SQL Server 2005 lade till möjligheten att inkludera nonkey-kolumner i ett icke-klustrat index. I SQL Server 2000 och tidigare, för ett icke-klustrat index, var alla kolumner som definierats för ett index nyckelkolumner, vilket innebar att de var en del av varje nivå i indexet, från roten ner till bladnivån. När en kolumn definieras som en inkluderad kolumn är den endast en del av bladnivån. Books Online noterar följande fördelar med inkluderade kolumner:
- De kan vara datatyper som inte är tillåtna som indexnyckelkolumner.
- De beaktas inte av databasmotorn när antalet indexnyckelkolumner eller indexnyckelstorleken beräknas.
Till exempel kan en varchar(max)-kolumn inte vara en del av en indexnyckel, men den kan vara en inkluderad kolumn. Dessutom räknas den varchar(max)-kolumnen inte mot gränsen på 900 byte (eller 16 kolumner) som gäller för indexnyckeln.
Dokumentationen noterar också följande prestandafördelar:
Ett index med nonkey-kolumner kan avsevärt förbättra frågeprestanda när alla kolumner i frågan ingår i indexet antingen som nyckel- eller nonkey-kolumner. Prestandavinster uppnås eftersom frågeoptimeraren kan hitta alla kolumnvärden inom indexet; tabell- eller klustrade indexdata nås inte vilket resulterar i färre disk I/O-operationer.Vi kan dra slutsatsen att oavsett om indexkolumnerna är nyckelkolumner eller nonkeykolumner så får vi en förbättring i prestanda jämfört med när alla kolumner inte är en del av indexet. Men finns det någon prestandaskillnad mellan de två varianterna?
Inställningen
Jag installerade en kopia av AdventuresWork2012-databasen och verifierade indexen för tabellen Sales.SalesOrderHeader med Kimberly Tripps version av sp_helpindex:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Standardindex för Sales.SalesOrderHeader
Vi börjar med en enkel fråga för testning som hämtar data från flera kolumner:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Om vi kör detta mot AdventureWorks2012-databasen med SQL Sentry Plan Explorer och kontrollerar planen och tabell-I/O-utgången, ser vi att vi får en klustrad indexskanning med 689 logiska läsningar:
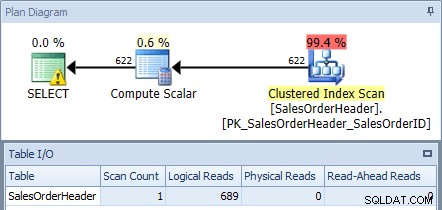
Utförandeplan från den ursprungliga frågan
(I Management Studio kunde du se I/O-statistiken med SET STATISTICS IO ON; .)
SELECT har en varningsikon eftersom optimeraren rekommenderar ett index för denna fråga:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Vi kommer först att skapa indexet som optimeraren rekommenderar (som heter NCI1_included), samt variationen med alla kolumner som nyckelkolumner (som heter NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Om vi kör den ursprungliga frågan igen, en gång antyder den med NCI1 och en gång antyder den med NCI1_included, ser vi en plan som liknar originalet, men den här gången finns det en indexsökning för varje icke-klustrat index, med motsvarande värden för Tabell I/ O, och liknande kostnader (båda cirka 0,006):
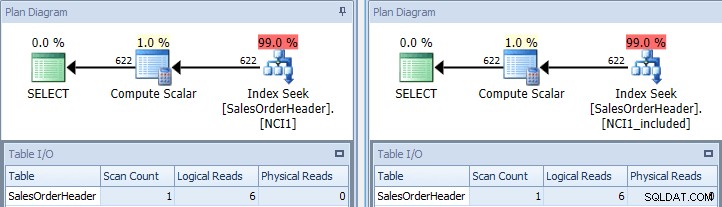
Original fråga med indexsök – nyckel till vänster, inkludera på höger
(Antalet skanningar är fortfarande 1 eftersom indexsökningen faktiskt är en förklädd intervallskanning.)
Nu är AdventureWorks2012-databasen inte representativ för en produktionsdatabas vad gäller storlek, och om vi tittar på antalet sidor i varje index ser vi att de är exakt likadana:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
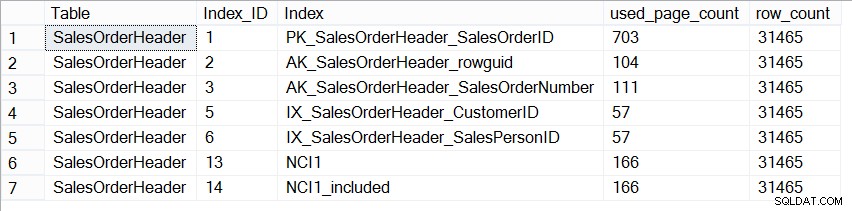
Storlek på index på Sales.SalesOrderHeader
Om vi tittar på prestanda är det idealiskt (och roligare) att testa med en större datamängd.
Test 2
Jag har en kopia av AdventureWorks2012-databasen som har en SalesOrderHeader-tabell med över 200 miljoner rader (skript HÄR), så låt oss skapa samma icke-klustrade index i den databasen och köra frågorna igen:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
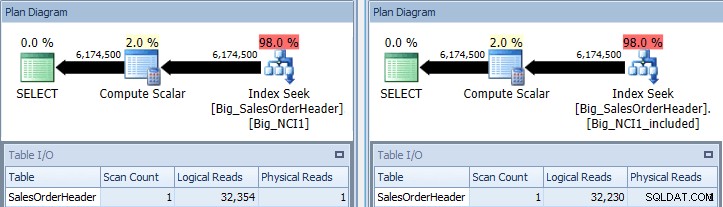
Original fråga med indexsök mot Big_NCI1 (l) och Big_NCI1_Included ( r)
Nu får vi lite data. Frågan returnerar över 6 miljoner rader, och att söka efter varje index kräver drygt 32 000 läsningar, och den uppskattade kostnaden är densamma för båda frågorna (31,233). Inga prestandaskillnader än, och om vi kontrollerar storleken på indexen ser vi att indexet med de inkluderade kolumnerna har 5 578 färre sidor:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Storlek på index på Sales.Big_SalesOrderHeader
Om vi gräver mer i detta och kollar dm_dm_index_physical_stats kan vi se att skillnaden finns i indexets mellannivåer:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
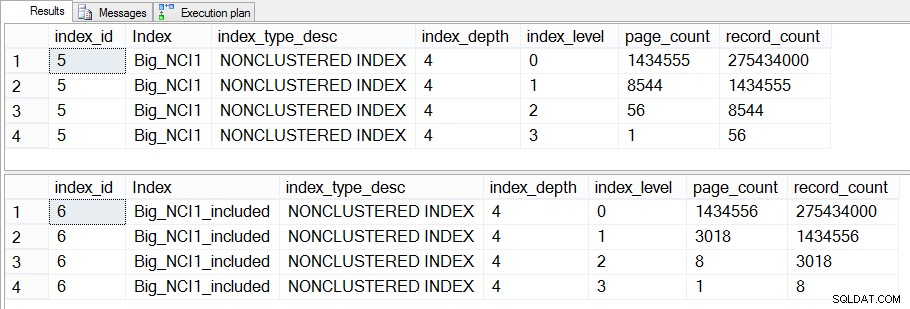
Storlek på index (nivåspecifikt) på Sales.Big_SalesOrderHeader
Skillnaden mellan mellannivåerna för de två indexen är 43 MB, vilket kanske inte är signifikant, men jag skulle nog ändå vara benägen att skapa indexet med inkluderade kolumner för att spara utrymme – både på disken och i minnet. Ur ett frågeperspektiv ser vi fortfarande ingen stor förändring i prestanda mellan indexet med alla kolumner i nyckeln och indexet med de inkluderade kolumnerna.
Test 3
För detta test, låt oss ändra frågan och lägga till ett filter för [SubTotal] >= 100 till WHERE-satsen:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
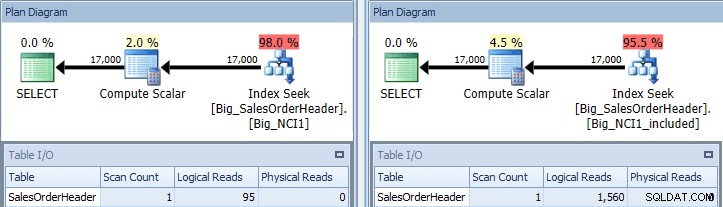
Exekveringsplan för frågan med SubTotal-predikat mot båda indexen
Nu ser vi en skillnad i I/O (95 läsningar mot 1 560), kostnad (0,848 mot 1,55) och en subtil men anmärkningsvärd skillnad i frågeplanen. När du använder indexet med alla kolumner i nyckeln är sökpredikatet kund-ID och delsumman:
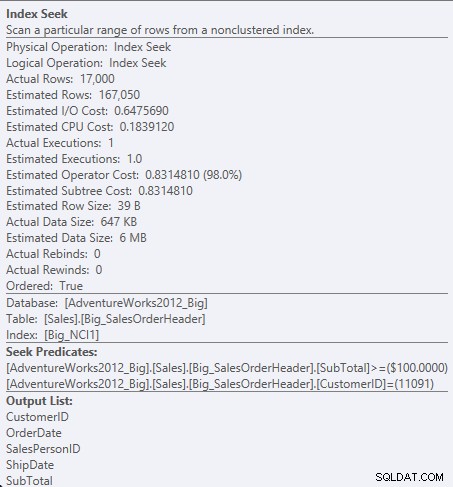
Sök predikat mot NCI1
Eftersom SubTotal är den andra kolumnen i indexnyckeln, ordnas data och SubTotal finns på mellannivåerna i indexet. Motorn kan söka direkt till den första posten med ett kund-ID på 11091 och Subtotal som är större än eller lika med 100, och sedan läsa igenom indexet tills det inte finns fler poster för kund-ID 11091.
För indexet med de inkluderade kolumnerna finns delsumman bara på bladnivån i indexet, så kund-ID är sökpredikatet och delsumman är ett restpredikat (bara listat som predikat i skärmdumpen):
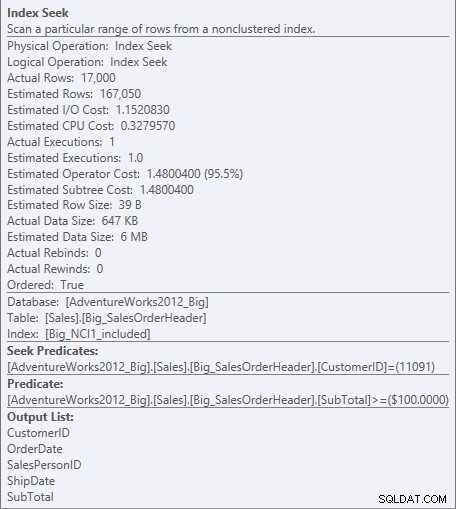
Sök predikat och restpredikat mot NCI1_included
Motorn kan söka direkt till den första posten där kund-ID är 11091, men sedan måste den titta på varje registrera för kund-ID 11091 för att se om delsumman är 100 eller högre, eftersom data är sorterade efter kund-ID och försäljningsorder-ID (klustringsnyckel).
Test 4
Vi kommer att prova ytterligare en variant av vår fråga, och den här gången lägger vi till en BESTÄLLNING AV:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
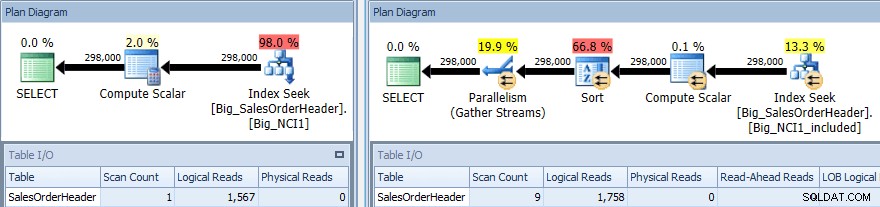
Utförandeplan för frågan med SORT mot båda indexen
Återigen har vi en förändring i I/O (men mycket liten), en förändring i kostnad (1,5 mot 9,3) och mycket större förändring i planformen; vi ser också ett större antal skanningar (1 mot 9). Frågan kräver att data sorteras efter Subtotal; när SubTotal är en del av indexnyckeln sorteras den, så när posterna för kund-ID 11091 hämtas är de redan i den begärda ordningen.
När SubTotal finns som en inkluderad kolumn måste posterna för kund-ID 11091 sorteras innan de kan returneras till användaren, därför skjuter optimeraren in en sorteringsoperator i frågan. Som ett resultat begär (och ges) frågan som använder indexet Big_NCI1_included också ett minnesanslag på 29 312 KB, vilket är anmärkningsvärt (och finns i planens egenskaper).
Sammanfattning
Den ursprungliga frågan vi ville svara på var om vi skulle se en prestandaskillnad när en fråga använde indexet med alla kolumner i nyckeln, jämfört med indexet med de flesta kolumnerna inkluderade i bladnivån. I vår första uppsättning tester var det ingen skillnad, men i vårt tredje och fjärde test var det det. Det beror i slutändan på frågan. Vi tittade bara på två varianter – den ena hade ett extra predikat, den andra hade en ORDER BY – många fler finns.
Vad utvecklare och DBA:er behöver förstå är att det finns några stora fördelar med att inkludera kolumner i ett index, men de kommer inte alltid att prestera på samma sätt som index som har alla kolumner i nyckeln. Det kan vara frestande att flytta kolumner som inte ingår i predikat och kopplingar från nyckeln, och bara inkludera dem, för att minska indexets totala storlek. Men i vissa fall kräver detta mer resurser för att köra frågor och kan försämra prestandan. Nedbrytningen kan vara obetydlig; det kanske inte är...du vet inte förrän du testar. När du utformar ett index är det därför viktigt att tänka på kolumnerna efter den ledande – och förstå om de behöver vara en del av nyckeln (t.ex. för att det ger fördelar att hålla informationen i ordning) eller om de kan tjäna sitt syfte som inkluderats. kolumner.
Som är typiskt med indexering i SQL Server, måste du testa dina frågor med dina index för att bestämma den bästa strategin. Det förblir en konst och en vetenskap – att försöka hitta det minsta antalet index för att tillfredsställa så många frågor som möjligt.