
Gästförfattare:Andy Mallon (@AMtwo)
Nej, seriöst. Vad är en DTU?
När du distribuerar en applikation är en av de första frågorna som dyker upp "Vad kommer detta att kosta?" De flesta av oss har gått igenom den här typen av övning för att dimensionera en SQL Server-installation någon gång, men vad händer om du distribuerar till molnet? Med Azure IaaS-distributioner har inte mycket förändrats – du bygger fortfarande en server baserad på CPU-antal, viss mängd minne och konfigurerar lagring för att ge dig tillräckligt med IOPS för din arbetsbelastning. Men när du hoppar till PaaS är Azure SQL Database storleksanpassad med olika tjänstenivåer, där prestanda mäts i DTU:er. Vad i helvete är en DTU?
Jag vet vad en BTU är. Kanske står DTU för Database Thermal Unit? Är det mängden processorkraft som behövs för att höja temperaturen i datacentret med en grad? Istället för att gissa, låt oss kolla dokumentationen och se vad Microsoft har att säga:
En [Databas Transaction Unit] är ett blandat mått på CPU, minne och data I/O och transaktionslogg I/O i ett förhållande som bestäms av en OLTP benchmark-arbetsbelastning utformad för att vara typisk för verkliga OLTP-arbetsbelastningar. Att fördubbla DTU:erna genom att öka prestandanivån för en databas är detsamma som en fördubbling av mängden tillgängliga resurser för databasen.OK, det var min andra gissning – men vad är det "blandade måttet"? Hur kan jag översätta det jag vet om storlek på en server till storlek på en Azure SQL-databas? Tyvärr finns det inget enkelt sätt att översätta "2 CPU-kärnor och 4 GB minne" till en DTU-mätning.
Finns det inte en DTU-kalkylator?
ja! Microsoft ger oss en DTU-kalkylator att uppskatta rätt tjänstenivå för Azure SQL Database. För att använda det laddar du ner och kör ett PowerShell-skript (sql-perfmon.ps1) på servern medan du kör en arbetsbelastning i SQL Server. Skriptet matar ut en CSV som innehåller fyra perfmonräknare:(1) total % processortid, (2) total diskläsning/sekund, (3) total diskskrivning per sekund och (4) total loggbyte tömd/sekund. Denna CSV-utdata laddas sedan upp till DTU-kalkylatorn, som uppskattar vilken servicenivå som bäst motsvarar dina behov. Den enda data som DTU-kalkylatorn tar utöver CSV:en är antalet CPU-kärnor på servern som genererade filen. DTU-kalkylatorn är fortfarande lite av en svart låda – det är inte lätt att kartlägga det vi vet från våra lokala databaser till Azure.
Jag skulle vilja påpeka att definitionen av en DTU är att det är "ett blandat mått på CPU, minne , och data I/O och transaktionslogg I/O..." Ingen av de perfmonräknare som används av DTU Calculator tar hänsyn till minne, men det är tydligt listat i definitionen som en del av beräkningen. Detta är inte nödvändigtvis en problem, men det är bevis på att DTU-kalkylatorn inte kommer att vara perfekt.
Jag ska ladda upp lite syntetisk belastning i DTU-kalkylatorn och se om jag kan ta reda på hur den svarta lådan fungerar. Faktum är att jag kommer att tillverka CSV:erna helt så att jag helt och hållet kan kontrollera perfmonnumren som vi laddar in i DTU-kalkylatorn. Låt oss gå igenom ett mått i taget. För varje mätvärde laddar vi upp 25 minuter (1500 sekunder – jag gillar runda siffror) av tillverkad data och ser hur den perfmon-datan konverteras till DTU:er.
CPU
Jag ska skapa en CSV som simulerar en 16-kärnig server, och sakta ökar CPU-användningen tills den är kopplad till 100 %. Eftersom jag ska simulera uppgången på en 16-kärnig server, skapar jag min CSV för att stega upp 1/16:e åt gången – i huvudsak simulerar en kärna som maxar ut, sedan en andra maxar ut, sedan den tredje, etc. Hela tiden kommer CSV:en att visa noll läsningar, skrivningar och loggar. En server skulle faktiskt aldrig generera en arbetsbelastning som denna – men det är poängen. Jag isolerar CPU-användningen helt så att jag kan se hur CPU påverkar DTU:er.
Jag skapar en CSV-fil som har en rad per sekund, och var 94:e sekund kommer jag att öka räknaren för total % processortid med ~6%. De övriga tre räknarna kommer att vara noll i alla fall. Nu laddar jag upp den här filen till DTU-kalkylatorn (och säger till DTU-kalkylatorn att ta hänsyn till 16 kärnor), och här är resultatet:
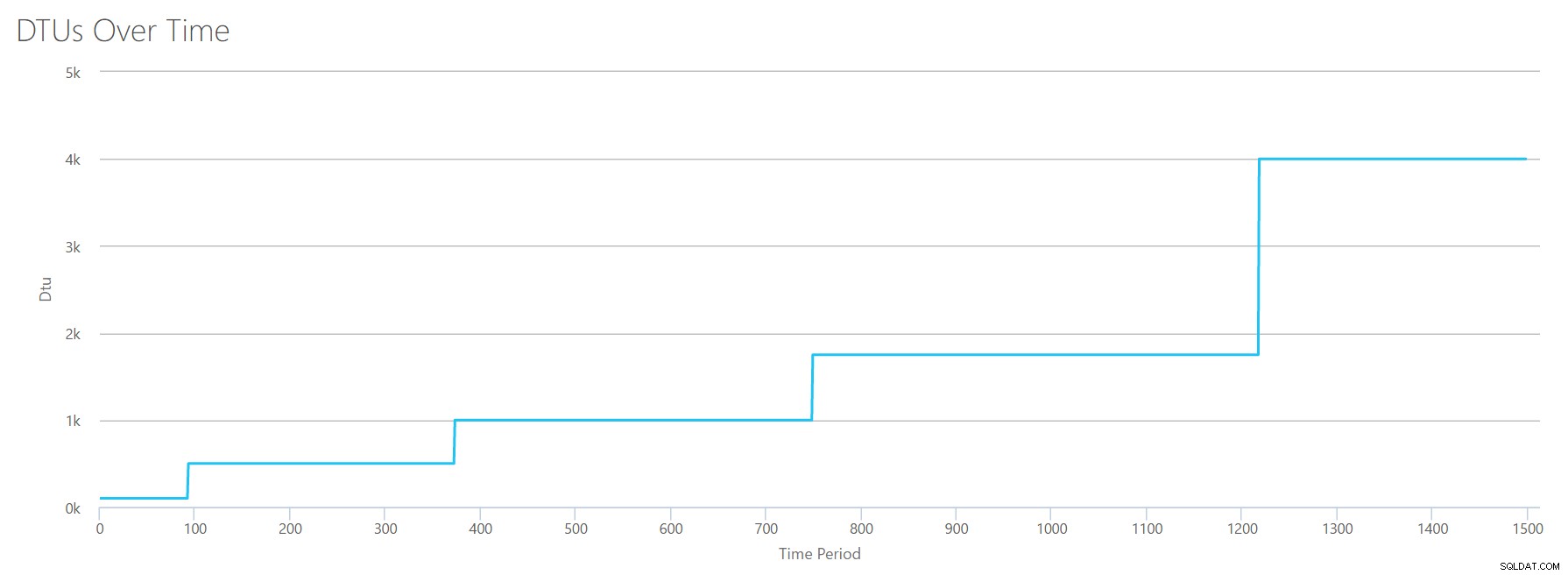
Vänta? Ökade jag inte CPU-användningen i 16 jämna steg? Denna DTU-graf visar bara fem steg. Jag måste ha trasslat till. Nej, min CSV hade 16 jämna steg, men det översätts (uppenbarligen) inte jämnt till DTU:er. Åtminstone inte enligt DTU-kalkylatorn. Baserat på vårt maxade CPU-test skulle vår CPU-till-DTU-till-Service Tier-mappning se ut så här:
| Antal kärnor | DTU:er | Servicenivå |
|---|---|---|
| 1 | 100 | Standard – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
När vi tittar på denna information får vi några saker:
- En CPU-kärna, 100 % utnyttjad motsvarar 100 DTU:er.
- DTU:er ökar typ linjärt när CPU ökar, men till synes i växlingar.
- Servicenivåerna Basic och Standard är lika med mindre än en enda CPU-kärna.
- Alla flerkärniga servrar skulle översättas till någon storlek inom Premium-tjänstnivån.
Läser
Den här gången kommer jag att använda samma metod. Jag kommer att generera en CSV med ökande siffror för läs/sekundräknaren, med de andra perfmonräknarna på noll. Jag kommer sakta att öka antalet med tiden. Den här gången kan vi kliva upp i bitar av 2000, var 100:e sekund, tills vi når 30000. Detta ger oss samma 25-minuters totala tid – men den här gången har jag 15 steg istället för 16. (Jag gillar runda siffror.)
När vi laddar upp den här CSV-filen till DTU-kalkylatorn ger den oss denna DTU-graf:
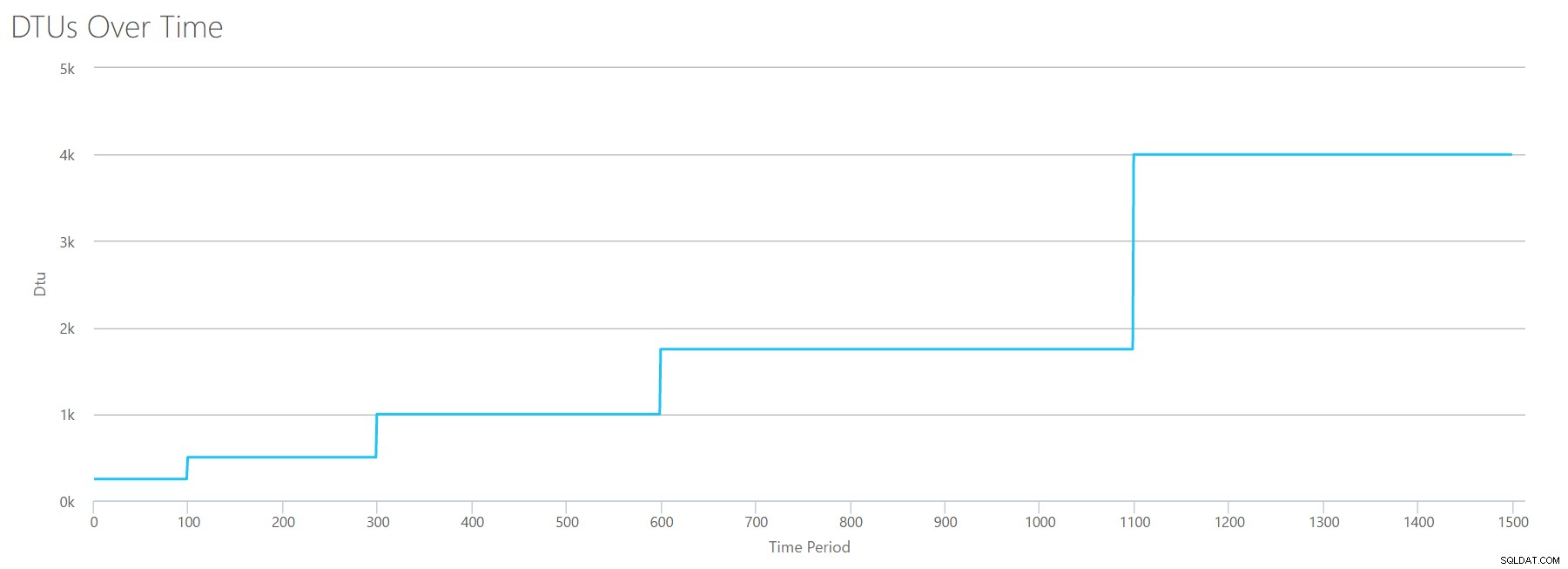
Vänta lite...det ser ganska likt ut den första grafen. Återigen, det stegar upp i 5 ojämna steg, även om jag hade 15 jämna steg i min fil. Låt oss titta på det i tabellformat:
| Läsningar/sek | DTU:er | Servicenivå |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Återigen ser vi att Basic &Standard-nivåerna hoppar över ganska snabbt (mindre än 2000 läsningar/sekund), men då är Premium-nivån ganska bred och spänner över 2000 till 30000 läsningar per sekund. I tabellen ovan kan "Reads/sec" förmodligen ses som "IOPS" … eller tekniskt sett bara "OPS" eftersom det inte finns några skrivningar som utgör "input"-delen av IOPS.
Skriver
Om vi skapar en CSV med samma formel som vi använde för Reads och laddar upp den CSV:n till DTU Calculator, får vi en graf som är identisk med grafen för Reads:
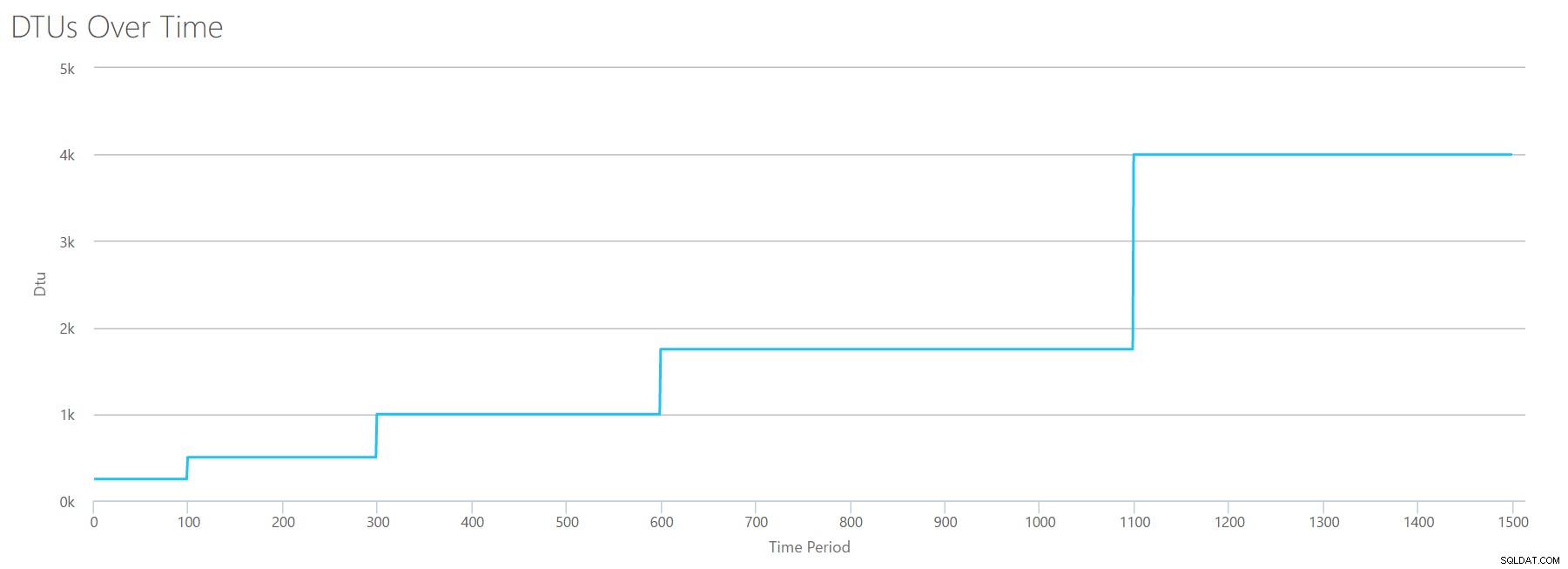
IOPS är IOPS, så oavsett om det är en läsning eller en skrivning, ser det ut som att DTU-beräkningen anser det lika. Allt vi vet (eller tror att vi vet) om läser verkar gälla lika mycket för att skriva.
Loggbytes töms
Vi är framme till den sista perfmonräknaren:logbyte töms per sekund. Detta är ett annat mått på IO, men specifikt för SQL Server-transaktionsloggen. Om du inte har kommit ikapp vid det här laget skapar jag dessa CSV:er så att de höga värdena kommer att beräknas som en P15 Azure DB, och delar sedan helt enkelt upp värdet för att dela upp det i jämna steg. Den här gången ska vi gå från 5 miljoner till 75 miljoner, i steg om 5 miljoner. Som vi gjorde vid alla tidigare tester kommer de andra perfmonräknarna att vara noll. Eftersom den här perfmonräknaren är i byte per sekund, och vi mäter i miljoner, kan vi tänka på detta i enheten vi är mer bekväma med:Megabyte per sekund.
Vi laddar upp denna CSV till DTU-kalkylatorn och vi får följande graf:
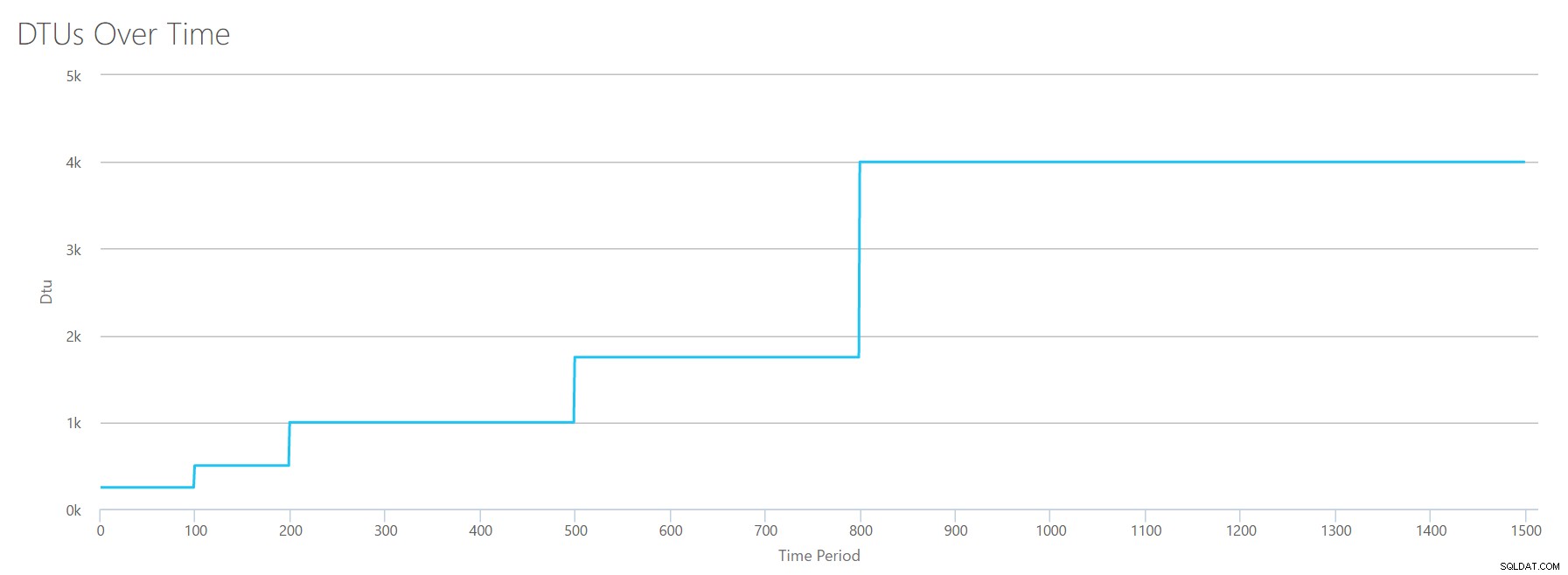
| Logg Megabyte töms/sek | DTU:er | Servicenivå |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
Formen på den här grafen börjar bli ganska förutsägbar. Förutom den här gången kliver vi upp genom nivåerna lite snabbare och når P15 efter bara 8 steg (jämfört med 11 för IO och 12 för CPU). Detta kan få dig att tänka, "Det här kommer att bli min smalaste flaskhals!" men jag skulle inte vara så säker på det. Hur ofta genererar du 75 MB logg på en sekund ? Det är 4,5 GB per minut . Det är mycket databasaktivitet. Min syntetiska arbetsbelastning är inte nödvändigtvis en realistisk arbetsbelastning.
Kombinerar allt
OK, nu när vi har sett var några av de övre gränserna är isolerade, ska jag kombinera data och se hur de jämförs när CPU, I/O och transaktionslogg-IO alla händer på en gång – trots allt , är det inte så saker faktiskt händer?
För att bygga denna CSV tog jag helt enkelt de befintliga värdena som vi använde för varje enskilt test ovan och kombinerade dessa värden till en enda CSV, vilket ger denna vackra graf:
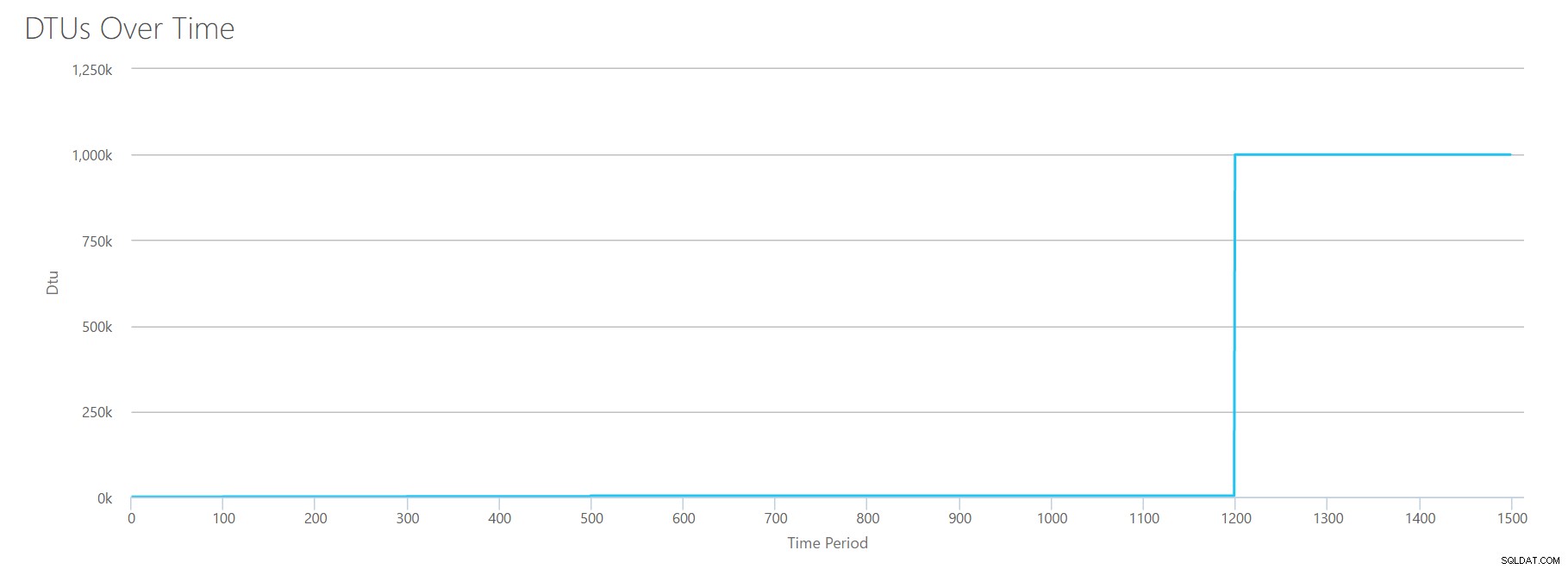
Det ger också meddelandet:
Baserat på din databasanvändning är din SQL Server-arbetsbelastning Out of Range . För närvarande finns det ingen servicenivå/prestandanivå som täcker din användning.Om du tittar på Y-axeln ser du att vi träffar "1 000k" (dvs. 1 miljon) DTU:er vid 1200 sekunders markeringen. Det verkar...ehh...fel? Om vi tittar på ovanstående tester, var 1200-sekundersmärket när alla 4 individuella mätvärden träffade märket för 4000 DTU, P15-nivå. Det är vettigt att vi skulle vara utanför räckhåll, men formen på grafen är inte riktigt vettig för mig – jag tror att DTU-kalkylatorn bara kastade upp händerna och sa:"Oavsett vad, Andy. Det är mycket. Det är för mycket. Det är en bajillion DTU:er. Den här arbetsbelastningen passar inte för Azure SQL Database."
OK, så vad händer före märket på 1200 sekunder? Låt oss skära ner CSV:en och skicka in den igen till kalkylatorn med bara de första 1200 sekunderna. Maxvärdena för varje kolumn är:81 % CPU (eller ca 13 kärnor vid 100 %), 24 000 läser/sekund, 24 000 skrivningar/sekund och 60 MB logg tömda/sekund.
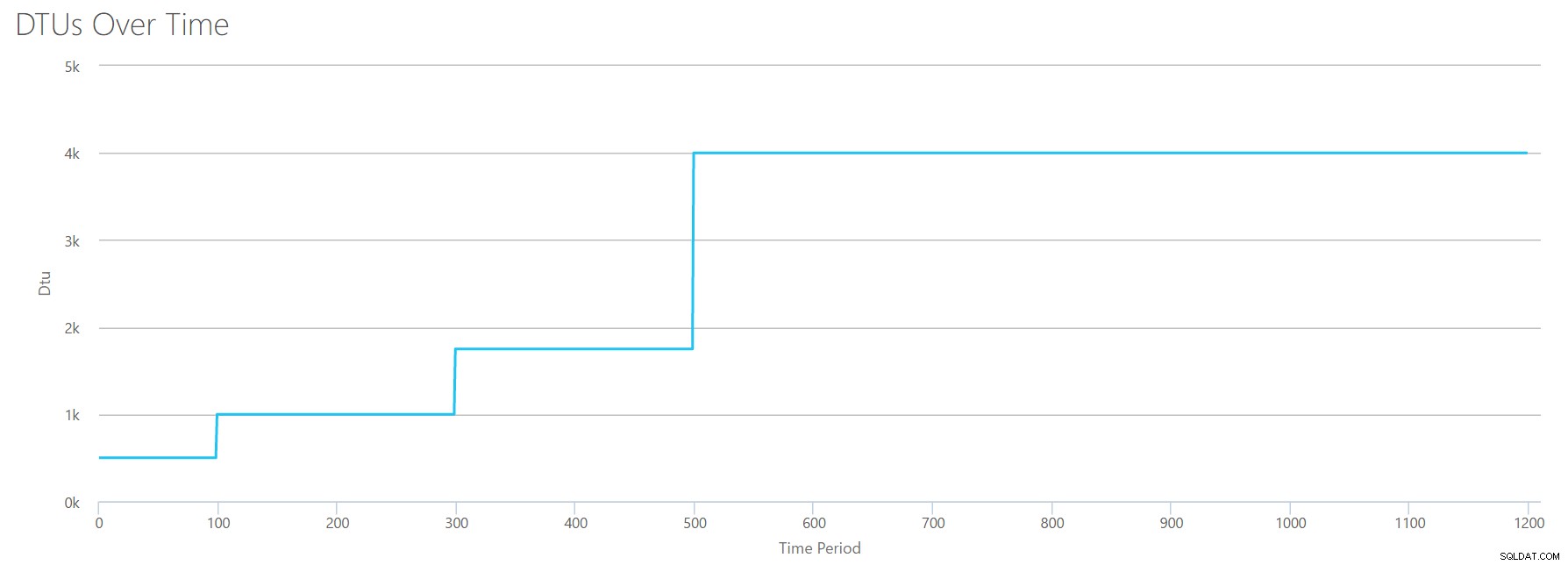
Hej, gamle vän... Den där välbekanta formen är tillbaka igen. Här är en sammanfattning av data från CSV:n och vad DTU-kalkylatorn uppskattar för total DTU-användning och servicenivå.
| Antal kärnor | Läser/sek | Skriver/sek | Logg Megabyte töms/sek | DTU:er | Servicenivå |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Låt oss nu titta på hur de individuella DTU-beräkningarna (när vi utvärderade dem isolerat) jämför med DTU-beräkningarna från denna senaste kontroll:
| CPU DTU:er | Läs DTU:er | Skriv DTU:er | Loggspolade DTU:er | Summa totala DTU:er | DTU Calculator-uppskattning | Servicenivå |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Du kommer att märka att DTU-beräkningen inte är så enkel som att lägga ihop dina separata DTU:er. Som definitionen jag citerade i början säger, är det ett "blandat mått" av dessa separata mätvärden. Formeln som används för "blandning" är komplicerad, och vi har faktiskt inte den formeln. Vad vi kan se är att DTU Calculator-uppskattningarna är lägre än summan av de separata DTU-beräkningarna.
Mappning av DTU:er till traditionell hårdvara
Låt oss ta data från DTU-kalkylatorn och försöka sätta ihop några gissningar för hur traditionell hårdvara kan mappas till vissa Azure SQL Database-nivåer.
Först, låt oss anta att "läser/sek" och "skriver/sek" översätts till IOPS direkt, utan att någon översättning behövs. För det andra, låt oss anta att lägga till dessa två räknare kommer att ge oss vår totala IOPS. För det tredje, låt oss erkänna att vi inte har någon aning om vad minnesanvändning är, och vi har inget sätt att dra några slutsatser på den fronten.
Medan jag uppskattar hårdvaruspecifikationer kommer jag också att välja en möjlig Azure VM-storlek som passar varje hårdvarukonfiguration. Det finns många liknande Azure VM-storlekar, var och en optimerad för olika prestandamått, men jag har gått vidare och begränsat mina val till A-serien och DSv2-serien.
| Antal kärnor | IOPS | Minne | DTU:er | Servicenivå | Jämförbar Azure VM-storlek |
|---|---|---|---|---|---|
| 1 kärna, 5 % utnyttjande | 10 | ??? | 5 | Grundläggande | Standard_A0, knappt använd |
| <1 kärna | 150 | ??? | 100 | Standard S0-S3 | Standard_A0, inte fullt utnyttjad |
| 1 kärna | upp till 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2-3 kärnor | upp till 12 000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4-5 kärnor | upp till 20 000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | upp till 48 000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
Basic-nivån är otroligt begränsad. Det är bra för tillfällig/avslappnad användning, och det är ett billigt sätt att "parkera" din databas när du inte använder den. Men om du kör någon riktig applikation, kommer Basic-nivån inte att fungera för dig.
Standardnivån är också ganska begränsad, men för små applikationer kan den möta dina behov. Om du har en 2-kärnig server som kör en handfull databaser, kan dessa databaser individuellt passa in i standardnivån. På samma sätt, om du har en server med bara en databas, som kör 1 CPU-kärna på 100 % (eller 2 kärnor som körs på 50 %), är det förmodligen precis tillräckligt med hästkrafter för att tippa skalan till Premium-P1-tjänstnivån.
Om du skulle använda en flerkärnig server i en lokal (eller IaaS) så skulle du leta inom Premium-tjänstnivån på Azure SQL Database. Det är bara en fråga om att bestämma hur mycket CPU &I/O hästkrafter du behöver för din arbetsbelastning. Din 2-kärniga, 4GB-server landar dig förmodligen någonstans runt en P6 Azure SQL DB. I en ren CPU-arbetsbelastning (med noll I/O) skulle en P15-databas kunna hantera 16 kärnor värda bearbetning, men när du väl lägger till IO till mixen passar inte allt större än ~12 kärnor in i Azure SQL Database.
Nästa gång tar jag några faktiska arbetsbelastningar och jämför prestanda mellan tjänstenivåer. Kommer DTU-kalkylatorns uppskattningar att vara korrekta? Vi får reda på det.
Om författaren
 Andy Mallon är en SQL Server DBA och Microsoft Data Platform MVP som har hanterat databaser inom sjukvård, finans, e. -handel och ideella sektorer. Sedan 2003 har Andy stött OLTP-miljöer med höga volymer och hög tillgänglighet med krävande prestandabehov. Andy är grundaren av BostonSQL, medarrangör av SQLSaturday Boston, och bloggar på am2.co.
Andy Mallon är en SQL Server DBA och Microsoft Data Platform MVP som har hanterat databaser inom sjukvård, finans, e. -handel och ideella sektorer. Sedan 2003 har Andy stött OLTP-miljöer med höga volymer och hög tillgänglighet med krävande prestandabehov. Andy är grundaren av BostonSQL, medarrangör av SQLSaturday Boston, och bloggar på am2.co.