Introduktion
I SQL Server 2012 kunde grupperad (vektor) aggregering använda parallell körning i batchläge, men bara för partiell (per tråd) aggregat. Det associerade globala aggregatet kördes alltid i radläge, efter en Ompartitionsströmmar utbyte.
SQL Server 2014 lade till möjligheten att utföra parallell grupperad aggregering i batchläge inom ett enda Hash Match Aggregate operatör. Detta eliminerade onödig radlägesbearbetning och tog bort behovet av ett utbyte.
SQL Server 2016 introducerade seriell batchlägesbearbetning och aggregerad pushdown . När pushdown är framgångsrik utförs aggregering inom Columnstore Scan operatören själv, möjligen att arbeta direkt på komprimerad data och dra fördel av SIMD CPU-instruktioner.
De prestandaförbättringar som är möjliga med aggregerad pushdown kan vara mycket betydande. Dokumentationen listar några av de villkor som krävs för att uppnå pushdown, men det finns fall där avsaknaden av "lokalt aggregerade rader" inte kan förklaras helt utifrån dessa detaljer.
Den här artikeln tar upp ytterligare faktorer som påverkar sammanlagd pushdown för GROUP BY endast frågor . Skalär sammanlagd pushdown (aggregation utan en GROUP BY klausul), filter pushdown och expression pushdown kan täckas i ett framtida inlägg.
Columnstore-lagring
Det första man kan säga är att aggregerad pushdown endast gäller för komprimerad data, så rader i ett deltalager är inte berättigade. Utöver det kan pushdown bero på vilken typ av komprimering som används. För att förstå detta är det nödvändigt att först granska hur columnstore-lagring fungerar på en hög nivå:
En komprimerad radgrupp innehåller ett kolumnsegment för varje kolumn. De råa kolumnvärdena är kodade i ett 4-byte eller 8-byte heltal med värde eller ordbok kodning.
Värdekodning kan minska antalet bitar som krävs för lagring genom att översätta råvärden med hjälp av en basoffset och magnitudmodifierare. Till exempel kan värdena {1100, 1200, 1300} lagras som (0, 1, 2) genom att först skala med en faktor 0,01 för att ge {11, 12, 13} och sedan basera om vid 11 för att ge {0, 1, 2}.
Ordbokskodning används när det finns dubbletter av värden. Den kan användas med icke-numeriska data. Varje unikt värde lagras i en ordbok och tilldelas ett heltals-id. Segmentdata refererar sedan till id-nummer i ordboken istället för de ursprungliga värdena.
Efter kodning kan segmentdata komprimeras ytterligare med hjälp av run-length encoding (RLE) och bitpackning:
RLE ersätter upprepade element med data och antalet upprepningar, till exempel {1, 1, 1, 1, 1, 2, 2, 2} skulle kunna ersättas med {5×1, 3×2}. RLE-utrymmesbesparingar ökar med längden på de upprepade körningarna. Korta löpturer kan vara kontraproduktivt.
Bitpackning lagrar den binära formen av datan i ett så smalt gemensamt fönster som möjligt. Till exempel lagras talen {7, 9, 15} i binära (single-byte för mellanslag) heltal som {00000111, 00001001, 00001111}. Att packa dessa bitar i ett fast fyra-bitars fönster ger strömmen {011110011111}. Att veta att det finns en fast fönsterstorlek betyder att det inte finns något behov av en avgränsare.
Kodning och komprimering är separata steg, så RLE och bitpackning tillämpas på resultatet av värdekodning eller ordbokskodning av rådata. Vidare kan data inom samma kolumnsegment ha en blandning av RLE och bitpackningskompression. RLE-komprimerad data kallas ren , och bitpackade komprimerade data kallas oren . Ett kolumnsegment kan innehålla både ren och oren data.
De utrymmesbesparingar som kan uppnås genom kodning och komprimering kan bero på beställning. Alla kolumnsegment inom en radgrupp måste implicit sorteras på samma sätt så att SQL Server effektivt kan rekonstruera kompletta rader från kolumnsegmenten. Att veta att rad 123 är lagrad på samma position (123) i varje kolumnsegment innebär att radnumret inte behöver lagras.
En nackdel med detta arrangemang är att en vanlig sorteringsordning måste väljas för alla kolumnsegment i en radgrupp. En viss ordning kan passa en kolumn mycket bra, men missar betydande möjligheter i andra kolumner. Detta är tydligast fallet med RLE-komprimering. SQL Server använder Vertipaq-teknik för att bestämma ett bra sätt att sortera kolumner i varje radgrupp för att ge ett bra övergripande komprimeringsresultat.
SQL Server använder för närvarande bara RLE inom ett kolumnsegment när det finns minst 64 sammanhängande återkommande värden. De återstående värdena i segmentet är bitpackade. Som nämnts beror huruvida upprepade värden visas som sammanhängande i ett kolumnsegment på den ordning som valts för radgruppen.
SQL Server stöder specialiserad SIMD bitsuppackning för bitsbredder från 1 till 10 inklusive, 12 och 21 bitar. SQL Server kan även använda standard heltalsstorlekar t.ex. 16, 32 och 64 bitar med bitspackning. Dessa nummer är valda för att de passar bra i en 64-bitars enhet. Till exempel kan en enhet innehålla tre 21-bitars underenheter eller 5 12-bitars underenheter. SQL Server inte korsa en 64-bitars gräns när bitar packas.
SIMD använder 256-bitarsregister när processorn stöder AVX2-instruktioner och 128-bitarsregister när SSE4.2-instruktioner är tillgängliga. Annars kan icke-SIMD-uppackning användas.
Grupperade sammanlagda pushdown-villkor
De flesta planer med ett Hash Match Aggregate operatör direkt ovanför en Columnstore Scan operatören kommer potentiellt att kvalificera sig för grupperad sammanlagd pushdown, med förbehåll för de allmänna villkoren som anges i dokumentationen.
Extra filter och uttryck kan ibland läggas till utan att förhindra grupperad aggregerad pushdown. Den allmänna regeln är att filtret eller uttrycket också måste kunna tryckas ned (även om kompatibla uttryck fortfarande kan visas i en separat Compute Scalar ). Som nämnts i inledningen kan dessa aspekter behandlas i detalj i separata artiklar.
Det finns för närvarande inget i utförandeplanerna som indikerar om ett visst aggregat ansågs allmänt kompatibelt med grupperad samlad pushdown eller inte. Ändå, när planen allmänt sett kvalificerar för grupperad samlad pushdown görs både pushdown (snabb) och icke-pushdown (långsam) kodsökvägar tillgängliga.
Varje skanningsutdatabatch (med upp till 900 rader) fattar ett körtidsbeslut mellan snabba och långsamma kodvägar. Denna flexibilitet gör att så många partier som möjligt kan dra nytta av pushdown. I värsta fall kommer inga partier att använda den snabba sökvägen under körning, trots en "allmänt kompatibel" plan.
Exekveringsplanen visar resultatet av snabb-pushdown-bearbetning som 'lokalt aggregerade rader' utan motsvarande radutgång från skanningen. Slow-path-batcher visas som utdatarader från kolumnlagringsskanningen som vanligt, med aggregeringen utförd av en separat operatör istället för vid skanningen.
En enstaka grupperad aggregat- och skanningskombination kan skicka vissa partier längs den snabba vägen och några nedför den långsamma vägen, så det är fullt möjligt att se några, men inte alla, rader lokalt aggregerade. När grupperad sammanlagd pushdown lyckas, innehåller varje utdatabatch från skanningen grupperingsnycklar och en partiell sammanställning som representerar raderna som bidrar.
Detaljerade kontroller
Det finns ett antal körtidskontroller för att avgöra om pushdown-bearbetning kan användas. Bland de lätt dokumenterade kontrollerna finns:
- Det får inte finnas någon möjlighet till samlat spill .
- Alla orena (bitpackade) grupperingsnycklar får vara inte bredare än 10 bitar . Rena (RLE-kodade) grupperingsnycklar behandlas som att de har en oren bredd på noll, så dessa utgör vanligtvis få hinder.
- Pushdown-bearbetning måste fortsätta att betraktas som värt besväret , med hjälp av ett "nyttomått" som uppdateras i slutet av varje utmatningsbatch.
Möjligheten till samlad översvämning bedöms konservativt för varje batch baserat på typen av aggregat, resultatdatatyp, aktuella partiella aggregeringsvärden och information om indata. Till exempel känner SQL Server till lägsta och högsta värden från segmentmetadata som exponeras i DMV sys.column_store_segments . Där det finns risk för översvämning kommer partiet att använda långsam bearbetning. Detta är mest en risk för SUM aggregat.
Begränsningen för oren grupperingsnyckelbredd är värt att betona. Det gäller endast kolumner i GROUP BY klausul som faktiskt används i verkställighetsplanen som grund för gruppering. Dessa uppsättningar är inte alltid exakt samma eftersom optimeraren har frihet att ta bort överflödiga grupperingskolumner, eller att på annat sätt skriva om aggregat, så länge som de slutliga frågeresultaten garanteras matchar den ursprungliga frågespecifikationen. Där det finns en skillnad är det grupperingskolumnerna som visas i genomförandeplanen som är viktiga.
Den större svårigheten är att veta om någon av grupperingskolumnerna lagras med hjälp av bitpackning, och i så fall vilken bredd som användes. Det skulle också vara användbart att veta hur många värden som kodades med RLE. Denna information kan finnas i column_store_segments DMV, men så är det inte idag. Så vitt jag vet finns det inget dokumenterat sätt just nu att få bitpackning och RLE-information från metadata. Det lämnar oss med att leta efter odokumenterade alternativ.
Hitta RLE och bitpackningsinformation
Den odokumenterade DBCC CSINDEX kan ge oss den information vi behöver. Spårningsflagga 3604 måste vara på för att detta kommando ska producera utdata på fliken SSMS-meddelanden. Givet information om kolumnsegmentet vi är intresserade av, returnerar detta kommando:
- Segmentattribut (liknande
column_store_segments) - RLE-information
- Bokmärken till RLE-data
- Bitpacksinformation
Eftersom det är odokumenterat finns det några egenheter (som att behöva lägga till en till kolumn-ID för klustrad kolumnbutik, men inte icke-klustrad kolumnbutik), och till och med ett par mindre fel. Du bör inte använda den på något annat än ett personligt testsystem. Förhoppningsvis kommer en metod som stöds för att komma åt denna data att tillhandahållas i stället.
Exempel
Det bästa sättet att visa DBCC CSINDEX och demonstrera poängen som gjorts hittills i denna text är att arbeta igenom några exempel. Skripten som följer antar att det finns en tabell som heter dbo.Numbers i den aktuella databasen som innehåller heltal från 1 till minst 16 384. Här är ett skript för att skapa min standardversion av den här tabellen med tio miljoner heltal:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Exemplen använder alla samma grundläggande testtabell:Den första kolumnen c1 innehåller ett unikt nummer för varje rad. Den andra kolumnen c2 är fylld med ett antal dubbletter för vart och ett av ett litet antal distinkta värden.
Ett klustrat kolumnlagerindex skapas efter datapopulation så att alla testdata hamnar i en enda komprimerad radgrupp (inget deltalager). Den är byggd för att ersätta ett b-träd klustrade index på kolumn c2 för att uppmuntra VertiPaq-algoritmen att tidigt överväga nyttan av att sortera på den kolumnen. Detta är den grundläggande testinställningen:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
De två variablerna är för antalet distinkta värden som ska infogas i kolumn c2 , och antalet dubbletter för vart och ett av dessa värden.
Testfrågan är en mycket enkel grupperad COUNT_BIG aggregering med kolumn c2 som nyckel:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Columnstore indexinformation kommer att visas med DBCC CSINDEX efter körning av varje testfråga:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Tester kördes på den senaste versionen av SQL Server som var tillgänglig i skrivande stund:Microsoft SQL Server 2017 RTM-CU13-OD build 14.0.3049 Developer Edition (64-bitars) på Windows 10 Pro. Saker och ting borde också fungera bra med den senaste versionen av SQL Server 2016.
Test 1:Pushdown, 9-bitars orena nycklar
Det här testet använder testdatapopulationsskriptet precis som skrivet precis ovan, vilket ger en tabell med 32 256 rader. Kolumn c1 innehåller nummer från 1 till 32 256.
Kolumn c2 innehåller 512 distinkta värden från 0 till 511 inklusive. Varje värde i c2 är duplicerat 63 gånger , men de visas inte som sammanhängande block när de visas i c1 beställa; de cyklar 63 gånger genom värdena 0 till 511.
Med tanke på den föregående diskussionen förväntar vi oss att SQL Server lagrar c2 kolumndata med:
- Ordbokskodning eftersom det finns ett betydande antal dubblerade värden.
- Ingen RLE . Antalet dubbletter (63) per värde når inte tröskeln på 64 som krävs för RLE.
- Bitförpackning storlek 9 . De 512 distinkta ordboksposterna kommer att passa exakt i 9 bitar (2^9 =512). Varje 64-bitars enhet kommer att innehålla upp till sju 9-bitars underenheter.
Allt detta bekräftas som korrekt med DBCC CSINDEX fråga:
Segmentattribut avsnitt av utdata visar ordbokskodning (typ 2; värdena för encodingType finns som dokumenterade på sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511OnDisk />NullValS =37944 RowCount =32256
RLE-avsnittet visar ingen RLE-data , bara en pekare till det bitpackade området och en tom post för värdet noll:
RLE Header:
Lobbtyp =3 RLE-arrayantal (i termer av inbyggda enheter) =2
RLE-arrayinmatningsstorlek =8
RLE-data:
Index =0 Bitpack Array Index =0 Antal =32256
Index =1 Värde =0 Antal =0
Bitpack Data Header avsnittet visar bitpack storlek 9 och 4 608 bitpack-enheter som används:
Bitpack Data Header:
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Bitpacksdata avsnittet visar värdena lagrade i de två första bitpack-enheterna som begärts av de två sista parametrarna till DBCC CSINDEX kommando. Kom ihåg att varje 64-bitars enhet kan innehålla 7 underenheter (numrerade 0 till 6) med 9 bitar vardera (7 x 9 =63 bitar). De 4 608 enheterna har totalt 4 608 * 7 =32 256 rader:
Enhet 0 UnderEnhet 0 =383
Enhet 0 UnderEnhet 1 =255
Enhet 0 UnderEnhet 2 =127
Enhet 0 UnderEnhet 3 =510
Enhet 0 UnderEnhet 4 =381
Unit 0 SubUnit 5 =253
Unit 0 SubUnit 6 =125
Unit 1 SubUnit 0 =508
Unit 1 SubUnit 1 =379
Unit 1 SubUnit 2 =251
Unit 1 SubUnit 3 =123
Unit 1 SubUnit 4 =506
Unit 1 SubUnit 5 =377
Unit 1 SubUnit 6 =249
Eftersom grupperingsnycklarna använder bit-packing med en storlek mindre än eller lika med 10 , förväntar vi oss grupperad sammanlagd pushdown att arbeta här. Faktum är att exekveringsplanen visar att alla rader var lokalt aggregerade vid Columnstore Index Scan operatör:

Planens xml innehåller ActualLocallyAggregatedRows="32256" i körtidsinformationen för indexskanningen.
Test 2:Ingen pushdown, 12-bitars orena nycklar
Detta test ändrar @values parameter till 1025, behåll @dupes vid 63. Detta ger en tabell med 64 575 rader, med 1 025 distinkta värden i kolumn c2 löper från 0 till 1024 inklusive. Varje värde i c2 är duplicerat 63 gånger .
SQL Server lagrar c2 kolumndata med:
- Ordbokskodning eftersom det finns ett betydande antal dubblerade värden.
- Ingen RLE . Antalet dubbletter (63) per värde når inte tröskeln på 64 som krävs för RLE.
- Bitpackad med storlek 12 . De 1 025 distinkta ordboksposterna passar inte riktigt i 10 bitar (2^10 =1 024). De skulle passa i 11 bitar men SQL Server stöder inte den bitpackningsstorleken som tidigare nämnts. Den näst minsta storleken är 12 bitar. Genom att använda 64-bitars enheter med hårda ramar för bitpackning, kunde inte fler 11-bitars underenheter passa i 64 bitar än 12-bitars underenheter skulle. Oavsett vilket kommer 5 underenheter att passa i en 64-bitars enhet.
DBCC CSINDEX output bekräftar ovanstående analys:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024 OnDalize =1024 OnDalize =104400 RowCount =64575
RLE Header:
Lobbtyp =3 RLE-arrayantal (i termer av inbyggda enheter) =2
RLE-arrayinmatningsstorlek =8
RLE-data:
Index =0 Bitpack Array Index =0 Antal =64575
Index =1 Värde =0 Antal =0
Bitpack Data Header:
Bitpack Entry Size =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Bitpack Data:
Enhet 0 UnderEnhet 0 =767
Enhet 0 UnderEnhet 1 =510
Enhet 0 UnderEnhet 2 =254
Enhet 0 UnderEnhet 3 =1021
Enhet 0 UnderEnhet 4 =765
Unit 1 SubUnit 0 =507
Unit 1 SubUnit 1 =250
Unit 1 SubUnit 2 =1019
Unit 1 SubUnit 3 =761
Unit 1 SubUnit 4 =505
Eftersom den orena grupperingsnycklar har en storlek över 10 , förväntar vi oss grupperad sammanlagd pushdown inte arbeta här. Detta bekräftas av exekveringsplanen som visar noll rader lokalt aggregerade vid Columnstore Index Scan operatör:
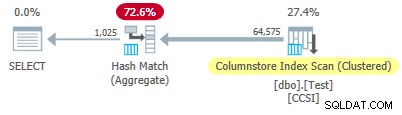
Alla 64 575 rader sänds ut (i partier) av Columnstore Index Scan och aggregeras i batchläge av Hash Match Aggregate operatör. ActualLocallyAggregatedRows attribut saknas i xml-planens körtidsinformation för indexskanningen.
Test 3:Pushdown, Pure Keys
Detta test ändrar @dupes parameter från 63 till 64 för att tillåta RLE. @values parametern ändras till 16 384 (maximalt för att det totala antalet rader fortfarande får plats i en enskild radgrupp). Det exakta antalet som valts för @values är inte viktigt – poängen är att generera 64 dubbletter av varje unikt värde så att RLE kan användas.
SQL Server lagrar c2 kolumndata med:
- Ordbokskodning på grund av de dubblerade värdena.
- RLE. Används för varje distinkt värde eftersom var och en når tröskeln på 64.
- Ingen bitpackad data . Om det fanns några skulle den använda storlek 16. Storlek 12 är inte tillräckligt stor (2^12 =4 096 distinkta värden) och storlek 21 skulle vara slösaktigt. De 16 384 distinkta värdena skulle passa i 14 bitar, men som tidigare får inte fler av dessa plats i en 64-bitars enhet än 16-bitars underenheter.
DBCC CSINDEX utdata bekräftar ovanstående (bara ett fåtal RLE-poster och bokmärken visas av utrymmesskäl):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1638 OnDalS 1638 =131648 RowCount =1048576
RLE Header:
Lobbtyp =3 RLE-arrayantal (i termer av inbyggda enheter) =16385
RLE-arrayinmatningsstorlek =8
RLE-data:
Index =0 Värde =3 Antal =64
Index =1 Värde =1538 Antal =64
Index =2 Värde =3072 Antal =64
Index =3 Värde =4608 Antal =64
Index =4 Värde =6142 Antal =64
…
Index =16381 Värde =8954 Antal =64
Index =16382 Värde =10489 Antal =64
Index =16383 =12025 Antal =64
Index =16384 Värde =0 Antal =0
Bokmärkeshuvud:
Antal bokmärken =65 Bokmärkesavstånd =16384 Bokmärkesstorlek =520
Bokmärksdata:
Position =0 Index =64
Position =512 Index =16448
Position =1024 Index =32832
…
Position =31744 Index =1015872
Position =32256 Index 1032256
Position =32768 Index =1048577
Bitpack Data Header:
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Eftersom grupperingsnycklarna är rena (RLE används), grupperad sammanlagd pushdown förväntas här. Utförandeplanen bekräftar detta genom att visa alla rader lokalt aggregerade vid Columnstore Index Scan operatör:
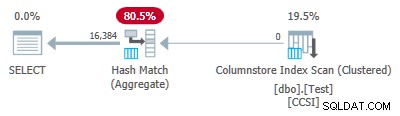
Planens xml innehåller ActualLocallyAggregatedRows="1048576" i körtidsinformationen för indexskanningen.
Test 4:10-bitars orena nycklar
Detta test ställer in @values till 1024 och @dupes till 63, vilket ger en tabell med 64 512 rader, med 1 024 distinkta värden i kolumn c2 med värden från 0 till 1 023 inklusive. Varje värde i c2 är duplicerat 63 gånger .
Det viktigaste , skapas nu det klustrade indexet för b-trädet i kolumn c1 istället för kolumn c2 . Det klustrade kolumnarkivet ersätter fortfarande b-trädets klustrade index. Detta är den ändrade delen av skriptet:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server lagrar c2 kolumndata med:
- Ordbokskodning på grund av dubbletterna.
- Ingen RLE . Antalet dubbletter (63) per värde når inte tröskeln på 64 som krävs för RLE.
- Bitpackning med storlek 10 . De 1 024 distinkta ordboksposterna passar exakt i 10 bitar (2^10 =1 024). Sex underenheter om 10 bitar vardera kan lagras i varje 64-bitars enhet.
DBCC CSINDEX utdata är:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023 OnDalize =1023 OnDalize =87096 RowCount =64512
RLE Header:
Lobbtyp =3 RLE-arrayantal (i termer av inbyggda enheter) =2
RLE-arrayinmatningsstorlek =8
RLE-data:
Index =0 Bitpack Array Index =0 Antal =64512
Index =1 Värde =0 Antal =0
Bitpack Data Header:
Bitpack Entry Size =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Enhet 0 UnderEnhet 0 =766
Enhet 0 UnderEnhet 1 =509
Enhet 0 UnderEnhet 2 =254
Enhet 0 UnderEnhet 3 =1020
Enhet 0 UnderEnhet 4 =764
Enhet 0 SubEnhet 5 =506
Unit 1 SubUnit 0 =250
Unit 1 SubUnit 1 =1018
Unit 1 SubUnit 2 =760
Unit 1 SubUnit 3 =504
Unit 1 SubUnit 4 =247
Unit 1 SubUnit 5 =1014
Eftersom den orena grupperingsnycklar använder en storlek mindre än eller lika med 10, vi förväntar oss grupperad sammanlagd pushdown att arbeta här. Men det är inte vad som händer . Utförandeplanen visar att 54 612 av de 64 512 raderna var aggregerade vid Hash Match Aggregate operatör:
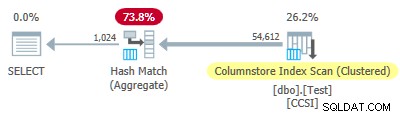
Planens xml innehåller ActualLocallyAggregatedRows="9900" i körtidsinformationen för indexskanningen. Detta innebär grupperad sammanlagd pushdown användes för 9 900 rader, men användes inte för de andra 54 612!
Återkopplingsmekanismen
SQL Server började med grupperad samlad pushdown för den här exekveringen eftersom de orena grupperingsnycklarna uppfyllde kriterierna för 10-bitars eller mindre. Detta varade i totalt 11 satser (med 900 rader vardera =totalt 9 900 rader). Vid den tidpunkten, en återkopplingsmekanism som mäter effektiviteten av grupperad sammanlagd pushdown beslutade att det inte fungerade och stängde av . De återstående partierna bearbetades alla med pushdown inaktiverad.
Återkopplingen jämför i huvudsak antalet aggregerade rader med antalet producerade grupper. Den börjar med ett värde på 100 och justeras i slutet av varje pushdown-utgångsbatch. Om värdet sjunker till 10 eller lägre är pushdown inaktiverad för den aktuella grupperingsoperationen.
’Pushdown-förmånsmåttet’ minskar mer eller mindre beroende på hur dåligt den nedpressade aggregeringssatsningen går. Om det finns färre än 8 rader per grupperingsnyckel i genomsnitt i den utgående batchen, minskas det aktuella förmånsvärdet med 22 %. Om det finns fler än 8 men färre än 16, minskas måttet med 11 %.
Å andra sidan, om saker och ting förbättras, och 16 eller fler rader per grupperingsnyckel sedan påträffas för en utdatabatch, återställs måtten till 100 och fortsätter att justeras när partiella aggregerade batcher produceras av skanningen.
Data i detta test presenterades i en särskilt ohjälpsam ordning för pushdown på grund av det ursprungliga b-tree-klustrade indexet i kolumn c1 . När de presenteras på detta sätt visas värdena i kolumn c2 börjar vid 0 och ökar med 1 tills de når 1 023, sedan startar de cykeln igen. De 1 023 distinkta värdena är mer än tillräckligt för att säkerställa att varje 900-rads utdatabatch endast innehåller en delvis aggregerad rad för varje nyckel. Detta är inte ett lyckligt tillstånd.
Om det hade funnits 64 dubbletter per värde istället för 63, skulle SQL Server ha övervägt att sortera efter c2 samtidigt som kolumnbutiksindexet byggdes, och så producerade RLE-komprimering. Som det är, sparkar 22%-straffet in efter varje batch. Med början på 100 och med samma avrundade heltalsaritmetik, går sekvensen av metriska värden:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Den elfte batchen minskar måtten till 10 eller lägre, och pushdown är inaktiverad. De 11 satserna med 900 rader står för de 9 900 lokalt aggregerade raderna som visas i exekveringsplanen.
Variation med 900 distinkta värden
Samma beteende kan ses i test 4 med så få som 901 distinkta värden, förutsatt att raderna råkar presenteras i samma ohjälpsamma ordning.
Ändra @values parameter till 900 samtidigt som allt annat är oförändrat har en dramatisk effekt på genomförandeplanen:
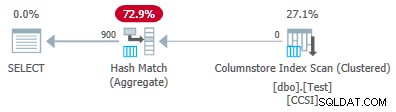
Nu är alla 900 grupper samlade vid skanningen! XML-planens egenskaper visar ActualLocallyAggregatedRows="56700" . Detta eftersom grupperad sammanlagd pushdown upprätthåller 900 grupperingsnycklar och partiella sammanställningar i en enda batch. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Obs! No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.