
I mars startade jag en serie om genomgripande prestationsmyter i SQL Server. En övertygelse jag stöter på då och då är att du kan överdimensionera varchar- eller nvarchar-kolonner utan någon påföljd.
Låt oss anta att du lagrar e-postadresser. I ett tidigare liv har jag sysslat med det här ganska mycket – på den tiden angav RFC 3696 att en e-postadress kunde vara 320 tecken (64chars@255chars). En nyare RFC, #5321, bekräftar nu att 254 tecken är det längsta en e-postadress kan vara. Och om någon av er har en så lång adress, ja, vi kanske borde prata. :-)
Nu, oavsett om du följer den gamla standarden eller den nya, måste du stödja möjligheten att någon kommer att använda alla tillåtna tecken. Vilket innebär att du måste använda 254 eller 320 tecken. Men vad jag har sett folk göra är att inte bry sig om att undersöka standarden alls, utan bara anta att de behöver stödja 1 000 tecken, 4 000 tecken eller till och med mer.
Så låt oss ta en titt på vad som händer när vi har tabeller med en e-postadresskolumn av varierande storlek, men som lagrar exakt samma data:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Låt oss nu generera 10 000 fiktiva e-postadresser från systemets metadata och fylla alla fyra tabellerna med samma data:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;REBUIL_V;
För att validera att varje tabell innehåller exakt samma data:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Alla fyra ger 35 och 77 för mig; din körsträcka kan variera. Låt oss också se till att alla fyra tabellerna upptar samma antal sidor på disken:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Alla fyra av dessa frågor ger 89 sidor (återigen, din körsträcka kan variera).
Låt oss nu ta en typisk fråga som resulterar i en klustrad indexskanning:
SELECT id, email FROM dbo.Email_<size>;
Om vi tittar på saker som varaktighet, avläsningar och beräknade kostnader verkar de alla vara lika:
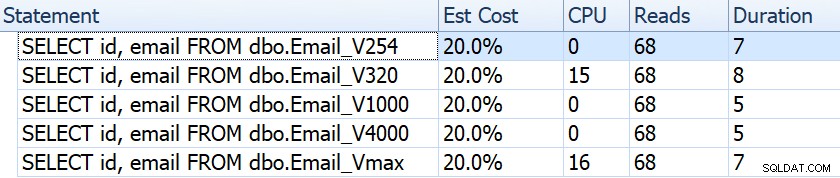
Detta kan invagga människor i ett falskt antagande att det inte finns någon prestationspåverkan alls. Men om vi tittar lite närmare, på verktygstipset för den klustrade indexskanningen i varje plan, ser vi en skillnad som kan spela in i andra, mer utarbetade frågor:

Härifrån ser vi att ju större kolumndefinitionen är, desto högre blir den uppskattade rad- och datastorleken. I denna enkla fråga är I/O-kostnaden (0,0512731) densamma för alla frågor, oavsett definition, eftersom den klustrade indexskanningen måste läsa all data ändå.
Men det finns andra scenarier där denna beräknade rad och totala datastorlek kommer att påverka:operationer som kräver ytterligare resurser, till exempel sortering. Låt oss ta den här löjliga frågan som inte tjänar något egentligt syfte, annat än att kräva flera sorteringsoperationer:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Vi kör dessa fyra frågor och vi ser att planerna alla ser ut så här:

Den varningsikonen på SELECT-operatören visas dock bara på 4000/max-tabellerna. Vad är varningen? Det är en varning för överdrivet minnestillstånd, introducerad i SQL Server 2016. Här är varningen för varchar(4000):

Och för varchar(max):

Låt oss titta lite närmare och se vad som händer, åtminstone enligt sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Resultat:

I mitt scenario påverkades inte varaktigheten av skillnaderna i minnesbidrag (förutom för maxfallet), men du kan tydligt se den linjära utvecklingen som sammanfaller med den deklarerade storleken på kolumnen. Som du kan använda för att extrapolera vad som skulle hända på ett system med otillräckligt minne. Eller en mer utarbetad fråga mot en mycket större datamängd. Eller betydande samtidighet. Vilket som helst av dessa scenarier kan kräva spill för att bearbeta sorteringsoperationerna, och varaktigheten skulle nästan säkert påverkas som ett resultat.
Men var kommer dessa större minnesbidrag ifrån? Kom ihåg att det är samma fråga, mot exakt samma data. Problemet är att för vissa operationer måste SQL Server ta hänsyn till hur mycket data *kan* finnas i en kolumn. Den gör inte detta baserat på att faktiskt profilera data, och den kan inte göra några antaganden baserat på <=201 histogramstegvärden. Istället måste den uppskatta att varje rad har ett värde som hälften av den deklarerade kolumnstorleken . Så för en varchar(4000) antar den att varje e-postadress är 2 000 tecken lång.
När det inte är möjligt att ha en e-postadress längre än 254 eller 320 tecken, finns det inget att vinna på att överdimensionera, och det finns mycket att förlora. Att öka storleken på en kolumn med variabel bredd senare är mycket lättare än att hantera alla nackdelar nu.
Självklart, överdimensionerad char eller nchar kolumner kan ha mycket mer uppenbara straff.