Den här artikeln handlar om T-SQL (Transact-SQL) fönsterfunktioner och deras grundläggande användning i dagliga dataanalysuppgifter.
Det finns många alternativ till T-SQL när det kommer till dataanalys. Men när förbättringar över tid och introduktion av fönsterfunktioner övervägs, kan T-SQL utföra dataanalys på en grundläggande nivå och, i vissa fall, även utöver det.
Om SQL-fönsterfunktioner
Låt oss först bekanta oss med SQL Window-funktioner i samband med Microsofts dokumentation.
Microsoft Definition
En fönsterfunktion beräknar ett värde för varje rad i fönstret.
Enkel definition
En fönsterfunktion hjälper oss att fokusera på en viss del (fönster) av resultatuppsättningen så att vi kan utföra dataanalys endast på den specifika delen (fönstret), snarare än på hela resultatuppsättningen.
Med andra ord, SQL-fönsterfunktioner förvandlar en resultatuppsättning till flera mindre uppsättningar för dataanalysändamål.
Vad är en resultatuppsättning
Enkelt uttryckt består en resultatuppsättning av alla poster som hämtas genom att köra en SQL-fråga.
Till exempel kan vi skapa en tabell med namnet Produkt och infoga följande data i den:
-- (1) Create the Product table CREATE TABLE [dbo].[Product] ( [ProductId] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(40) NOT NULL, [Region] VARCHAR(40) NOT NULL ) -- (2) Populate the Product table INSERT INTO Product (ProductId,Name,Region) VALUES (1,'Laptop','UK'),(2,'PC','UAE'),(3,'iPad','UK')
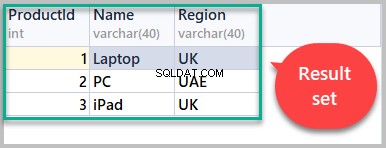
Nu kommer resultatuppsättningen som hämtas med hjälp av skriptet nedan att innehålla alla rader från Produkt tabell:
-- (3) Result set SELECT [ProductId], [Name],[Region] FROM Product
Vad är ett fönster
Det är viktigt att först förstå konceptet med ett fönster eftersom det relaterar till SQL-fönsterfunktioner. I detta sammanhang är ett fönster bara ett sätt att begränsa ditt omfång genom att rikta in sig på en specifik del av resultatuppsättningen (som vi redan nämnt ovan).
Du kanske undrar nu – vad betyder egentligen "inriktning på en specifik del av resultatuppsättningen"?
För att återgå till exemplet vi tittade på, kan vi skapa ett SQL-fönster baserat på produktregionen genom att dela upp resultatuppsättningen i två fönster.
Förstå Row_Number()
För att fortsätta måste vi använda funktionen Row_Number() som tillfälligt ger ett sekvensnummer till utdataraderna.
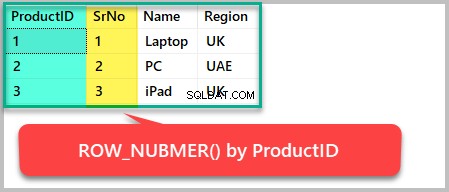
Om vi till exempel vill lägga till radnummer till resultatuppsättningen baserat på Produkt-ID, vi måste använda ROW_NUMBER() för att beställa den efter produkt-ID enligt följande:
--Using the row_number() function to order the result set by ProductID SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID) AS SrNo,Name,Region FROM Product
Om vi nu vill ha funktionen Row_Number() för att beställa resultatet satt av ProduktID fallande, sedan sekvensen av utdatarader baserat på ProduktID kommer att ändras enligt följande:
--Using the row_number() function to order the result set by ProductID descending SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID DESC) AS SrNo,Name,Region FROM Product

Det finns inga SQL-fönster ännu eftersom det enda vi har gjort är att beställa uppsättningen efter specifika kriterier. Som diskuterats tidigare innebär fönster att dela upp resultatuppsättningen i flera mindre uppsättningar för att analysera var och en av dem separat.
Skapa ett fönster med Row_Number()
För att skapa ett SQL-fönster i vår resultatuppsättning måste vi partitionera det baserat på någon av kolumnerna det innehåller.
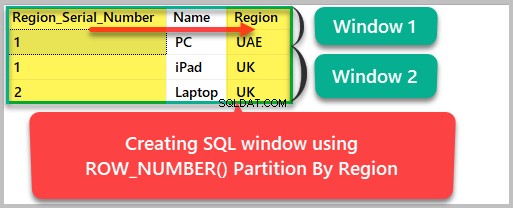
Vi kan nu partitionera resultatet som ställts in efter region enligt följande:
--Creating a SQL window based on Region SELECT ROW_NUMBER() OVER (Partition by region ORDER BY Region) as Region_Serial_Number , Name, Region FROM dbo.Product
Välj – Överklausul
Med andra ord, Välj med Over klausul banar väg för SQL-fönsterfunktioner genom att partitionera en resultatuppsättning i mindre fönster.
Enligt Microsofts dokumentation, Välj med Över sats definierar ett fönster som sedan kan användas av vilken fönsterfunktion som helst.
Låt oss nu skapa en tabell som heter Köksprodukt enligt följande:
CREATE TABLE [dbo].[KitchenProduct]
(
[KitchenProductId] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Country] VARCHAR(40) NOT NULL,
[Quantity] INT NOT NULL,
[Price] DECIMAL(10,2) NOT NULL
);
GO
INSERT INTO dbo.KitchenProduct
(Name, Country, Quantity, Price)
VALUES
('Kettle','Germany',10,15.00)
,('Kettle','UK',20,12.00)
,('Toaster', 'France',10,10.00)
,('Toaster','UAE',10,12.00)
,('Kitchen Clock','UK',50,20.00)
,('Kitchen Clock','UAE',35,15.00) Låt oss nu titta på tabellen:
SELECT [KitchenProductId], [Name], [Country], [Quantity], [Price] FROM dbo.KitchenProduct

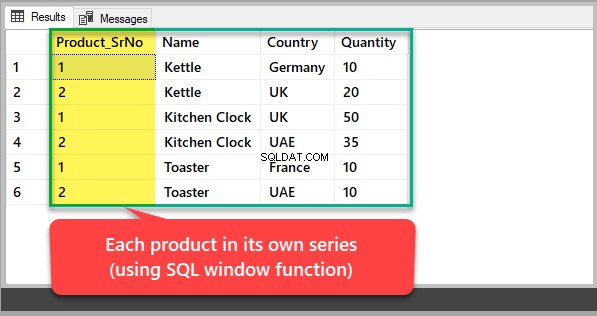
Om du vill se varje produkt med sitt eget serienummer snarare än ett nummer baserat på det generaliserade produkt-ID:t, måste du använda en SQL-fönsterfunktion för att partitionera resultatet från produkten enligt följande:
-- Viewing each product in its own series SELECT ROW_NUMBER() OVER (Partition by Name order by Name) Product_SrNo,Name,Country,Quantity FROM dbo.KitchenProduct
Kompatibilitet (Välj – Överklausul)
Enligt Microsofts dokumentation , Select – Over Clause är kompatibel med följande SQL-databasversioner:
- SQL Server 2008 och senare
- Azure SQL Database
- Azure SQL Data Warehouse
- Parallell Data Warehouse
Syntax
VÄLJ – ÖVER (Partionera efter
Observera att jag har förenklat syntaxen för att göra i t lätt att förstå; se den Microsoft-dokumentation för att se full syntax.
Förutsättningar
Den här artikeln är i grunden skriven för nybörjare, men det finns fortfarande några förutsättningar som måste hållas i åtanke.
Kännedom om T-SQL
Den här artikeln förutsätter att läsarna har grundläggande kunskaper om T-SQL och kan skriva och köra grundläggande SQL-skript.
Ställ in tabellen Försäljningsexempel
Den här artikeln kräver följande exempeltabell så att vi kan köra våra SQL-fönsterfunktionsexempel:
-- (1) Create the Sales sample table
CREATE TABLE [dbo].[Sales]
(
[SalesId] INT NOT NULL IDENTITY(1,1),
[Product] VARCHAR(40) NOT NULL,
[Date] DATETIME2,
[Revenue] DECIMAL(10,2),
CONSTRAINT [PK_Sales] PRIMARY KEY ([SalesId])
);
GO
-- (2) Populating the Sales sample table
SET IDENTITY_INSERT [dbo].[Sales] ON
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (1, N'Laptop', N'2017-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (2, N'PC', N'2017-01-01 00:00:00', CAST(100.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (3, N'Mobile Phone', N'2018-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (4, N'Accessories', N'2018-01-01 00:00:00', CAST(150.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (5, N'iPad', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (6, N'PC', N'2019-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (7, N'Laptop', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
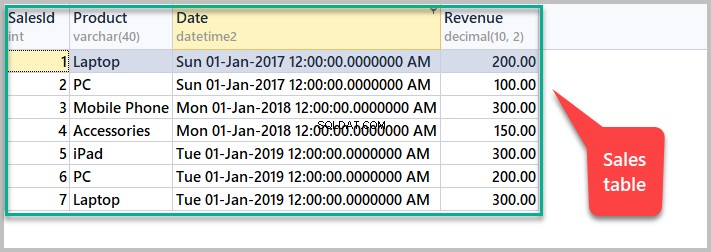
SET IDENTITY_INSERT [dbo].[Sales] OFF Se alla försäljningar genom att köra följande skript:
-- View sales SELECT [SalesId],[Product],[Date],[Revenue] FROM dbo.Sales
Gruppera efter vs SQL-fönsterfunktioner
Man kan undra – vad är skillnaden mellan att använda Group By-satsen och SQL-fönsterfunktionerna?
Tja, svaret finns i exemplen nedan.
Gruppera efter exempel
För att se den totala försäljningen per produkt kan vi använda Gruppera efter enligt följande:
-- Total sales by product using Group By SELECT Product ,SUM(REVENUE) AS Total_Sales FROM dbo.Sales GROUP BY Product ORDER BY Product

Så Group By-klausulen hjälper oss att se den totala försäljningen. Det totala försäljningsvärdet är summan av intäkterna för alla liknande produkter på samma rad utan att använda Group By-klausul. Vad händer om vi är intresserade av att se intäkterna (försäljningen) för varje enskild produkt tillsammans med den totala försäljningen?
Det är här som SQL-fönsterfunktioner kommer till handling.
Exempel på SQL-fönsterfunktion
För att se produkten, intäkterna och totala intäkterna för alla liknande produkter måste vi dela upp data på biproduktbasis med OVER() enligt följande:
-- Total sales by product using an SQL window function SELECT Product ,REVENUE ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) AS Total_Sales FROM dbo.Sales
Utdata ska vara som följer:

Så vi kan nu enkelt se försäljningen för varje enskild produkt tillsammans med den totala försäljningen för den produkten. Till exempel intäkterna för PC är 100,00 men total försäljning (summan av intäkter för datorn produkt) är 300,00 eftersom två olika PC-modeller såldes.
Grundläggande analys med aggregerade funktioner
Aggregatfunktioner returnerar ett enda värde efter att ha utfört beräkningar på en uppsättning data.
I det här avsnittet kommer vi att utforska SQL-fönsterfunktioner ytterligare – specifikt genom att använda dem tillsammans med aggregerade funktioner för att utföra grundläggande dataanalys.
Vanliga samlade funktioner
De vanligaste aggregerade funktionerna är:
- Summa
- Räkna
- Min
- Max
- Genomsnitt (genomsnitt)
Aggregerad dataanalys per produkt
För att analysera resultatuppsättningen på biproduktbasis med hjälp av aggregatfunktioner, måste vi helt enkelt använda en aggregatfunktion med en biproduktpartition inuti OVER()-satsen:
-- Data analysis by product using aggregate functions SELECT Product,Revenue ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY PRODUCT) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY PRODUCT) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY PRODUCT) as Average_Sales FROM dbo.Sales

Om du tittar närmare på datorn eller Bärbar dator produkter, du kommer att se hur aggregerade funktioner fungerar tillsammans med SQL-fönsterfunktionen.
I exemplet ovan kan vi se att Intäktsvärdet för PC är 100,00 första gången och 200,00 nästa gång, men den totala försäljningen uppgår till 300,00. Liknande information kan ses för resten av de aggregerade funktionerna.
Aggregerad dataanalys efter datum
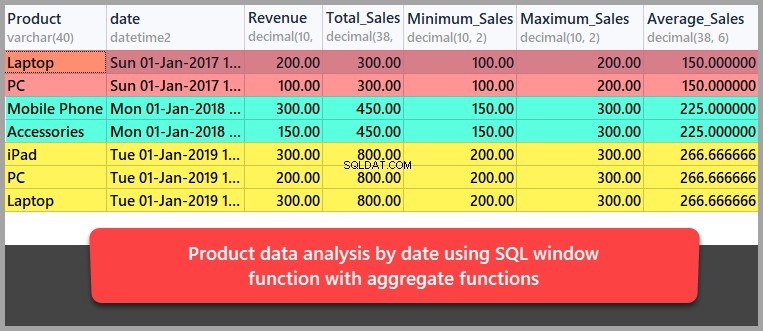
Låt oss nu utföra lite dataanalys av produkterna per datum med hjälp av SQL-fönsterfunktioner i kombination med aggregerade funktioner.
Den här gången kommer vi att partitionera resultatet inställt efter datum snarare än efter produkt enligt följande:
-- Data analysis by date using aggregate functions SELECT Product,date,Revenue ,SUM(REVENUE) OVER (PARTITION BY DATE) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY DATE) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY DATE) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY DATE) as Average_Sales FROM dbo.Sales
Med detta har vi lärt oss grundläggande dataanalystekniker med användning av SQL-fönsterfunktioner.
Saker att göra
Nu när du är bekant med SQL-fönsterfunktioner, försök med följande:
- Med tanke på exemplen vi tittade på, utför grundläggande dataanalys med SQL-fönsterfunktioner i exempeldatabasen som nämns i den här artikeln.
- Lägga till en kundkolumn i tabellen Försäljningsexempel och se hur rik din dataanalys kan bli när ytterligare en kolumn (kund) läggs till i den.
- Lägga till en regionkolumn i Försäljningsexempeltabellen och utför grundläggande dataanalys med aggregerade funktioner per region.