Medan SQL Server på Linux har stulit nästan alla rubriker om v.Next, finns det några andra intressanta framsteg som kommer i nästa version av vår favoritdatabasplattform. På T-SQL-fronten har vi äntligen ett inbyggt sätt att utföra grupperad strängsammansättning:STRING_AGG() .
Låt oss säga att vi har följande enkla tabellstruktur:
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL UTLÄNDSKA NYCKELREFERENSER dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
För prestandatester kommer vi att fylla i detta med sys.all_objects och sys.all_columns . Men för en enkel demonstration först, låt oss lägga till följande rader:
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'CustomerID');
Om forumen är någon indikation är det ett mycket vanligt krav att returnera en rad för varje objekt, tillsammans med en kommaseparerad lista med kolumnnamn. (Extrapolera det till vilken enhetstyp du än modellerar på det här sättet – produktnamn som är associerade med en beställning, namn på delar som är involverade i sammansättningen av en produkt, underordnade som rapporterar till en chef, etc.) Så, till exempel, med ovanstående data skulle vi vill ha utdata så här:
objektkolumner--------- ----------------------------Anställda EmployeeID,CurrentStatusOrders OrderID,OrderDate, Kund-ID
Sättet vi skulle åstadkomma detta i nuvarande versioner av SQL Server är förmodligen att använda FOR XML PATH , som jag visade vara den mest effektiva utanför CLR i detta tidigare inlägg. I det här exemplet skulle det se ut så här:
VÄLJ [objekt] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FRÅN dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FÖR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Förutsägbart får vi samma utdata som visas ovan. I SQL Server v.Next kommer vi att kunna uttrycka detta enklare:
VÄLJ [objekt] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FRÅN dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ object_id]GROUP BY o.[object_name];
Återigen, detta ger exakt samma utdata. Och vi kunde göra detta med en inbyggd funktion och undviker både den dyra FOR XML PATH byggnadsställningar och STUFF() funktion som används för att ta bort det första kommatecken (detta sker automatiskt).
Vad sägs om beställning?
Ett av problemen med många av kludge-lösningarna för grupperad sammanlänkning är att ordningen på den kommaseparerade listan bör betraktas som godtycklig och icke-deterministisk.
För XML PATH lösning, visade jag i ett annat tidigare inlägg att lägga till en ORDER BY är trivialt och garanterat. Så i det här exemplet kan vi ordna kolumnlistan efter kolumnnamn i alfabetisk ordning istället för att överlåta till SQL Server att sortera (eller inte):
VÄLJ [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] BESTÄLLNING AV c. kolumnnamn -- ändra endast FÖR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Utdata:
objektkolumner--------- ----------------------------Anställda CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, OrderID
CTP 1.1 lägger till WITHIN GROUP till STRING_AGG() , så med den nya metoden kan vi säga:
VÄLJ [objekt] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') INOM GRUPPEN (ORDNING EFTER c.column_name) -- endast ändraFrån dbo.Objects AS oINNER JOIN dbo. Kolumner SOM cON o.[object_id] =c.[object_id]GRUPPER EFTER o.[object_name];
Nu får vi samma resultat. Observera att precis som en vanlig ORDER BY sats, kan du lägga till flera ordningskolumner eller uttryck i WITHIN GROUP () .
Ok, prestanda redan!
Med fyrkärniga 2,6 GHz-processorer, 8 GB minne och SQL Server CTP1.1 (14.0.100.187) skapade jag en ny databas, återskapade dessa tabeller och lade till rader från sys.all_objects och sys.all_columns . Jag såg till att bara inkludera objekt som hade minst en kolumn:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rader VÄLJ [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FRÅN sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS (VÄLJ 1 FRÅN sys.all_columns WHERE [object_id] =o.[object_id] ] ); INSERT dbo.Columns([object_id], column_name) -- 8 085 rader SELECT [object_id], name FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id] ); före>På mitt system gav detta 656 objekt och 8 085 kolumner (ditt system kan ge lite olika siffror).
Planerna
Låt oss först jämföra planerna och tabell-I/O-flikarna för våra två oordnade frågor med hjälp av Plan Explorer. Här är de övergripande mätvärdena för körtid:
Runtime-statistik för XML PATH (överst) och STRING_AGG() (nederst)
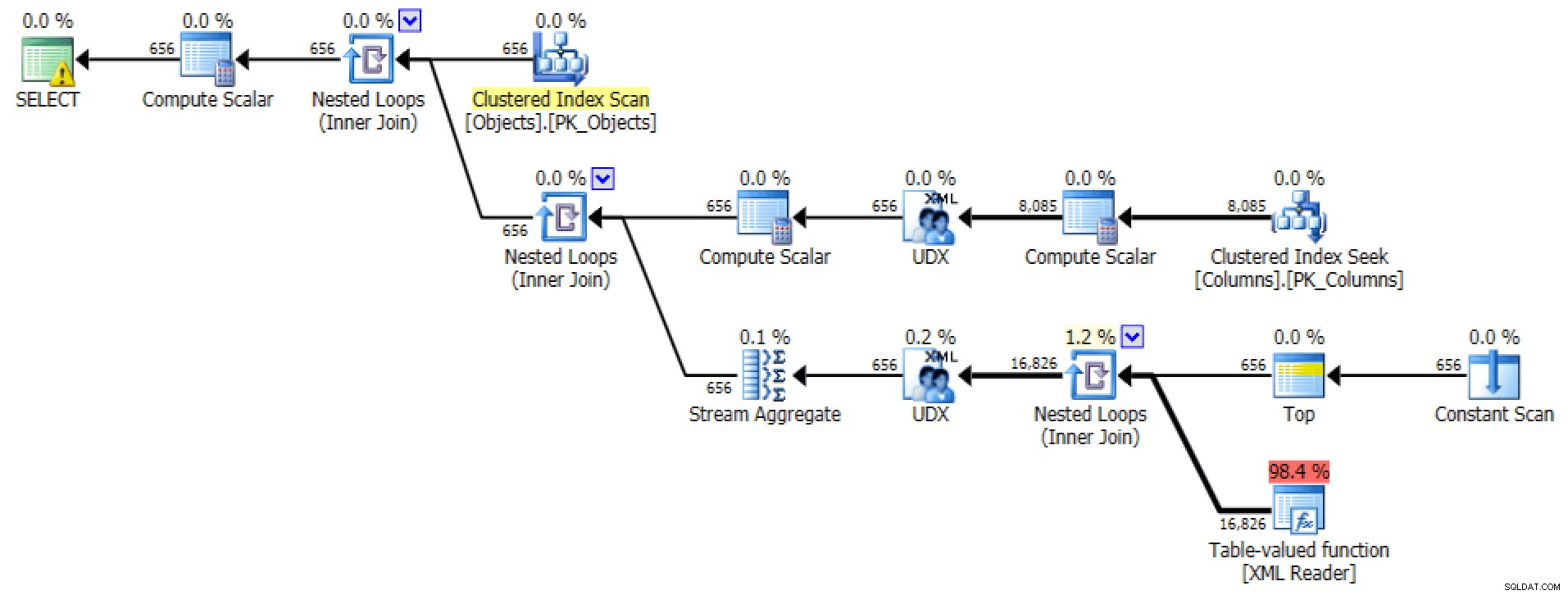
Den grafiska planen och tabell-I/O från
FOR XML PATHfråga:
Planera och tabell I/O för XML PATH, ingen beställning
Och från
STRING_AGGversion:
Planera och tabell I/O för STRING_AGG, ingen beställning
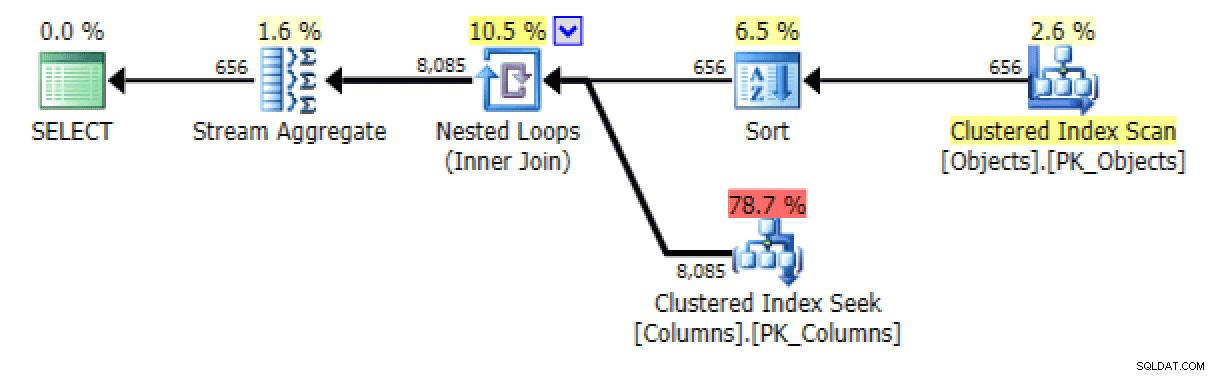
För den sistnämnda verkar den klustrade indexsökningen lite oroande för mig. Detta verkade vara ett bra fall för att testa den sällan använda
FORCESCANledtråd (och nej, detta skulle verkligen inte hjälpaFOR XML PATHfråga):VÄLJ [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FRÅN dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- tillagt tips o .[object_id] =c.[object_id]GRUPPER AV o.[object_name];Nu ser planen och Tabell I/O-fliken mycket ut bättre, åtminstone vid första anblicken:
Planera och tabell I/O för STRING_AGG(), ingen beställning, med FORCESCAN
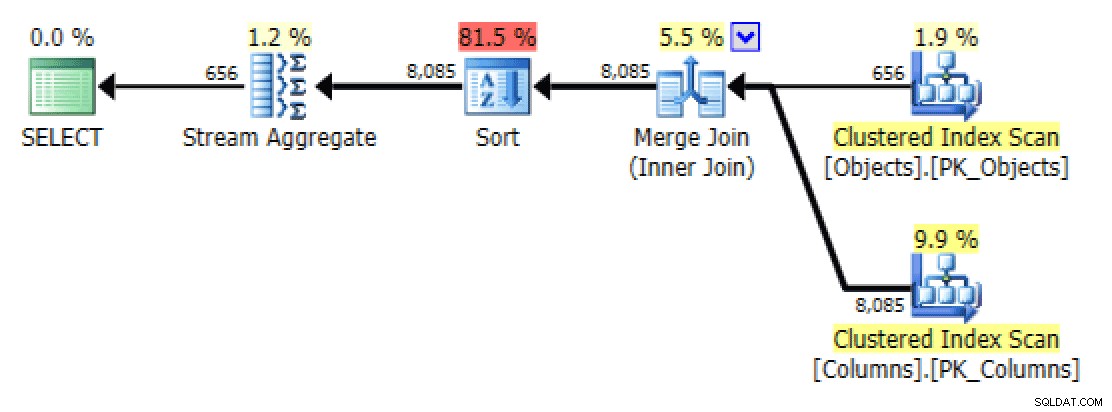
De beställda versionerna av frågorna genererar ungefär samma planer. För
FOR XML PATHversion läggs en sort till:
Lägg till sortering i FOR XML PATH-version
För
STRING_AGG(), väljs en skanning i detta fall, även utanFORCESCANledtråd, och ingen ytterligare sorteringsoperation krävs – så planen ser identisk ut medFORCESCANversion.I skala
Att titta på en plan och enstaka körtidsstatistik kan ge oss en uppfattning om huruvida
STRING_AGG()presterar bättre än den befintligaFOR XML PATHlösning, men ett större test kan vara mer vettigt. Vad händer när vi utför den grupperade sammanfogningen 5 000 gånger?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FRÅN dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value (N'.[1]',N'nvarchar(max)'),1,1,N'')FRÅN dbo.Objects AS o;GO 5000SELECT [för xml-sökväg, oordnad] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') INOM GRUPPEN (ORDER BY c.column_name) FRÅN dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, ordered] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] BESTÄLLNING EFTER c.column_name FÖR XML-SÖG , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FRÅN dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [för xml-sökväg , beställd] =SYSDATETIME();Efter att ha kört det här skriptet fem gånger tog jag ett genomsnitt av varaktighetstalen och här är resultaten:
Längd (millisekunder) för olika grupperade sammanlänkningsmetoder
Vi kan se att vår
FORCESCANantydan gjorde verkligen saken värre – medan vi flyttade bort kostnaden från den klustrade indexsökningen var sorten faktiskt mycket värre, även om de uppskattade kostnaderna ansåg att de var relativt likvärdiga. Ännu viktigare är att vi kan se attSTRING_AGG()erbjuder en prestandafördel, oavsett om de sammanlänkade strängarna behöver beställas på ett specifikt sätt. Som medSTRING_SPLIT(), som jag tittade på i mars, är jag ganska imponerad av att den här funktionen skalas långt före "v1."Jag har ytterligare tester planerade, kanske för ett framtida inlägg:
- När all data kommer från en enda tabell, med och utan ett index som stöder beställning
- Liknande prestandatester på Linux
Under tiden, om du har specifika användningsfall för grupperad sammanlänkning, vänligen dela dem nedan (eller e-posta mig på abertrand@sentryone.com). Jag är alltid öppen för att se till att mina tester är så verkliga som möjligt.