En investering i kunskap ger bäst ränta.
Benjamin Franklin
I den moderna världen är utbildning allestädes närvarande. Nu mer än någonsin tidigare spelar den en viktig roll i vårt samhälle. Det är faktiskt så viktigt att många av oss fortsätter vår utbildning väl efter att ha avslutat skolan eller college.
Vi har alla hört talas om livslångt lärande, icke-formell utbildning och workshops för alla åldrar. Dessa metoder skiljer sig från formell utbildning på många sätt, men de har också saker gemensamt. Det finns klasser, lektioner, lärare och elever. Och precis som i en traditionell miljö vill vi hålla reda på klassschemat, närvarodata och instruktörens eller elevernas prestationer. Hur kan vi designa en databas för att möta dessa behov? Det är vad vi kommer att ta upp i den här artikeln.
Vi presenterar vår utbildningsdatabasmodell
Modellen som presenteras i den här artikeln gör det möjligt för oss att lagra data om:
- klasser/föreläsningar
- instruktörer/föreläsare
- studenter
- föreläsningsnärvaro
- studenternas/föreläsarnas prestationer
Vi skulle också kunna använda den här modellen som ett schema för skolan, för andra gruppaktiviteter (simlektioner, dansverkstäder) eller till och med för en-mot-en-aktiviteter som handledning. Det finns fortfarande mycket utrymme för förbättringar, som att lagra klassplatsdata eller workshopens varaktighet; vi kommer att täcka dessa i kommande artiklar.
Låt oss komma igång med våra grundläggande utbildningsdatabaselement:tabellerna.
De tre stora:elev-, instruktörs- och klassbord
student , instructor och class tabeller utgör kärnan i vår databas.
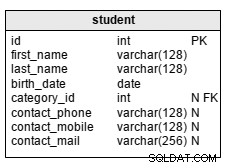
student Tabellen, som visas ovan, används för att lagra grundläggande data om elever, men den kan utökas efter specifika behov. Med undantag för de tre kontaktattributen krävs alla attribut i tabellen:
first_name– elevens namnlast_name– elevens efternamnbirth_date– elevens födelsedatumcontact_phone– elevens telefonnummercontact_mobile– elevens mobiltelefonnummercontact_mail– elevens e-postadresscategory_id– är en referens tillcategorykatalog. Med den här strukturen är vi begränsade till endast en kategori per elev. Det fungerar i de flesta fall, men i vissa situationer kan vi behöva utrymme för att lista flera kategorier. Som du kan se lägger du till en många-till-många-relation som förbinderstudenttabell medcategoryordbok löser detta problem. I det här scenariot måste vi dock skriva mer komplexa frågor för att hantera vår data.
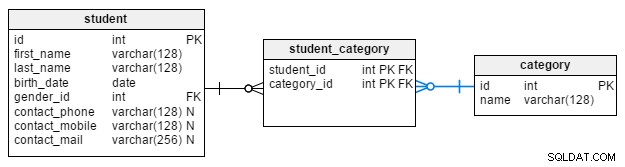
Eftersom vi har nämnt det, låt oss gå vidare och diskutera category tabell här.

Den här tabellen är en ordbok som används för att gruppera elever utifrån vissa kriterier. name attribut är den enda informationen i tabellen (förutom id , primärnyckeln) och det är obligatoriskt. En uppsättning värden som skulle kunna lagras här är studentens anställningsstatus:"student", "anställd", "arbetslös" och "pensionerad". Vi skulle också kunna använda andra uppsättningar baserat på några mycket specifika kriterier, som "gillar yoga", "gillar att vandra", "gillar att cykla" och "tycker inte om någonting".
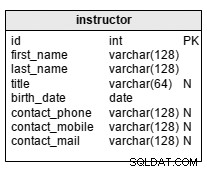
instructor Tabellen innehåller en lista över alla instruktörer/föreläsare i organisationen. Attributen i tabellen är:
first_name– instruktörens namnlast_name– instruktörens efternamntitle– instruktörens titel (om någon)birth_date– instruktörens födelsedatumcontact_phone– instruktörens telefonnummercontact_mobile– instruktörens mobiltelefonnummercontact_mail– instruktörens e-postadress
title och alla tre contact attribut är inte obligatoriska.
student tabell och instructor tabell delar en liknande struktur, men det finns en annan möjlighet att organisera denna information. Ett andra tillvägagångssätt skulle vara att ha en person tabell (som lagrar all personal- och studentdata) och har en många-till-många-relation som talar om för oss alla roller som tilldelats den personen. Den viktigaste fördelen med det andra tillvägagångssättet är att vi bara lagrar data en gång. Om någon är lärare i en klass och elev i en annan, visas de bara en gång i databasen, men med båda rollerna definierade.
Varför valde vi tvåtabellsmetoden för vår utbildningsdatabasmodell? Generellt sett beter sig studenter och instruktörer olika, både i verkligheten och i vår databas. På grund av det kan det vara klokt att lagra deras data separat. Vi kan hitta andra sätt att slå samman informationen om samma person som visas i båda tabellerna (t.ex. ett par infoga/uppdateringsfrågor baserat på ett externt ID, till exempel ett personnummer eller VAT-nummer).
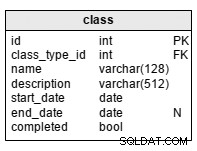
class table är en katalog som innehåller information om alla klasser. Vi kan ha flera instanser av varje klasstyp. Attributen i tabellen är följande (alla är obligatoriska utom end_date). ):
class_type_id– är en referens tillclass_typeordbok.name– är ett kort namn på klassen.description– den här beskrivningen är mer specifik än den iclass_typetabell.start_date– klassens startdatum.end_date– slutdatumet för klassen. Det är inte obligatoriskt eftersom vi kanske inte alltid vet det exakta slutdatumet för varje klass i förväg.completed– är ett booleskt värde som anger om alla planerade klassaktiviteter är avslutade. Detta är praktiskt när vi har nått den planeradeend_timeför en klass men andra klassaktiviteter har ännu inte slutförts.

class_type table är en enkel katalog, avsedd att lagra grundläggande information om föreläsningar eller klasser som erbjuds studenter. Det kan innehålla värden som "engelska språket (grupp)", "polska språket (grupp)", "kroatiska språket (grupp)", "engelska språket (personligt)" eller "danslektioner". Den har bara två obligatoriska attribut – name och description , båda behöver ingen ytterligare förklaring.

class_schedule Tabellen innehåller specifika tider för föreläsningar och klasser. Alla attribut i tabellen är obligatoriska. class_id attribut är en referens till class tabell, medan start_time och end_time är start- och sluttiderna för den specifika föreläsningen.
Vem är här? Närvarorelaterade tabeller

attend Tabellen lagrar information om vilken elev som deltog i vilken klass och det slutliga resultatet. Attributen i tabellen är:
student_id– är en referens tillstudenttabellclass_id– är en referens tillclasstabellclass_enrollment_date– är det datum då eleven började gå den klassenclass_drop_date– det datum då eleven slutade klassen. Det här attributet ska endast ha ett värde om eleven hoppade av klassen före klassens slutdatum. I så fall,drop_class_reason_idattributvärdet måste också anges.drop_class_reason_id– är en referens tilldrop_class_reasontabellattendance_outcome_id– är en referens tillattendance_outcometabell
All data utom class_drop_date och drop_class_reason_id krävs. Dessa två kommer att fyllas i om och endast om en elev hoppar av klassen.

drop_attendance_reason tabellen är en ordbok som innehåller de olika anledningarna till varför en student kan hoppa av en kurs. Den har bara ett attribut, reason_text , och det är obligatoriskt. Ett exempel på värden kan vara:"sjukdom", "tappat intresse", "har inte tillräckligt med tid" och "andra orsaker".

attendance_outcome Tabellen innehåller beskrivningar av studentaktivitet i en viss kurs. outcome_text är det enda attributet i tabellen och det är obligatoriskt. En uppsättning möjliga värden är:"pågår", "slutfört framgångsrikt", "avslutat delvis" och "har inte slutfört klassen".
Vem bestämmer? Undervisningsrelaterade tabeller
teach , drop_teach_reason och teach_outcome tabeller använder samma logik som attend , drop_attendance_reason och attendance_outcome tabeller. Alla dessa tabeller lagrar data om lärares kursrelaterade aktiviteter.
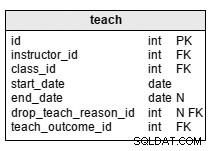
teach Tabell används för att lagra information om vilken lärare som undervisar i vilken klass. Attributen i tabellen är:
instructor_id– är en referens tillinstructortabell.class_id– är en referens tillclasstabell.start_date– är det datum då instruktören började arbeta på den klassen.end_date– är det datum då instruktören slutade arbeta på den klassen. Det är inte obligatoriskt eftersom vi inte kan veta i förväg om instruktören kommer att undervisa till klassens slutdatum.drop_teach_reason_id– är en referens tilldrop_teach_reasontabell. Det är inte obligatoriskt eftersom instruktören kanske inte hoppar av klassen.teach_outcome_id– är en referens tillteach_outcome_reasontabell.

drop_teach_reason tabellen är en enkel ordbok. Den innehåller en uppsättning möjliga förklaringar till varför instruktören avslutade undervisningen före slutdatumet. Det finns bara ett obligatoriskt attribut:reason_text . Detta kan vara "sjukdom", "flyttad till annat projekt/jobb", "sluta" eller "annan anledning".

teach_outcome Tabellen beskriver instruktörens framgång på en viss kurs. outcome_text är tabellens enda attribut och det är obligatoriskt. Möjliga värden för den här tabellen kan vara:"pågår", "slutfört framgångsrikt", "avslutat delvis" och "har inte slutfört undervisningsklassen".

student_presence Tabell används för att lagra data om studentnärvaro för en specifik föreläsning. Vi kan anta att läraren för varje föreläsning noterar närvaro och/eller frånvaro för alla studenter. Attributen i tabellen är:
student_id– är en referens tillstudenttabellclass_schedule_id– är en referens tillclass_scheduletabellpresent– är en boolesk markering om studenten är närvarande på föreläsningen eller inte
Vi skulle kunna övervaka elevernas närvaro i en specifik klass med en fråga som den som följer (förutsatt att @id_class innehåller det klass-id vi vill ha).
SELECT a.id, CONCAT(a.first_name, ' ', a.efter_name) AS student_name, a.number_total, CONCAT(CONVERT(a.number_present / a.number_total * 100, DECIMAL(5,2)), '%') AS procent, a.attendance_outcomeFROM(SELECT student.id, student.first_name, student.last_name, SUM(CASE WHEN student_presence.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS number_total, attendance_outcome.outcome_text AS attendance_outcomeFROM class INNER JOIN attend ON class.id =attend.class_id INNER JOIN student ON attend.student_id =student.id VÄNSTER JOIN class_schedule PÅ class_schedule.class_id =student_presenceIN ON =student_presenceIN .id OCH student_presence.class_schedule_id =class_schedule.id VÄNSTER JOIN attendance_outcome ON attendance_outcome.id =attend.attendance_outcome_idWHERE class.id =@id_classGROUP BY student.id, student.first_name, student.come_outcome, attendanceout_outcome.

Tabellen "instructor_närvaro" använder samma logik som tabellen "student_närvaro", men här vill vi fokusera på instruktörerna. Attributen i tabellen är:
instructor_id– är en referens tillinstructortabellclass_schedule_id– är en referens tillclass_scheduletabellpresent– är ett booleskt värde som representerar om läraren är närvarande på föreläsningen eller inte
Vi kan använda frågan nedan för att övervaka instruktörens aktivitet i klassen:
SELECT a.id, CONCAT(a.first_name, ' ', a.efter_name) AS instructor_name, a.number_total, CONCAT(CONVERT(a.number_present / a.number_total * 100, DECIMAL(5,2)), '%') SOM procent, a.teach_outcomeFROM(SELECT instructor.id, instructor.first_name, instructor.last_name, SUM(CASE WHEN instructor_presence.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS antal_total, teach_outcome.outcome_text AS teach_outcomeFROM class INNER JOIN teach ON class.id =teach.class_id INNER JOIN instructor ON teach.instructor_id =instructor.id LEFT JOIN class_schedule ON class_schedule.class_id =JO_preference instructorinstruct. .id OCH instructor_presence.class_schedule_id =class_schedule.id VÄNSTER JOIN teach_outcome PÅ teach_outcome.id =teach.teach_outcome_idWHERE class.id =@id_classGROUP BY instructor.id, instructor.first_name, instructor.com_last_name, instructor.com_lastNu, låt oss avsluta med att diskutera kontaktpersonstabellerna.
Vem kan vi ringa? Kontaktpersonstabeller
I de flesta fall behöver vi inte lagra kontaktinformation för nödsituationer (dvs. kontakta den här personen i händelse av en nödsituation). Men detta förändras när vi undervisar barn. Enligt lag eller sedvänja måste vi ha en kontaktperson för varje barn vi undervisar. I våra modelltabeller –
contact_person,contact_person_typeochcontact_person_student– vi visar hur detta kan göras.
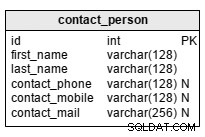
contact_persontabellen är en lista över personer som är relaterade till studenter. Naturligtvis behöver vi inte lista alla släktingar; oftast kommer vi att ha en eller två kontakter per elev. Det här är ett bra sätt att hitta "vem du ska ringa" när eleven behöver eller vill gå tidigt. Attributen i tabellen är:
first_name– är kontaktpersonens namnlast_name– är personens efternamncontact_phone– är personens telefonnummercontact_mobile– är personens mobiltelefonnummercontact_mail– är personens e-postadress
Kontaktuppgifter är inte obligatoriska, även om de är mycket användbara.
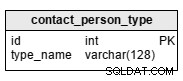
contact_person_type table är en ordbok med ett enda, obligatoriskt attribut:type_name . Exempel på värden som lagras i denna tabell är:"mamma", "far", "bror", "syster" eller "farbror".

contact_person_student tabell är en många-till-många-relation som förbinder kontaktpersoner och deras typ med studenter. Attributen i tabellen är (alla är obligatoriska):
contact_person_id– är en referens tillcontact_persontabellstudent_id– är en referens tillstudenttabellcontact_person_type_id– är en referens tillcontact_person_typetabell
Det kan vara värt att nämna att denna många-till-många-relation kopplar samman tre tabeller. Attributparet contact_person_id och student_id används som alternativ (UNIK) tangent. På så sätt inaktiverar vi dubbletter av poster som förbinder enskilda elever med samma kontaktperson. Attributet contact_person_type_id är inte en del av den alternativa nyckeln. Om så är fallet skulle vi kunna ha flera relationer för samma kontaktperson och samma student (med olika typer av relationer), och det är ingen mening i verkliga situationer.
Modellen som presenteras i denna artikel bör kunna täcka de flesta vanliga behov. Ändå skulle delar av modellen kunna uteslutas i vissa fall, t.ex. vi skulle förmodligen inte behöva hela kontaktpersonssegmentet om våra elever är vuxna. Som jag sa tidigare kommer vi att lägga till förbättringar till detta med tiden. Lägg gärna till förslag och dela dina erfarenheter i diskussionssektionerna.