SQL Server introducerade In-Memory OLTP-objekt i SQL Server 2014. Det fanns många begränsningar i den första utgåvan; några har tagits upp i SQL Server 2016, och det förväntas att fler kommer att tas upp i nästa utgåva när funktionen fortsätter att utvecklas. Än så länge verkar införandet av In-Memory OLTP inte vara särskilt utbrett, men när funktionen mognar förväntar jag mig att fler kunder kommer att börja fråga om implementering. Som med alla större schema- eller kodändringar rekommenderar jag grundliga tester för att avgöra om In-Memory OLTP kommer att ge de förväntade fördelarna. Med det i åtanke var jag intresserad av att se hur prestanda förändrades för mycket enkla INSERT-, UPDATE- och DELETE-satser med In-Memory OLTP. Jag var hoppfull att om jag kunde visa att låsning eller låsning är ett problem med diskbaserade tabeller, så skulle tabellerna i minnet ge en lösning, eftersom de är lås- och låsfria.
Jag utvecklade följande test fall:
- En diskbaserad tabell med traditionella lagrade procedurer för DML.
- En tabell i minnet med traditionella lagrade procedurer för DML.
- En tabell i minnet med inbyggda kompilerade procedurer för DML.
Jag var intresserad av att jämföra prestanda för traditionella lagrade procedurer och inbyggda kompilerade procedurer, eftersom en begränsning av en inbyggd kompilerad procedur är att alla tabeller som refereras till måste vara In-Memory. Medan enradiga, ensamma modifieringar kan vara vanliga i vissa system, ser jag ofta ändringar som sker inom en större lagrad procedur med flera uttalanden (SELECT och DML) som kommer åt en eller flera tabeller. In-Memory OLTP-dokumentationen rekommenderar starkt att du använder inbyggda kompilerade procedurer för att få största möjliga nytta när det gäller prestanda. Jag ville förstå hur mycket det förbättrade prestandan.
Inställningen
Jag skapade en databas med en minnesoptimerad filgrupp och skapade sedan tre olika tabeller i databasen (en diskbaserad, två i minnet):
- Disktabell
- InMemory_Temp1
- InMemory_Temp2
DDL var nästan densamma för alla objekt, där det var lämpligt att ta hänsyn till på disk kontra in-memory. DiskTable DDL vs. In-Memory DDL:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Jag skapade också nio lagrade procedurer – en för varje tabell/ändringskombination.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Uppdatera
- InMemRegularSP _Ta bort
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Varje lagrad procedur accepterade en heltalsinmatning till loop för det antalet modifieringar. De lagrade procedurerna följde samma format, variationer var bara den tabell som användes och om objektet var inbyggt kompilerat eller inte. Den fullständiga koden för att skapa databasen och objekten finns här, med exempel INSERT och UPDATE-satser nedan:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Obs! IDs_*-tabellerna fylldes på igen efter att varje uppsättning INSERT slutförts och var specifika för de tre olika scenarierna.
Testmetod
Testningen gjordes med .cmd-skript som använde sqlcmd för att anropa ett skript som körde den lagrade proceduren, till exempel:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"avsluta
Jag använde detta tillvägagångssätt för att skapa en eller flera anslutningar till databasen som skulle köras samtidigt. Förutom att förstå grundläggande förändringar av prestanda, ville jag också undersöka effekten av olika arbetsbelastningar. Dessa skript initierades från en separat maskin för att eliminera overheaden av instansierande anslutningar. Varje lagrad procedur exekverades 1000 gånger av en anslutning, och jag testade 1 anslutning, 10 anslutningar och 100 anslutningar (1000, 10000 respektive 100000 modifieringar). Jag fångade prestationsstatistik med Query Store, och fångade även Wait Statistics. Med Query Store kunde jag fånga genomsnittlig varaktighet och CPU för varje lagrad procedur. Väntestatistikdata samlades in för varje anslutning med dm_exec_session_wait_stats, och aggregerades sedan för hela testet.
Jag körde varje test fyra gånger och beräknade sedan de totala medelvärdena för data som användes i det här inlägget. Skript som används för arbetsbelastningstestning kan laddas ner härifrån.
Resultat
Som man skulle förutsäga var prestanda med In-Memory-objekt bättre än med diskbaserade objekt. Men en In-Memory-tabell med en vanlig lagrad procedur hade ibland jämförbar eller bara något bättre prestanda jämfört med en diskbaserad tabell med en vanlig lagrad procedur. Kom ihåg:Jag var intresserad av att förstå om jag verkligen behövde en sammanställd lagrad procedur för att få en stor fördel med en in-memory-tabell. För det här scenariot gjorde jag det. I alla fall hade in-memory-tabellen med den inbyggda kompilerade proceduren betydligt bättre prestanda. De två graferna nedan visar samma data, men med olika skalor för x-axeln, för att visa att prestandan för vanliga lagrade procedurer som modifierar data försämras med fler samtidiga anslutningar.
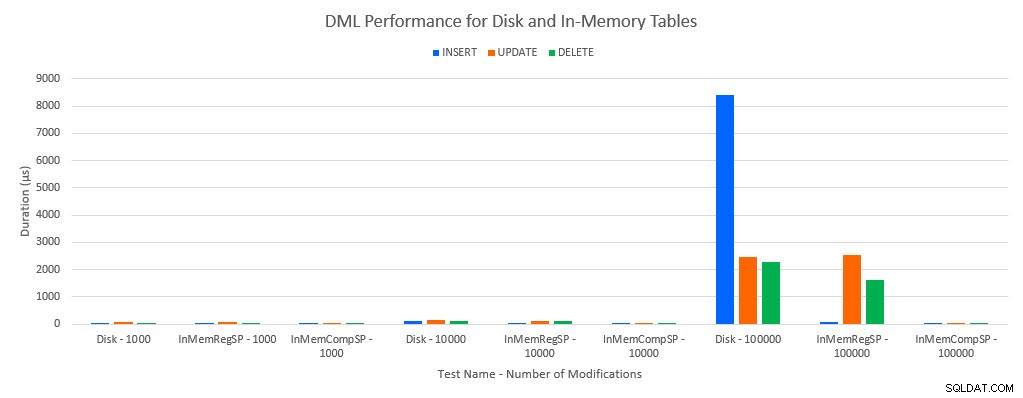
DML-prestanda efter test och arbetsbelastning
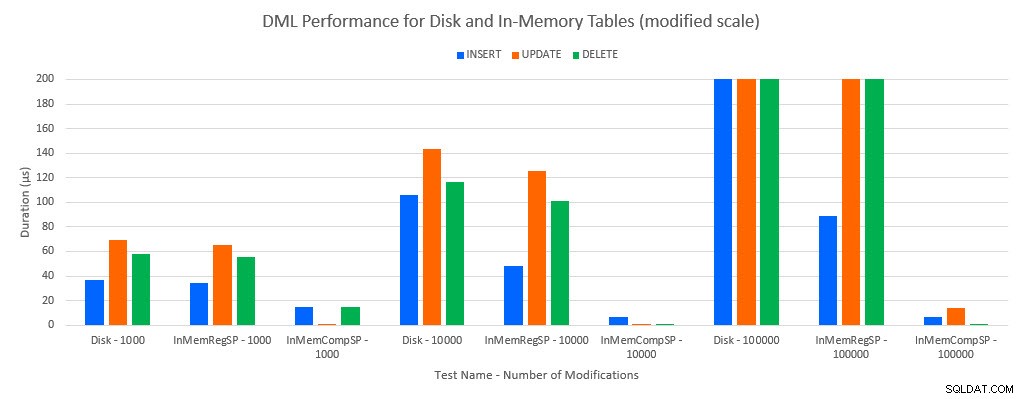
DML-prestanda efter test och arbetsbelastning [Ändrad skala]
Undantaget är INSERTs i In-Memory-tabellen med den vanliga lagrade proceduren. Med 100 anslutningar är den genomsnittliga varaktigheten över 8ms för en diskbaserad tabell, men mindre än 100 mikrosekunder för In-Memory-tabellen. Den troliga orsaken är frånvaron av låsning och låsning med In-Memory-tabellen, och detta stöds med väntestatistikdata:
| Testa | INSERT | UPPDATERA | RADERA |
|---|---|---|---|
| Disktabell – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Disktabell – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10 000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Disktabell – 100 000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
Väntestatistik genom test
Väntestatistikdata listas här baserat på total resursväntetid (vilket i allmänhet också översätts till högsta genomsnittliga resurstid, men det fanns undantag). Väntetypen WRITELOG är den begränsande faktorn i detta system större delen av tiden. Men PAGELATCH_EX väntar på 100 samtidiga anslutningar som kör INSERT-satser tyder på att med ytterligare belastning kan låsnings- och låsbeteendet som finns med diskbaserade tabeller vara begränsande faktor. I UPDATE- och DELETE-scenarierna med 10 och 100 anslutningar för de diskbaserade tabelltesterna var den genomsnittliga resursväntetiden högst för lås (LCK_M_X).
Slutsats
In-Memory OLTP kan absolut ge en prestandaökning för rätt arbetsbelastning. Exemplen som testas här är dock extremt enkla och bör inte bedömas som enbart anledning att migrera till en In-Memory-lösning. Det finns flera begränsningar som fortfarande finns som måste beaktas, och noggranna tester måste göras innan en migrering sker (särskilt eftersom migrering till en In-Memory-tabell är en offlineprocess). Men för rätt scenario kan den här nya funktionen ge en prestandaökning. Så länge du förstår att vissa underliggande begränsningar fortfarande kommer att finnas, såsom transaktionslogghastighet för hållbara tabeller, men troligen på ett reducerat sätt – oavsett om tabellen finns på disk eller i minnet.