Typen och antalet lås som förvärvats och släppts under exekveringen av en fråga kan ha en överraskande effekt på prestandan (när man använder en låsningsisoleringsnivå som standardinställningen för läsning) även där ingen väntan eller blockering inträffar. Det finns ingen information i exekveringsplaner som indikerar mängden låsaktivitet under utförande, vilket gör det svårare att upptäcka när överdriven låsning orsakar prestandaproblem.
För att utforska några mindre kända låsbeteenden i SQL Server kommer jag att återanvända frågorna och exempeldata från mitt senaste inlägg om beräkning av medianer. I det inlägget nämnde jag att OFFSET grupperad medianlösning behövde en explicit PAGLOCK låstips för att undvika att förlora dåligt till den kapslade markören lösning, så låt oss börja med att titta närmare på orsakerna till det.
OFFSET Grouped Median Solution
Det grupperade mediantestet återanvände provdata från Aaron Bertrands tidigare artikel. Manuset nedan återskapar denna miljonradsuppställning, bestående av tiotusen poster för var och en av hundra imaginära säljare:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (och senare) OFFSET lösning skapad av Peter Larsson är följande (utan några låstips):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); De viktiga delarna av planen efter genomförandet visas nedan:

Med all nödvändig data i minnet körs denna fråga på 580 ms i genomsnitt på min bärbara dator (kör SQL Server 2014 Service Pack 1). Prestandan för den här frågan kan förbättras till 320 ms helt enkelt genom att lägga till en sidgranularitetslåsningstips till försäljningstabellen i underfrågan Applicera:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Utförandeplanen är oförändrad (nåja, bortsett från den låsande tipstexten i showplan XML förstås):
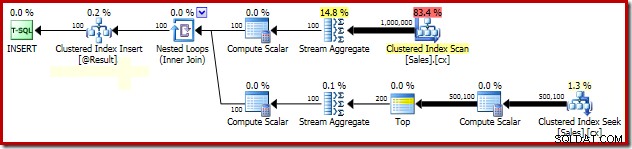
Grupperad medianlåsningsanalys
Förklaringen till den dramatiska förbättringen av prestanda på grund av PAGLOCK tipset är ganska enkelt, åtminstone till en början.
Om vi manuellt övervakar låsaktivitet medan den här frågan körs ser vi att utan tipset om granularitet för sidlåsning, förvärvar och släpper SQL Server över en halv miljon radnivålås medan du söker efter det klustrade indexet. Det finns ingen blockering att skylla på; att helt enkelt skaffa och släppa så många lås lägger till en avsevärd overhead till den här frågans exekvering. Att begära låsningar på sidnivå minskar låsningsaktiviteten avsevärt, vilket resulterar i mycket förbättrad prestanda.
Problemet med den här specifika planens låsningsprestanda är begränsad till det klustrade indexsökningen i planen ovan. Den fullständiga genomsökningen av det klustrade indexet (används för att beräkna antalet rader som finns för varje säljare) använder sidnivålås automatiskt. Detta är en intressant punkt. Det detaljerade låsbeteendet för SQL Server-motorn är inte dokumenterat i Books Online i någon större utsträckning, men olika medlemmar av SQL Server-teamet har gjort några allmänna kommentarer under åren, inklusive det faktum att de obegränsade skanningarna tenderar att börja ta sida lås, medan mindre operationer tenderar att börja med radlås.
Frågeoptimeraren gör viss information tillgänglig för lagringsmotorn, inklusive kardinalitetsuppskattningar, interna tips för isoleringsnivå och låsningsgranularitet, vilka interna optimeringar som säkert kan tillämpas och så vidare. Återigen, dessa detaljer är inte dokumenterade i Books Online. I slutändan använder lagringsmotorn en mängd information för att bestämma vilka lås som krävs vid körning och vid vilken granularitet de ska tas.
Som en sidoanteckning, och kom ihåg att vi pratar om en fråga som exekveras under standardlåsningsnivån för isolering av läs engagerad transaktion, notera att radlåsningarna som tas utan granularitetstipset inte kommer att eskalera till ett tabelllås i det här fallet. Detta beror på att det normala beteendet under läsning är att släppa det föregående låset precis innan nästa lås skaffas, vilket innebär att endast ett enstaka delad radlås (med tillhörande högre nivå av avsiktsdelade lås) kommer att hållas vid ett visst tillfälle. Eftersom antalet samtidigt hållna radlås aldrig når tröskeln, görs ingen låseskalering.
OFFSET Single Median Solution
Prestandatestet för en enskild medianberäkning använder en annan uppsättning exempeldata, återigen återgiven från Aarons tidigare artikel. Skriptet nedan skapar en tabell med tio miljoner rader med pseudoslumpdata:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET lösningen är:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Planen efter genomförandet är:

Den här frågan körs på 910 ms i genomsnitt på min testmaskin. Prestanda är oförändrad om en PAGLOCK ledtråd läggs till, men anledningen till det är inte vad du kanske tänker...
Enkel medianlåsningsanalys
Du kanske förväntar dig att lagringsmotorn väljer delade lås på sidnivå ändå, på grund av den klustrade indexskanningen, som förklarar varför en PAGLOCK ledtråd har ingen effekt. Faktum är att övervakning av låsningarna som tas medan denna fråga körs avslöjar att inga delade lås (S) tas överhuvudtaget, i någon detalj . De enda lås som tas är avsiktsdelade (IS) på objekt- och sidnivå.
Förklaringen till detta beteende finns i två delar. Det första att lägga märke till är att Clustered Index Scan ligger under en toppoperatör i exekveringsplanen. Detta har en viktig effekt på uppskattningar av kardinalitet, som visas i den förutförande (uppskattade) planen:

OFFSET och FETCH satser i frågan refererar till ett uttryck och en variabel, så frågeoptimeraren gissar på antalet rader som kommer att behövas vid körning. Standardgissningen för Top är hundra rader. Detta är naturligtvis en fruktansvärd gissning, men det räcker för att övertyga lagringsmotorn att låsa vid radgranularitet istället för på sidnivå.
Om vi inaktiverar "radmål"-effekten för Top-operatören med den dokumenterade spårningsflaggan 4138, ändras det uppskattade antalet rader vid skanningen till tio miljoner (vilket fortfarande är fel, men i andra riktningen). Detta räcker för att ändra lagringsmotorns låsningsgranularitetsbeslut, så att delade lås på sidnivå (obs, inte avsiktsdelade lås) tas:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Den beräknade utförandeplanen producerad under spårningsflagga 4138 är:

För att återgå till huvudexemplet, uppskattningen av hundra rader på grund av det gissade radmålet betyder att lagringsmotorn väljer att låsa på radnivå. Vi observerar dock endast avsiktsdelade (IS) lås på tabell- och sidnivå. Dessa lås på högre nivå skulle vara ganska normala om vi såg delade (S) lås på radnivå, så var tog de vägen?
Svaret är att lagringsmotorn innehåller en annan optimering som kan hoppa över de delade låsen på radnivå under vissa omständigheter. När denna optimering tillämpas, förvärvas fortfarande de avsiktsdelade låsen på högre nivå.
För att sammanfatta, för enmedianfrågan:
- Användningen av en variabel och ett uttryck i
OFFSETklausul betyder att optimeraren gissar kardinalitet. - Den låga uppskattningen innebär att lagringsmotorn beslutar om en låsstrategi på radnivå.
- En intern optimering innebär att S-låsen på radnivå hoppas över under körning, och endast IS-låsen kvarstår på sid- och objektnivå.
Den enda medianfrågan skulle ha haft samma prestandaproblem med radlåsning som den grupperade medianen (på grund av frågeoptimerarens felaktiga uppskattning) men den sparades av en separat lagringsmotoroptimering som resulterade i att endast avsiktsdelade sid- och tabelllås togs vid körning.
Det grupperade mediantestet återbesökt
Du kanske undrar varför Clustered Index Seek i det grupperade mediantestet inte utnyttjade samma lagringsmotoroptimering för att hoppa över delade lås på radnivå. Varför användes så många delade radlås, vilket gör PAGLOCK ledtråd behövs?
Det korta svaret är att denna optimering inte är tillgänglig för INSERT...SELECT frågor. Om vi kör SELECT på egen hand (dvs utan att skriva resultaten till en tabell) och utan en PAGLOCK ledtråd, optimeringen för överhoppning av radlås är tillämpas:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Endast tabell- och sidnivå avsiktsdelade (IS) lås används, och prestandan ökar till samma nivå som när vi använder PAGLOCK antydan. Du hittar naturligtvis inte detta beteende i dokumentationen, och det kan ändras när som helst. Ändå är det bra att vara medveten om.
Dessutom, om du undrade, har spårningsflagga 4138 ingen effekt på lagringsmotorns val av låsning av granularitet i det här fallet eftersom det uppskattade antalet rader vid sökningen är för lågt (per applicerad iteration) även med radmålet inaktiverat.
Innan du drar slutsatser om prestandan för en fråga, var noga med att kontrollera antalet och typen av lås den tar under körningen. Även om SQL Server vanligtvis väljer "rätt" granularitet, finns det tillfällen då det kan få saker fel, ibland med dramatiska effekter på prestanda.