Hur lagras all information om den allmänna opinionen? Vi kollar in en opinionsundersökningsdatamodell.
Alla vill veta vad allmänheten tycker, från politiker och företag till privatpersoner som vill veta vad andra tycker om ett visst ämne. Den här typen av jobb utförs vanligtvis av byråer som är specialiserade på den typen av forskning.
Idag ska vi ta en titt på en datamodell som en sådan byrå kan använda för att lagra all relevant omröstningsdata, från frågor och fördefinierade svar till den faktiska feedbacken. Dessa data skulle senare användas för att skapa olika rapporter. Så låt oss börja.
Idé
Omröstningar kan skapas var som helst. De kan vara välplanerade och inkludera ett representativt urval av allmänheten (baserat på demografi). Eller så kan du göra dem på plats, t.ex. om du vill förutsäga valresultat baserat på ett urval (som en exit-undersökning) skulle du förmodligen fråga folk vid vallokalen hur de röstade.
Å andra sidan, om du vill skapa samma omröstning före valet, skulle du förmodligen välja ett urval och kontakta individer per telefon eller personligen. Vanligtvis finns det bara ett fåtal frågor för den här typen av enkäter – några för att täcka demografi och andra för att täcka det vi verkligen är intresserade av.
Omröstningar kan också vara mycket mer komplexa, t.ex. om du vill veta den allmänna opinionen om en viss produkt, som täcker allt från dess prestanda till dess förpackning.
I den här artikeln kommer jag inte att diskutera hur man väljer ett urval av personer; snarare kommer jag att fokusera på själva omröstningen, dess frågor och svaren.
Datamodell
Datamodell för opinionsbyråer
Modellen består av tre ämnesområden:
PollsQuestions & AnswersResult
Vi kommer att beskriva varje ämnesområde i den ordning det är listat.
Omröstningar
Innan vi börjar ställa frågor måste vi definiera vad vi är intresserade av. Vi definierar enkäter och frågeformulär i det här avsnittet och lägger sedan till frågor och svar i nästa.
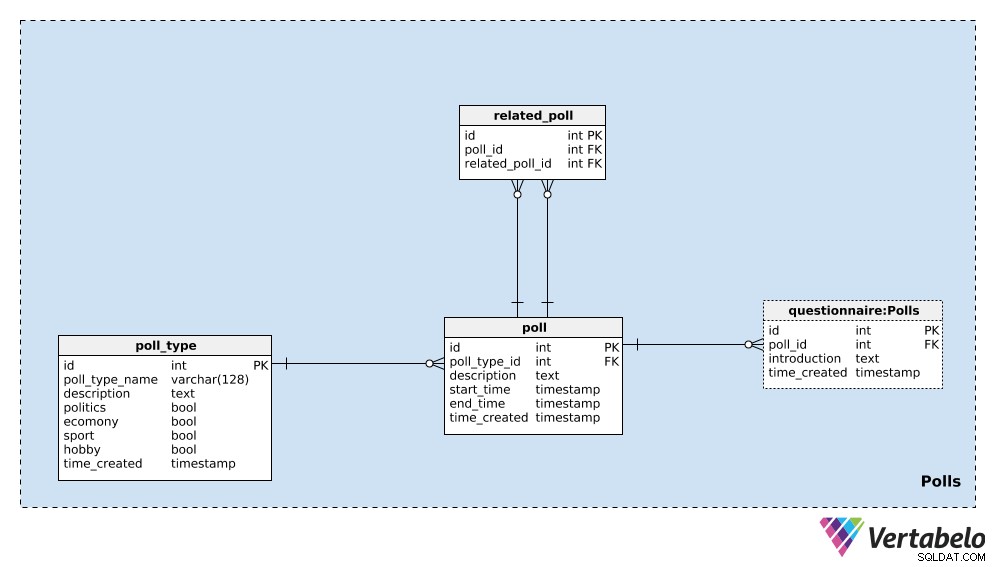
Vi börjar med poll_type lexikon. Vi kan förvänta oss att vi för det mesta kommer att upprepa omröstningar av samma typ. Den vanligaste typen är nog valundersökningar, men vi vill kunna lägga till nya omröstningstyper på vägen. För varje omröstningstyp lagrar vi ett UNIKT poll_type_name och använd description attribut för att ge ytterligare information.
Fyra flaggor – politics , economy , sport och hobby – används för att beteckna typen av omröstning. En undersökning kan täcka ett eller flera av dessa ämnen; om det behövs kan vi dela upp dessa kategorier i en separat ordbok och ha en många-till-många-relation mellan den ordboken och poll_type bord.
Det sista attributet i den här tabellen är time_created . Det anger det ögonblick då en rad infogas i denna tabell.
Nästa sak vi behöver göra är att definiera en enda poll . Detta är en enstaka instans, t.ex. "Presidentval i USA 2020 – undersökning i april 2020" . För varje omröstning lagrar vi följande information:
poll_type_id– En referens tillpoll_type.description– Alla detaljer relaterade till denna omröstning, i textformat.start_timeochend_time– De definierade start- och sluttider under vilka denna omröstning görs.time_created– Det faktiska ögonblicket då denna omröstning skapades.
Omröstningar kan relateras till varandra. I exemplet med "presidentvalet i USA 2020 – undersökningen april 2020" , vi skulle kunna göra samma undersökning nästa månad för att se de senaste åsikterna. Vi skulle kalla detta "Presidentval i USA 2020 – undersökning i maj 2020" . Dessa två undersökningar är relaterade eftersom deras resultat visar trender. För att etablera den relationen använder vi related_poll bord i vår modell. Den innehåller endast det UNIKA paret poll_id – related_poll_id , som betecknar omröstningen och dess föregångare.
Observera att vi kan använda den här tabellen för att lagra alla omröstningar som är relaterade på något sätt, inte bara föregångare/efterföljare. Om vi skulle vilja definiera olika relationer, skulle vi behöva lägga till en annan ordbok – men vi kommer inte att gå på det sättet i den här artikeln.
Den sista tabellen i detta ämnesområde är questionnaire tabell. I de flesta fall kommer varje enkät att ha exakt ett frågeformulär, men jag vill lämna alternativet att vi kan ha mer än en om det behövs. Därför har jag använt en separat tabell. I den här tabellen lagrar vi endast ID:t för den relaterade omröstningen (poll_id ), en introduction som beskriver det frågeformuläret och tidsstämpeln när posten infogades (time_created ).
Frågor och svar
Nu är vi redo att skapa alla frågeformulärdetaljer. Vi kan också lista alla frågor vi vill ställa samt alla fördefinierade svar.
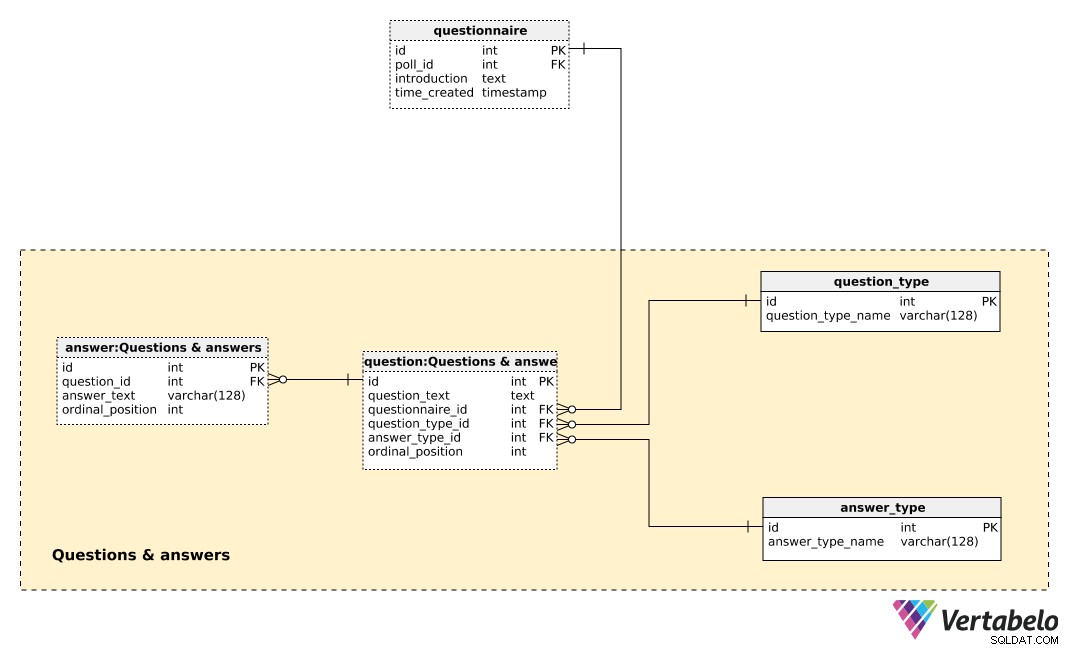
Den centrala tabellen i detta ämnesområde är question tabell. Varje fråga definieras av följande detaljer:
question_text– En text som kommer att visas för varje individ som tillfrågas.questionnaire_id– En referens som anger frågeformuläret för denna fråga.question_type_id– En referens som angerquestion_type, som UNIKT betecknas medquestion_type_name. Det är i grunden kategorier, t.ex. "demografi", "åsikt", "kontroll" etc. Dessa skulle göra det möjligt för oss att separera demografiska frågor och åsiktsfrågor och hitta en korrelation mellan dem.answer_type_id– En hänvisning till vilken typ av svar som kommer att användas för denna fråga. Varjeanswer_typedefinieras UNIKT avanswer_type_nameoch anger hur svaret visas. Vissa förväntade typer är "öppna", "lista", "kryssruta" och "flera".ordinal_position– Detta värde anger läget för denna fråga i frågeformuläret. Tillsammans medquestionnaire_id, den utgör den alternativa nyckeln för denna tabell.
En lista över alla fördefinierade svar lagras i answer tabell. Om frågetypen inte är öppen (dvs. text kommer inte att skrivas in av individen) kommer vi att ha en uppsättning fördefinierade svar. För varje svar kommer vi att definiera frågan den tillhör (question_id ), answer_text , och ordinal_position av det svaret i den frågan. Återigen ett UNIKT par – den här gången question_id – ordinal_position – bildar den alternativa nyckeln för denna tabell.
Resultat
I de två föregående ämnesområdena har vi definierat allt vi behöver för att skapa omröstningen och börja ställa frågor. Nu måste vi definiera en datastruktur för att lagra faktiska svar.
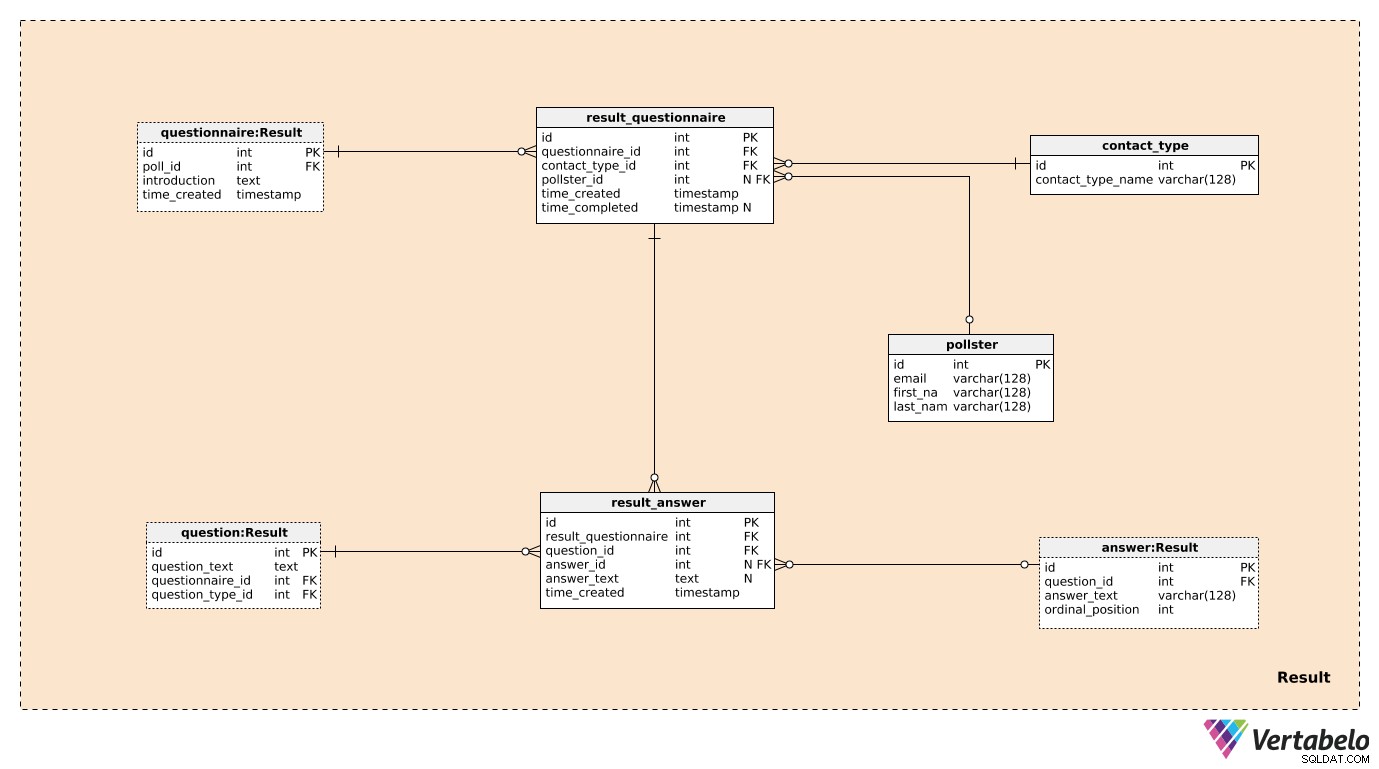
Tre av de sju tabellerna i Result ämnesområde har tidigare nämnts och beskrivits. Dessa är questionnaire , question och answer . De återstående fyra borden används för att lagra det vi verkligen är intresserade av.
Vi skapar en post i result_questionnaire tabell för varje individ som deltar i omröstningen. questionnaire_id förse esus med all information om den relevanta undersökningen. contact_type_id är en referens till contact_type lexikon. Värden i den här tabellen beskriver hur vi har interagerat med den här personen. Dessa värden definieras UNIKT av contact_type_name värde och kan vara något som "telefon", "personligt", "e-post", "webbformulär" etc.
pollster_id attribut är en referens till pollster tabell, som ger information om vem som genomförde den faktiska omröstningen. För varje pollster , vi lagrar endast deras UNIKA e-postadress och deras first_name och last_name . time_created attributet anger den faktiska tidpunkten då denna post skapades, medan time_completed kommer att ställas in i det ögonblick denna undersökning är klar. (Tills dess kommer det att vara NULL).
Den sista tabellen i modellen är result_answer tabell. Som namnet antyder är det här vi kommer att lagra de faktiska svaren vi fick från undersökningstagare. För varje post i den här tabellen har vi:
result_questionnaire_id– En hänvisning till det relevanta frågeformuläret.question_id– En referens som anger frågan som besvaras av detta svar.answer_id– En hänvisning till svaret som användes för att svara på denna fråga. Det här attributet kommer att innehålla ett NULL-värde när frågan är av typen "öppen" (eftersom det inte fanns några fördefinierade svar att välja mellan).answer_text– Texten som infogades för att besvara denna fråga. Detta attribut kommer att innehålla ett värde när frågan var "öppen"; i alla andra fall kommer det att vara NULL.time_created– Den faktiska tidpunkten då detta svar infogades i vårt system.
Möjliga förbättringar
Hittills har vi täckt hur vi kan lagra omröstningsdata. Vi har inte diskuterat vad vi skulle göra med uppgifterna efter att omröstningen är stängd. Vi kan förvänta oss att vi inte kommer att behöva den gamla datan i framtiden, åtminstone inte i vår operativa databas. Därför kan vi göra två saker:
- Lagra en omröstningssammanfattning i en separat tabell i driftdatabasen. Detta skulle hålla sådan information till vårt förfogande om vi ville se vad som hände med en liknande undersökning.
- Lagra alla omröstningsdata i en backupdatabas som hade samma struktur som den operativa databasen. Detta skulle ge oss tillgång till detaljerna när vi behövde dem.
Vi skulle också kunna skapa ett datalager för att lagra omröstningsresultat, men det skulle inte vara nödvändigt om vi redan hade gjort de uppgifter som beskrivs i de två punkterna.
Vad tycker du om vår datamodell för opinionsundersökningar?
Vi skulle vilja höra din åsikt om vad vi kan ändra för att förbättra opinionsundersökningsdatamodellen. Har du branscherfarenhet? Tror du att vi missat något? Skulle du lägga till eller ta bort något? Ser fram emot att höra dina åsikter.