I februari skrev jag ett blogginlägg om Automatic Plan Correction i SQL Server, och i det här inlägget vill jag prata om Automatic Index Management, den andra komponenten i funktionen Automatic Tuning. Automatisk indexhantering är endast tillgänglig i Azure SQL Database, och den finns för närvarande inte på färdplanen för att vara tillgänglig i nästa version av SQL Server på plats. Det här alternativet är aktiverat oberoende av Automatisk plankorrigering, och som namnet antyder kommer det att hantera index i din databas. Specifikt kan det skapa index som saknas, och det kan ta bort index som inte används, och de som är dubbletter. Låt oss ta en titt på hur detta sker.
Under täcket
Automatisk indexhantering förlitar sig på data för att fatta sitt beslut. För potentiellt indexskapande använder den information som saknas index DMV och spårar den över tid och kombinerar denna data med en intern modell för att bestämma fördelen med indexet. Den använder också Query Store för att avgöra om indexet ger fördelar, så det måste vara aktiverat för databasen, precis som med Automatisk plankorrigering. När det gäller att ta bort index används data från indexanvändningen DMV (sys.dm_db_index_usage_stats) samt indexmetadata (t.ex. antal kolumner, kolumndatatyper).
Aktivera automatisk indexhantering
Som nämnts måste Query Store vara aktiverat för databasen. Detta kan göras i SSMS, med T-SQL och med REST API för Azure SQL Database. Observera att Query Store är aktiverat som standard för databaser i Azure och har varit det sedan 2016 Q4.
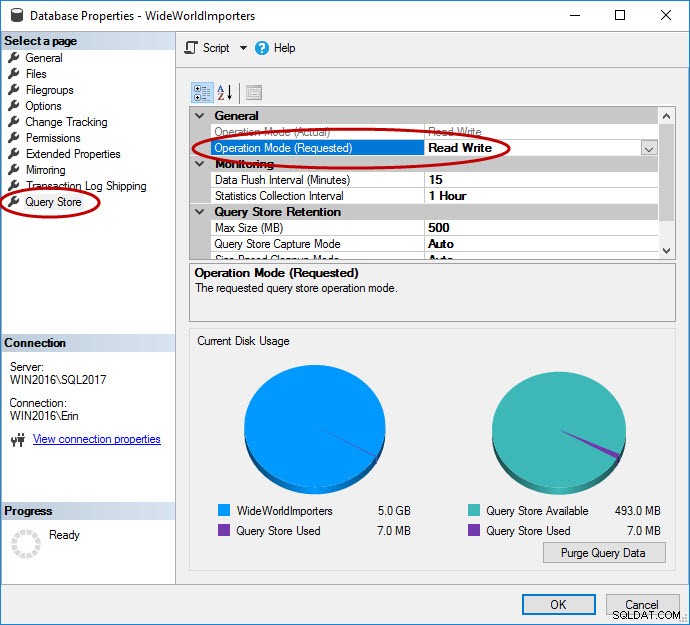
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
När Query Store är aktiverat kan du använda Azure Portal, T-SQL eller EST API för att aktivera automatisk indexhantering i Azure SQL Database (C# och PowerShell är under arbete).
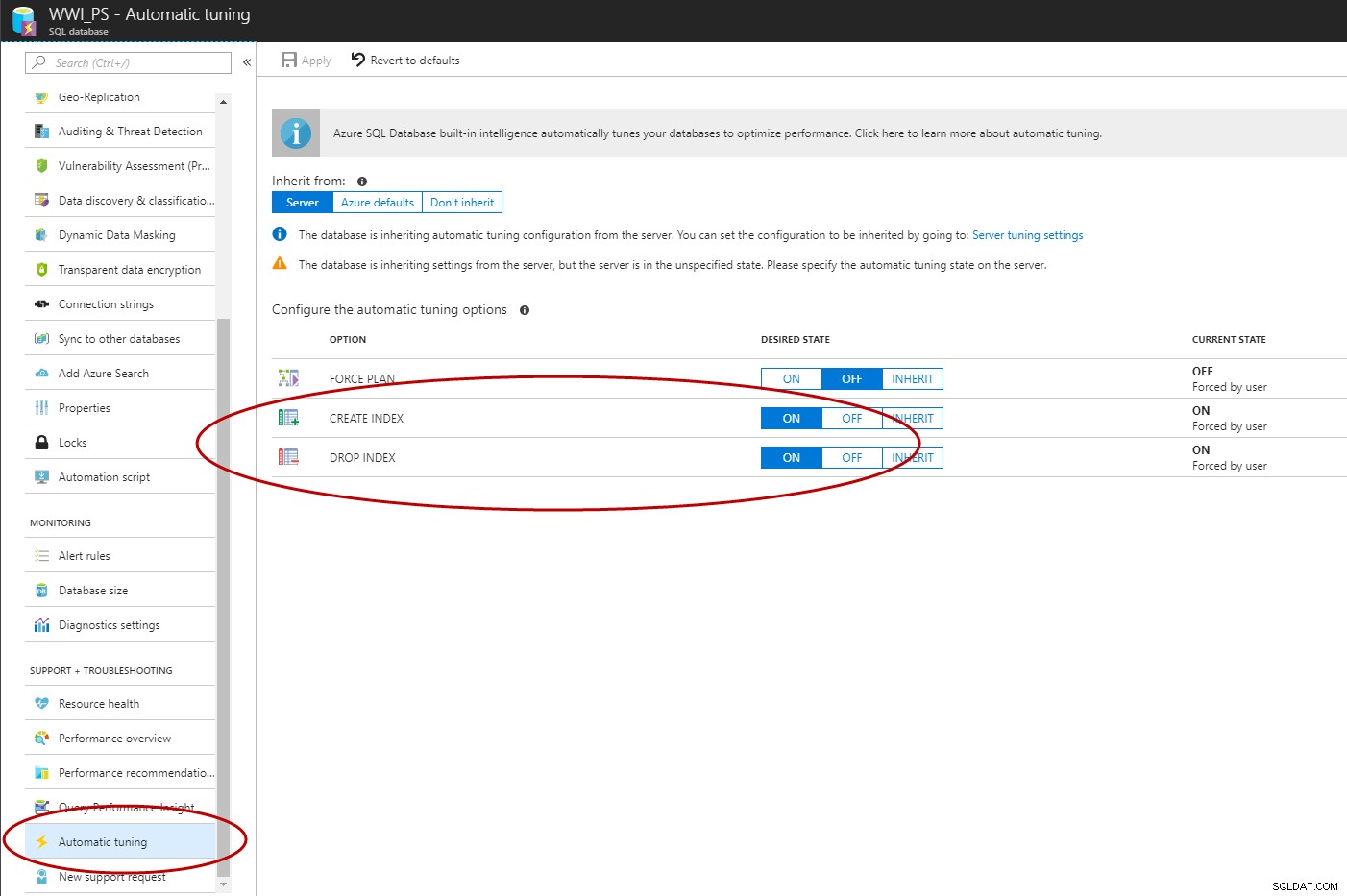
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
Automatisk indexhantering kommer att aktiveras som standard för nya databaser i Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) inom en snar framtid. Från och med januari 2018 startade Microsoft utrullningen för att aktivera automatisk justering för Azure SQL-databaser som inte redan hade det aktiverat, med meddelanden skickade till administratörer så att alternativet kan inaktiveras om så önskas. Denna process tar flera månader, så om du inte har fått ett meddelande ännu, få inte panik!
Hur det fungerar
För att skapa index finns det för närvarande ett rullande fönster på sju (7) dagar* över vilket data spåras, och modellen behöver minst nio (9) timmar* med data för att rekommendera ett index, tillsammans med med 12 timmar* av data i Query Store som kommer att användas som baslinje. Om det fastställs att ett index kommer att ge betydande fördelar kommer SQL Server att skapa indexet.
*Dessa värden kan ändras i framtiden, allt eftersom modellen utvecklas.
Notera:för närvarande slår modellen samman rekommendationer. Det vill säga, om flera index rekommenderas för en tabell, men ett index kan skapas för att täcka alla alternativ, kan det skapa det indexet för närvarande. Men modellen är för närvarande inte tillräckligt intelligent för att slå samman ett rekommenderat index med ett som redan finns.
När ett index har skapats, verifierar SQL Server att det ger fördelar med hjälp av Query Store (det måste alltså vara aktiverat för databasen). Den övervakar prestandan för alla frågor som använder det nya indexet och jämför processorn för frågan innan indexet lades till och när indexet används. Om det finns en regression i frågeprestanda som ett resultat av indexet kommer det att återställa (släppa) indexet. SQL Server övervakar frågeprestanda i upp till tre (3) dagar, eller tills 100 % av den relevanta arbetsbelastningen har analyserats. Efter den tidsperioden, om indexet inte visar några tecken på regression, kommer det inte att granska prestanda för det igen.
Förstå att om Automatic Index Management skapar ett index och sedan två månader senare din arbetsbelastning ändras och det skulle dra nytta av samma index som skapats automatiskt tidigare men med ytterligare en kolumn, så kommer SQL Server för närvarande att skapa ett nytt index. För närvarande finns det ingen logik för att ändra ett befintligt automatiskt skapat index, men den funktionen finns på färdplanen för funktionen.
När det gäller att ta bort index, om ett index inte har några sökningar eller skanningar på 90 dagar, men har en underhållskostnad (vilket innebär att det finns infogningar, uppdateringar eller borttagningar) så kommer det att tas bort. Dubbletter av index kommer också att tas bort, förutsatt att de är en exakt dubblett (och schemat används för att avgöra om index är exakt samma). Om det finns dubbletter av index i termer av nyckelkolumner och inkluderade kolumner (om relevant) men en eller flera av dem har ett filter, är de inte riktigt dubbletter och inga index kommer att tas bort.
Som referens finns det två gånger så många DROP INDEX-rekommendationer i Azure SQL Database som det finns CREATE INDEX-rekommendationer.
När du aktiverar alternativet DROP INDEX kommer SQL Server att släppa användarskapade index. När du aktiverar alternativet SKAPA INDEX, har SQL Server möjligheten att skapa index automatiskt och kan även ta bort dessa index (men kommer inte att släppa användarskapade index). Slutligen skapas och släpps index under tider då arbetsbelastningen inte är hög, vilket bestäms av DTU. Om arbetsbelastningen är över 80 % DTU, väntar SQL Server med att skapa eller släppa indexet tills systembelastningen minskar.
Kommer jag verkligen att låta SQL Server ha kontroll?
Kanske. Min rekommendation om den här funktionen kräver till en början en "lita på men verifiera"-metoden.
Precis som med Automatic Plan Correction har Automatic Index Management utvecklats med en betydande mängd data som hämtats från nästan två miljoner Azure SQL-databaser. Funktionen för automatisk indexhantering har varit tillgänglig i Azure SQL Database sedan första kvartalet 2016, som en del av Index Advisor.
Algoritmerna som används av funktionen har utvecklats och fortsätter att utvecklas över tiden, eftersom fler databaser använder den och mer data samlas in och analyseras. Det finns dock vissa begränsningar för närvarande.
- Indexrekommendationer utvärderas inte mot befintliga index, så indexkonsolidering mellan nya och befintliga index är för närvarande inte tillgänglig.
- Om ett index skulle ge fördelar för en SELECT, är omkostnaden för ändringar på grund av INSERTs, UPDATES och DELETEs inte känd före skapandet. SQL Server övervakar denna overhead under verifieringsprocessen, efter att indexet har implementerats.
Det finns fördelar med automatisk indexhantering som är värda att säga:
- För alla som måste hantera en SQL Server-databas, men inte är en DBA, kan indexrekommendationer vara oerhört användbara.
- Indexrekommendationer fångas i sys.dm_db_tuning_recommendations DMV även om alternativen CREATE och DROP index inte är aktiverade. Därför, om du är osäker på de ändringar som SQL Server kan göra, kan du granska vad som finns i DMV och sedan fatta ett beslut om att manuellt implementera rekommendationen.
Obs:Om du implementerar rekommendationen manuellt utför SQL Server ingen validering. Om du implementerar rekommendationen via portalen (med hjälp av knappen Apply) eller REST API, kommer den att exekveras som om det vore en automatisk åtgärd, och validering kommer att utföras (och indexet kan automatiskt återställas om det finns en regression).
- Funktionen fortsätter att förbättras. Som jag har sagt tidigare försöker Microsoft inte koda DBA:er eller utvecklare utan jobb, det försöker ta itu med den lågt hängande frukten så att du har mer tid för de uppgifter och projekt som inte kan automatiseras intelligent.
Sammanfattning
Om du inte är redo att lämna över tyglarna på indexförvaltningen så förstår jag. Men om du som minimum har en Azure SQL-databas bör du kontrollera sys.dm_db_tuning_recommendations DMV regelbundet för att se vad SQL Server rekommenderar, och jämföra det med data som du eller ditt tredjepartsövervakningsverktyg kan fånga om indexanvändning. När allt kommer omkring, när var sista gången du gjorde en fullständig och grundlig granskning av dina index för att förstå vad som saknas, vad som verkligen används och vad som helt enkelt genererar overhead i databasen?