Det finns många användningsfall för att generera en sekvens av värden i SQL Server. Jag pratar inte om en bestående IDENTITY kolumnen (eller den nya SEQUENCE i SQL Server 2012), utan snarare en övergående uppsättning som endast ska användas under en frågas livstid. Eller till och med de enklaste fallen – som att bara lägga till ett radnummer till varje rad i en resultatuppsättning – som kan innebära att lägga till en ROW_NUMBER() funktion till frågan (eller ännu bättre, i presentationsnivån, som ändå måste gå igenom resultaten rad för rad).
Jag pratar om lite mer komplicerade fall. Du kan till exempel ha en rapport som visar försäljning efter datum. En typisk fråga kan vara:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Problemet med den här frågan är att om det inte finns några beställningar en viss dag, kommer det inte att finnas någon rad för den dagen. Detta kan leda till förvirring, vilseledande data eller till och med felaktiga beräkningar (tänk dagliga medelvärden) för nedströmskonsumenterna av data.
Så det finns ett behov av att fylla dessa luckor med datum som inte finns i data. Och ibland stoppar människor in sin data i en #temp-tabell och använder en WHILE slinga eller en markör för att fylla i de saknade datumen en i taget. Jag kommer inte att visa den koden här eftersom jag inte vill förespråka dess användning, men jag har sett den överallt.
Innan vi går för djupt in på datum, låt oss dock först prata om siffror, eftersom du alltid kan använda en sekvens av siffror för att härleda en sekvens av datum.
Siffertabell
Jag har länge varit en förespråkare för att lagra en extra "nummertabell" på disk (och, för den delen, en kalendertabell också).
Här är ett sätt att skapa en enkel taltabell med 1 000 000 värden:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Varför MAXDOP 1? Se Paul Whites blogginlägg och hans Connect-objekt som rör radmål.
Men många människor är emot tillvägagångssättet med hjälpbord. Deras argument:varför lagra all denna data på disken (och i minnet) när de kan generera data direkt? Min motsats är att vara realistisk och tänka på vad du optimerar; beräkning kan vara dyrt, och är du säker på att det alltid kommer att bli billigare att beräkna ett antal siffror i farten? När det gäller utrymme tar Numbers-tabellen bara upp cirka 11 MB komprimerat och 17 MB okomprimerat. Och om tabellen refereras tillräckligt ofta bör den alltid finnas i minnet, vilket gör åtkomsten snabb.
Låt oss ta en titt på några exempel och några av de vanligaste metoderna som används för att tillfredsställa dem. Jag hoppas att vi alla kan vara överens om att vi, även vid 1 000 värden, inte vill lösa dessa problem med en loop eller en markör.
Genererar en sekvens med 1 000 nummer
Börja enkelt, låt oss generera en uppsättning siffror från 1 till 1 000.
Siffertabell
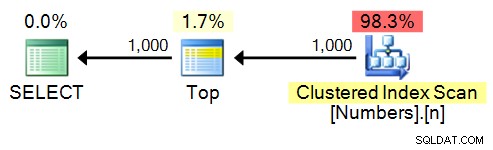
Naturligtvis med en siffertabell är denna uppgift ganska enkel:
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
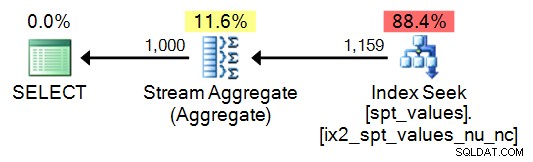
Detta är en tabell som används av interna lagrade procedurer för olika ändamål. Dess användning online verkar vara ganska utbredd, även om den är odokumenterad, saknar stöd, kan den försvinna en dag, och eftersom den bara innehåller en ändlig, icke-unik och icke sammanhängande uppsättning värden. Det finns 2 164 unika och 2 508 totala värden i SQL Server 2008 R2; 2012 finns det 2 167 unika och 2 515 totalt. Detta inkluderar dubbletter, negativa värden och även om du använder DISTINCT , massor av luckor när du väl kommer över siffran 2 048. Så lösningen är att använda ROW_NUMBER() för att generera en sammanhängande sekvens, med början på 1, baserat på värdena i tabellen.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plan:

Som sagt, för bara 1 000 värden kan du skriva en något enklare fråga för att generera samma sekvens:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Detta leder till en enklare plan, naturligtvis, men går sönder ganska snabbt (när din sekvens måste vara mer än 2 048 rader):
Jag rekommenderar i alla fall inte användningen av denna tabell; Jag inkluderar det i jämförelsesyfte, bara för att jag vet hur mycket av detta som finns där ute och hur frestande det kan vara att bara återanvända kod du stöter på.
sys.all_objects
Ett annat tillvägagångssätt som har varit en av mina favoriter genom åren är att använda sys.all_objects . Som spt_values , det finns inget tillförlitligt sätt att generera en sammanhängande sekvens direkt, och vi har samma problem när det gäller en ändlig uppsättning (knappt 2 000 rader i SQL Server 2008 R2 och drygt 2 000 rader i SQL Server 2012), men för 1 000 rader vi kan använda samma ROW_NUMBER() lura. Anledningen till att jag gillar det här tillvägagångssättet är att (a) det finns mindre oro för att den här vyn kommer att försvinna när som helst snart, (b) själva vyn är dokumenterad och stöds, och (c) den kommer att köras på vilken databas som helst på vilken version som helst sedan SQL Server 2005 utan att behöva passera databasgränser (inklusive inneslutna databaser).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Stackade CTE
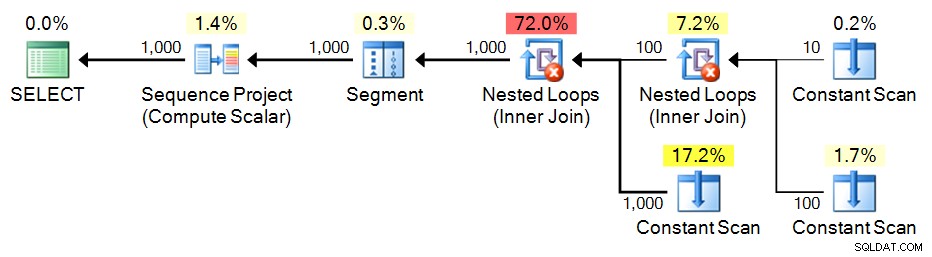
Jag tror att Itzik Ben-Gan förtjänar den ultimata äran för detta tillvägagångssätt; i princip konstruerar du en CTE med en liten uppsättning värden, sedan skapar du den kartesiska produkten mot sig själv för att generera det antal rader du behöver. Och återigen, istället för att försöka generera en sammanhängande uppsättning som en del av den underliggande frågan, kan vi bara använda ROW_NUMBER() till det slutliga resultatet.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plan:
Rekursiv CTE
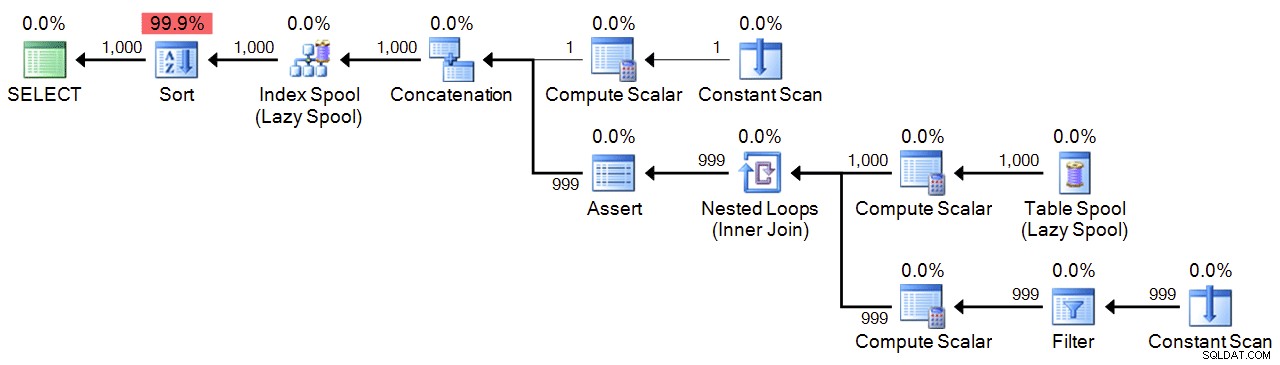
Slutligen har vi en rekursiv CTE, som använder 1 som ankare, och lägger till 1 tills vi når maximalt. För säkerhets skull anger jag maxvärdet i både WHERE sats i den rekursiva delen och i MAXRECURSION miljö. Beroende på hur många nummer du behöver kan du behöva ställa in MAXRECURSION till 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plan:
Prestanda
Naturligtvis med 1 000 värden är skillnaderna i prestanda försumbara, men det kan vara användbart att se hur dessa olika alternativ presterar:
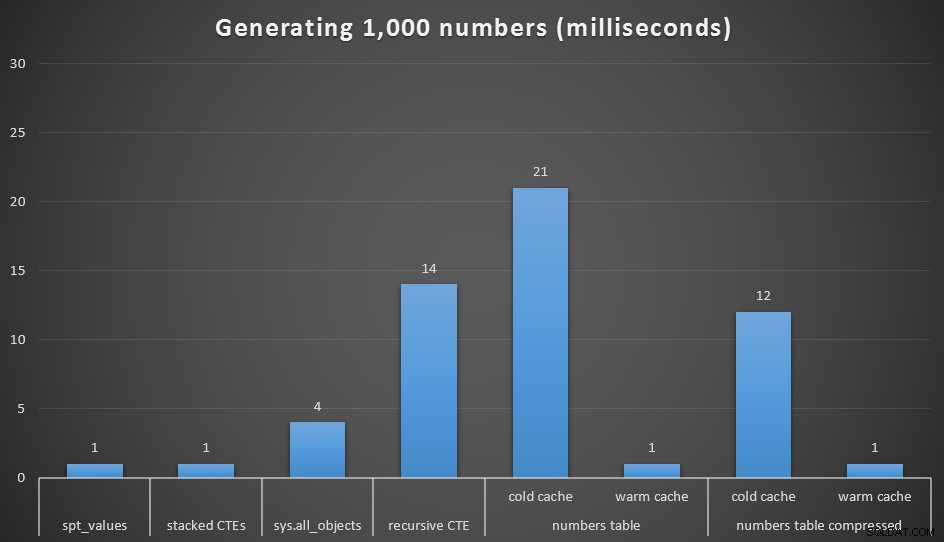
Körtid, i millisekunder, för att generera 1 000 sammanhängande tal
Jag körde varje fråga 20 gånger och tog genomsnittliga körtider. Jag testade också dbo.Numbers tabell, i både komprimerade och okomprimerade format, och med både en kall cache och en varm cache. Med en varm cache konkurrerar den mycket nära de andra snabbaste alternativen som finns (spt_values , rekommenderas inte, och staplade CTEs), men den första träffen är relativt dyr (även om jag nästan skrattar när jag kallar det så).
Fortsättning följer...
Om detta är ditt typiska användningsfall och du inte vågar dig långt över 1 000 rader, så hoppas jag att jag har visat de snabbaste sätten att generera dessa siffror. Om ditt användningsfall är ett större antal, eller om du letar efter lösningar för att generera sekvenser av datum, håll utkik. Senare i den här serien kommer jag att utforska sekvenser med 50 000 och 1 000 000 nummer och datumintervall från en vecka till ett år.
[ Del 1 | Del 2 | Del 3 ]