Hithighlighting är en funktion som många önskar att SQL Servers Full-Text Search skulle stödja inbyggt. Det är här du kan returnera hela dokumentet (eller ett utdrag) och peka ut de ord eller fraser som hjälpte till att matcha dokumentet med sökningen. Att göra det på ett effektivt och korrekt sätt är ingen lätt uppgift, som jag fick reda på från första hand.
Som ett exempel på träffmarkering:när du gör en sökning i Google eller Bing får du nyckelorden i fetstil i både titeln och utdraget (klicka på endera bilden för att förstora):

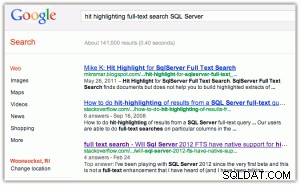
[För övrigt tycker jag att två saker är roliga här:(1) att Bing gynnar Microsofts egenskaper mycket mer än Google gör, och (2) att Bing bryr sig om att returnera 2,2 miljoner resultat, varav många troligen är irrelevanta.]
Dessa utdrag kallas vanligtvis "snippets" eller "frågeorienterade sammanfattningar". Vi har efterfrågat den här funktionen i SQL Server ett tag, men har ännu inte hört några goda nyheter från Microsoft:
- Connect #295100 :Fulltextsöksammanfattningar (hit-markering)
- Anslut #722324:Skulle vara trevligt om SQL Full Text Search gav stöd för kodavsnitt/markering
Frågan dyker också upp på Stack Overflow då och då:
- Hur man gör träff-markering av resultat från en SQL Server-fulltextfråga
- Kommer SQL Server 2012 FTS att ha inbyggt stöd för träffmarkering?
Det finns några dellösningar. Detta skript från Mike Kramar, till exempel, kommer att producera ett träffmarkerat utdrag, men tillämpar inte samma logik (som språkspecifika ordbrytare) på själva dokumentet. Den använder också ett absolut teckenantal, så utdraget kan börja och sluta med delord (som jag kommer att visa inom kort). Det senare är ganska lätt att fixa, men ett annat problem är att det laddar hela dokumentet i minnet, snarare än att utföra någon form av streaming. Jag misstänker att i fulltextindex med stora dokumentstorlekar kommer detta att bli en märkbar prestandaträff. För närvarande kommer jag att fokusera på en relativt liten genomsnittlig dokumentstorlek (35 KB).
Ett enkelt exempel
Så låt oss säga att vi har en mycket enkel tabell, med ett fulltextindex definierat:
SKAPA FULLTEXTKATALOG [FTSDemo];GO CREATE TABLE [dbo].[Dokument]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Datum] DATE NOT NULL , [Titel] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO CREATE FULLTEXT INDEX ON [dbo].[Dokument]( [Content] LANGUAGE [engelska] , [Title] LANGUAGE [engelska])KEY INDEX [PK_Document] PÅ ([FTSDemo]);
Den här tabellen är fylld med ett fåtal dokument (särskilt 7), såsom självständighetsförklaringen och Nelson Mandelas "Jag är beredd att dö"-tal. En typisk fulltextsökning i den här tabellen kan vara:
SELECT d.Title, d.[Innehåll]FRÅN dbo.[Dokument] AS d INNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS t ON d.ID =t.[KEY] BESTÄLL MED [RANK] DESC;
Resultatet returnerar 4 rader av 7:

Använder nu en UDF-funktion som Mike Kramars:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FRÅN dbo.[Dokument] SOM MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument) ], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;
Resultaten visar hur utdraget fungerar:a <SPAN> taggen injiceras vid det första nyckelordet, och utdraget skärs ut baserat på en förskjutning från den positionen (utan hänsyn till att använda fullständiga ord):

(Återigen, det här är något som kan fixas, men jag vill vara säker på att jag representerar det som finns där ute nu.)
ThinkHighlight
Eran Meyuchas från Interactive Thoughts har utvecklat en komponent som löser många av dessa problem. ThinkHighlight är implementerat som en CLR-sammansättning med två CLR-skalärt värderade funktioner:
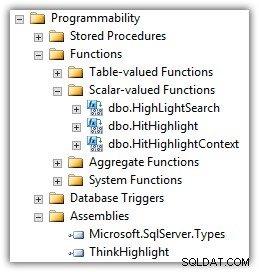
(Du kommer också att se Mike Kramars UDF i listan över funktioner.)
Nu, utan att gå in på alla detaljer om installation och aktivering av assembly på ditt system, här är hur ovanstående fråga skulle representeras med ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] AS MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') SOM tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Resultaten visar hur de mest relevanta sökorden markeras, och ett utdrag härleds från det som är baserat på hela ord och en förskjutning från termen som markeras:

Några ytterligare fördelar som jag inte har visat här inkluderar möjligheten att välja olika sammanfattningsstrategier, styra presentationen av varje nyckelord (snarare än alla) med unik CSS, samt stöd för flera språk och till och med dokument i binärt format (de flesta IFilters stöds).
Prestanda resultat
Inledningsvis testade jag runtime-statistiken för de tre frågorna med SQL Sentry Plan Explorer, mot tabellen med 7 rader. Resultaten var:

Därefter ville jag se hur de skulle jämföras med en mycket större datastorlek. Jag infogade tabellen i sig själv tills jag hade 4 000 rader och körde sedan följande fråga:
STÄLL IN STATISTIK TID PÅ;GO SELECT /* FTS */ d.Titel, d.[Innehåll]FRÅN dbo.[Dokument] AS d INNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:fet', 100)FRÅN dbo.[Dokument] AS MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] AS MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;GO
Jag övervakade också sys.dm_exec_memory_grants medan frågorna kördes, för att fånga upp eventuella avvikelser i minnesanslag. Resultat med i genomsnitt över 10 körningar:
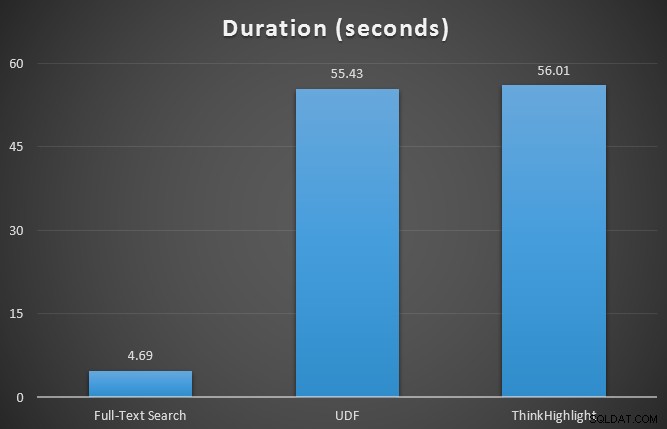
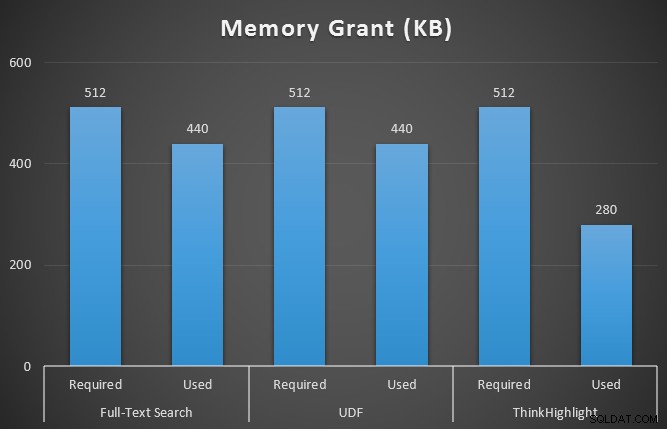
Även om båda alternativen för träff-markering medför en betydande straff för att inte markera alls, representerar ThinkHighlight-lösningen – med mer flexibla alternativ – en mycket marginell inkrementell kostnad i termer av varaktighet (~1 %), samtidigt som den använder betydligt mindre minne (36 %) än UDF-varianten.
Slutsats
Det borde inte komma som en överraskning att hithighlighting är en dyr operation, och baserat på komplexiteten i vad som måste stödjas (tänk flera språk), att det finns väldigt få lösningar där ute. Jag tycker att Mike Kramar har gjort ett utmärkt jobb med att ta fram en baslinje UDF som ger dig ett bra sätt att lösa problemet, men jag blev positivt överraskad över att hitta ett mer robust kommersiellt erbjudande – och fann att det var mycket stabilt, även i betaform. Jag planerar att utföra mer grundliga tester med ett bredare utbud av dokumentstorlekar och -typer. Under tiden, om träffmarkering är en del av dina applikationskrav, bör du prova Mike Kramars UDF och överväga att ta ThinkHighlight för en provkörning.