Nyligen var jag involverad i utvecklingen av funktionaliteten som krävde en snabb och frekvent överföring av stora datamängder till skiva. Dessutom var det meningen att dessa data skulle läsas från disk då och då. Därför var jag avsedd att ta reda på platsen, sättet och medlen för att lagra denna data. I den här artikeln kommer jag kortfattat att gå igenom uppgiften, samt undersöka och jämföra lösningar för att slutföra denna uppgift.
Uppgiftens sammanhang :Jag arbetar i ett team som utvecklar verktyg för relativ databasutveckling (SQL Server, MySQL, Oracle). Verktygssortimentet inkluderar både fristående verktyg och tillägg för MS SSMS.
Uppgift :Återställer dokument som öppnades när IDE stängdes vid nästa start av IDE.
Användning :Att stänga IDE snabbt innan du lämnar kontoret utan att tänka på vilka dokument som sparades och vilka som inte var det. Vid nästa start av IDE måste vi få samma miljö som var vid stängningsögonblicket och fortsätta arbetet. Alla resultat av arbete ska sparas vid orolig nedläggning, t.ex. under kraschar av ett program eller operativsystem, eller under avstängning.
Uppgiftsanalys :Den liknande funktionen finns i webbläsare. Men webbläsare lagrar endast webbadresser som består av cirka 100 symboler. I vårt fall måste vi lagra hela dokumentinnehållet. Därför behöver vi en plats för att spara och lagra användarens dokument. Dessutom arbetar ibland användare med SQL på ett annat sätt än med andra språk. Till exempel, om jag skriver en C#-klass på mer än 1000 rader, kommer det knappast att vara acceptabelt. Medan, i SQL-universumet, tillsammans med 10-20-radsfrågor, finns de monstruösa databasdumparna. Sådana dumpar är knappast redigerbara, vilket innebär att användare föredrar att hålla sina redigeringar säkra.
Krav för ett lagringsutrymme:
- Det bör vara en lätt inbäddad lösning.
- Det ska ha hög skrivhastighet.
- Den bör ha ett alternativ för multibearbetningsåtkomst. Detta krav är inte kritiskt, eftersom vi kan säkerställa åtkomsten med hjälp av synkroniseringsobjekten, men ändå skulle det vara trevligt att ha det här alternativet.
Kandidater
Den första kandidaten är ganska klumpig, det vill säga att lagra allt i en mapp, någonstans i AppData.
Den andra kandidaten är uppenbar – SQLite, en standard för inbäddade databaser. Mycket solid och populär kandidat.
Den tredje kandidaten är LiteDB-databasen. Det är det första resultatet för "inbäddad databas för .net"-frågan i Google.
Första anblicken
Filsystem. Filer är filer, de kräver underhåll och korrekt namngivning. Förutom filinnehållet kommer vi att behöva lagra en liten uppsättning egenskaper (ursprunglig sökväg på skivan, anslutningssträng, version av IDE, där den öppnades). Det betyder att vi antingen måste skapa två filer för ett dokument, eller att uppfinna ett format som skiljer egenskaper från innehåll.
SQLite är en klassisk relationsdatabas. Databasen representeras av en fil på skivan. Denna fil binds med databasschema, varefter vi måste interagera med den med hjälp av SQL-medlen. Vi kommer att kunna skapa 2 tabeller, en för egenskaper och den andra för innehåll – i fall vi behöver använda egenskaper eller innehåll separat.
LiteDB är en icke-relationell databas. I likhet med SQLite representeras databasen av en enda fil. Den är helt skriven i С#. Det har fängslande enkelhet att använda:vi behöver bara ge ett objekt till biblioteket, medan serialisering kommer att utföras på eget sätt.
Prestandatest
Innan jag tillhandahåller kod skulle jag vilja förklara den allmänna uppfattningen och ge jämförelseresultat.
Den allmänna uppfattningen är att jämföra hastigheten för att skriva stora mängder små filer till databasen, genomsnittlig mängd genomsnittliga filer och en liten mängd stora filer. Fallet med genomsnittliga akter är för det mesta nära verkligt fall, medan ärenden med små och stora akter är gränsfall, vilket också måste beaktas.
Jag skrev innehåll till en fil med hjälp av FileStream med standardbuffertstorleken.
Det fanns en nyans i SQLite som jag skulle vilja nämna. Vi kunde inte lägga allt dokumentinnehåll (som jag nämnde ovan, de kan vara riktigt stora) i en databascell. Saken är den att i optimeringssyfte lagrar vi dokumenttext rad för rad. Detta betyder att för att lägga in text i en enda cell måste vi lägga alla dokument på en enda rad, vilket skulle fördubbla mängden av det använda operativsystemet minne. Den andra sidan av problemet skulle avslöja sig under data som läses från databasen. Det är därför det fanns en separat tabell i SQLite, där data lagrades rad för rad och data länkades med hjälp av främmande nyckel med tabellen som endast innehöll filegenskaper. Dessutom lyckades jag snabba upp databasen med batchdatainsättning (flera tusen rader åt gången) i AV-synkroniseringsläget utan loggning och inom en transaktion.
LiteDB tog emot ett objekt med List bland sina egenskaper och biblioteket sparade det på egen skiva.
Under utvecklingen av testapplikationen förstod jag att jag föredrar LiteDB. Saken är att testkoden för SQLite tar mer än 120 rader, medan kod, som löser samma problem i LiteDb, bara tar 20 rader.
Testa datagenerering
FileStrings.cs
intern class FileStrings { private static readonly Random random =new Random(); public List Strings { get; uppsättning; } =ny lista(); public int SomeInfo { get; uppsättning; } public FileStrings() { } public FileStrings(int id, int minLines, decimal lineIncrement) { SomeInfo =id; int lines =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES)) .ToList();
SQLite
privat statisk void SaveToDb(List files) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; anslutning.Öppna(); var kommando =connection.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_numbers_uindexe ); PRAGMA synchronous =OFF;PRAGMA journal_mode =OFF"; command.ExecuteNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT I filer(filnamn) VÄRDEN(?); VÄLJ last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strängar(sträng, fil-id, radnummer) VÄRDEN(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var objekt i filer) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } privat statiskt tomrum SaveToDb(FileStrings-objekt, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =filnamn; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var rad i item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =filId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
privat statisk void SaveToNoSql(Listobjekt) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("filer"); data.EnsureIndex(f => f.SomeInfo); data.Insert(item); } }
Följande tabell visar genomsnittliga resultat för flera körningar av testkoden. Under modifieringar var den statistiska avvikelsen ganska omärklig.
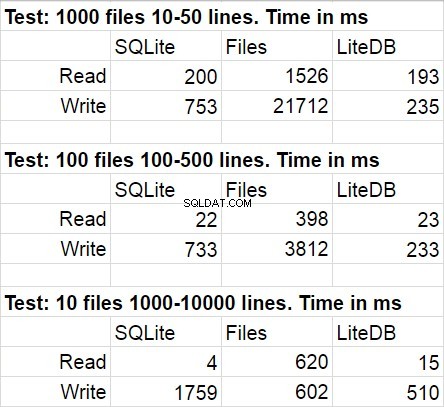
Jag blev inte förvånad över att LiteDB vann i den här jämförelsen. Jag blev dock chockad över att LiteDB vann över filer. Efter en kort studie av biblioteksförrådet fick jag reda på mycket noggrant implementerad paginal skrivning till skiva, men jag är säker på att detta bara är ett av många prestandatrick som används där. En sak till som jag skulle vilja påpeka är att filsystemets åtkomst snabbt minskar när mängden filer i mappen blir riktigt stor.
Vi valde LiteDB för utvecklingen av vår funktion, och vi ångrade knappt detta val. Saken är att biblioteket är skrivet i inbyggt format för alla C#, och om något inte var helt klart kunde vi alltid hänvisa till källkoden.
Nackdelar
Förutom de ovan nämnda fördelarna med LiteDB i jämförelse med dess utmanare, började vi märka nackdelar under utvecklingen. De flesta av dessa nackdelar kan förklaras med "ungdom" på biblioteket. Efter att ha börjat använda biblioteket något utanför gränserna för "standard"-scenariot upptäckte vi flera problem (#419, #420, #483, #496). Bibliotekets författare svarade ganska snabbt på frågor och de flesta problemen löstes snabbt. Nu finns bara en uppgift kvar (förväxla inte med dess stängda status). Detta är en fråga om konkurrenskraftig tillgång. Det verkar som om ett väldigt otäckt race-tillstånd gömmer sig någonstans djupt inne i biblioteket. Vi gick över denna bugg på ett ganska originellt sätt (jag tänker skriva en separat artikel om detta ämne).
Jag skulle också vilja nämna frånvaron av snygg redaktör och tittare. Det finns LiteDBShell, men är bara för riktiga konsolfans.
Sammanfattning
Vi har byggt en stor och viktig funktionalitet över LiteDB, och nu arbetar vi på en annan stor funktion där vi kommer att använda detta bibliotek också. För de som letar efter en pågående databas, föreslår jag att du uppmärksammar LiteDB och hur det kommer att visa sig i samband med din uppgift, eftersom, som du vet, om något hade fungerat för en uppgift, skulle det inte nödvändigtvis träna för en annan uppgift.