproblem.
Slutsats
Datanormalisering ligger inom databasdesignens område och både utvecklare och DBA:er bör vara uppmärksamma på reglerna som beskrivs i den här artikeln. Det är alltid bättre att göra normaliseringen innan databasen går i produktion. Fördelarna med ett korrekt utformat relationsdatabashanteringssystem är helt enkelt värt ansträngningen.