Att vara frisk och vältränad är en livsstil, inte en modefluga. Människor som inser värdet av hälsa gör det till en prioritet och håller register över alla sina fitnessrelaterade fakta. I den här artikeln kommer vi att undersöka designen av databasen bakom en hälso- och fitnessapplikation.
Det finns många applikationer som låter användare logga sin hälso- och fitnessinformation. Ett par stora aktörer som Apple, Google och Microsoft har lanserat sina egna utvecklings-API:er specifikt för denna marknad. Till exempel har Google "Fit" och Microsoft har "HealthVault".
I den här artikeln kommer jag att förklara datamodellen bakom en hälsojournalapplikation. Låt oss först diskutera exakt vad vi förväntar oss att en sådan app ska göra.
Projektkrav för en hälsoinformationsapp
Nedan finns några funktioner som en hälsoinfo-app bör stödja:
- Användare kan skapa ett konto och lagra hälsoinformation för flera profiler, dvs en individ kan lagra hälsoinformation för alla sina familjemedlemmar.
- Användare kan registrera hela sin hälsohistoria, inklusive immuniseringar, tidigare labbresultat, allergier och familjemedicinsk historia .
- Användare kan lagra olika mätningar av hälsa och kondition, som blodsockernivåer (blodsocker), blodtryck, kroppssammansättning och dimensioner inklusive body mass index (BMI), kolesterol, längd, vikt, reproduktiv hälsa, etc.
- Information kan registreras med olika metoder och måttenheter . Som ett exempel kan blodsocker mätas i mg/dL eller mmol/L.
- Det finns inga gränser för hur mycket information användare kan lagra.
- Systemet kommer också att hålla accepterade hälsostandarder, såsom blodtryck eller BMI-tal, och kommer att varna användare om deras siffror faller utanför "säkra" eller "normala" intervall.
- Användare kan också välja information (som blodsocker, längd, vikt osv.) som ska visas på sin personliga instrumentpanel. På så sätt kan de övervaka vad de behöver.
Istället för att bara förklara vad varje avsnitt och tabell gör i datamodellen, låt oss svara på några frågor om det. De olika tabellernas funktion kommer att bli tydliga allt eftersom.
Först kan du titta på den fullständiga datamodellen om du vill.
Datamodellen
Svara på frågor om hälsoinformationsdatamodellen
Hur kan användare lagra hälsoinformation för alla sina familjemedlemmar individuellt?
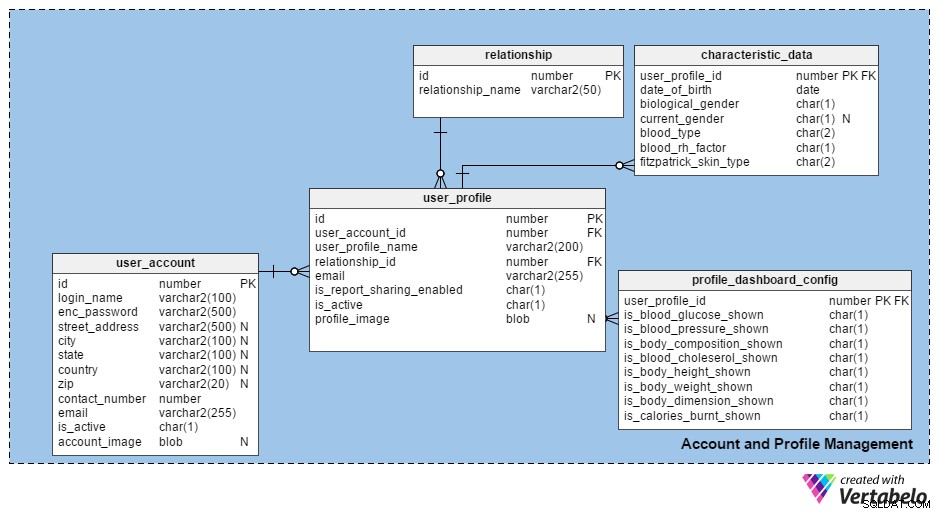
Låt oss först prata om Konto- och profilhantering . Detta kan uppnås genom att ha två olika tabeller; ett (user_account ) för att logga uppgifterna om personer som registrerar sig med applikationen, och en (user_profile ) för att logga detaljer för alla olika profiler som en registrerad användare skapar. Människor kan skapa ett antal profiler – t.ex. en för var och en av deras familjemedlemmar.
Låt oss titta på de olika tabellerna som gör detta möjligt.
user_account Tabellen innehåller grundläggande information om den person som registrerar sig med applikationen. Dess kolumner är:
id–En surrogatnyckelkolumn för den här tabellen som identifierar varje användare unikt.login_name– Namnet eller annat ID som användaren väljer som sitt inloggningsnamn. En unik begränsning måste läggas på den här kolumnen för att säkerställa att alla inloggningsnamn är olika.enc_password– Det användarvalda kontolösenordet, i krypterad form.- adresskolumner – Lagrar adress och kontaktuppgifter för användare vid registreringstillfället. Dessa kolumner inkluderar
street_address,city,state,countryochzip. Eftersom dessa fält är valfria i registreringsprocessen har jag behållit dessa kolumner som nullbara. contact_numberochemail– Lagrar användarens kontaktnummer (dvs. telefonnummer) och deras e-postadress. Dessa fält är också en del av registreringsprocessen, men de är inte nullbara.is_active– Håller antingen ett "Y" eller ett "N" för att indikera om ett konto för närvarande är aktivt.account_image– Användare får ladda upp sina egna bilder. Eftersom en användare kan ladda upp noll eller (max) en bild per konto, är detta en kolumn av BLOB-typ som kan nollställas.
user_profile Tabellen lagrar information om alla profiler som skapats av registrerade användare. Kolumnerna i denna tabell är:
id– Ett unikt nummer som tilldelas varje ny profil.user_account_id– Anger vilken användare som skapade profilen.user_profile_name– Lagrar namnet på personen i profilen. (Vi kommer att kalla denna person för "profilpersonen" och användaren som skapar profilerna "kontoinnehavaren".)relationship_id– Indikerar förhållandet mellan kontoinnehavaren och profilpersonen. Den här kolumnen hänvisar tillrelationshiptabell, som innehåller alla möjliga typer av relationer (som jaget , mamma , far , syster , bror , son , dotter , husdjur osv.).email– Den här kolumnen innehåller profilpersonens e-postadress. Rapporter eller annan information kommer att delas med dem via detta e-postmeddelande; information skulle också skickas till kontohavaren. Om Melissa till exempel skapade en profil för sin dotter Eva, skulle Evas information skickas till Melissas e-post och eventuellt till Evas e-post – se nedan.is_report_sharing_enabled– Rapporter delas alltid med kontoinnehavaren, men det är valfritt att dela dessa uppgifter med profilpersonen. Den här kolumnen visar om information kommer att delas med profilpersonen.is_active– Identifierar om en profil för närvarande är aktiv. Detta är en mjuk raderingsfunktion i fall profiler raderas av misstag.profile_image– Lagrar en bild av profilpersonen. Det här attributet är valfritt och kan därför null.
characteristic_data Tabellen innehåller individuella profildetaljer (som blodgrupp) som aldrig förändras över tiden. Alla kolumner i denna tabell är självförklarande förutom fitzpatrick_skin_type , som klassificerar beskaffenheten av ens hud från I (bränns alltid, blir aldrig brun) till VI (bränns aldrig, ingen förändring av utseendet när den är brun).
Jag har lagt till två kolumner för kön; biological_gender betecknar ens kön vid tidpunkten för födseln och current_gender anger profilpersonens nuvarande kön. Denna andra kolumn är endast tillämplig på transpersoner, och därför har jag hållit den nullbar.
Vilken viktig information kan lagras i det här systemet? Hur lagras det?
Nu går vi vidare till Hälsodatahantering . Kroppssammansättning, blodsockernivåer och kroppsdimensioner lagras i separata tabeller. Men människor kan ange mer än en typ av information åt gången, så vi använder body_vitals_log tabell för att hålla reda på vilken information som är inloggad i en profil och när den skrivs in.

All viktig statistik sparas i följande tabeller:
body_composition– Lagrar information om olika kroppssammansättningsprocent som fett, mager massa, ben eller vatten. Den innehåller också BMI-värden (body mass index) för individer.blood_cholesterol– Håller kolesteroldetaljer som LDL, HDL, triglycerider och totalt.body_dimension– Registrerar måtten på olika kroppsområden, till exempel måtten på midjan eller bröstet.body_weight– Lagrar värden för kroppsvikt.body_height– Innehåller värden för en persons längd.blood_pressure– Håller blodtryckssiffror (systoliskt och diastoliskt).blood_glucose– Registrerar blodsockernivåer.
De flesta kolumner i ovanstående tabeller är självförklarande, med några få undantag. Du kommer att märka några ytterligare kolumner som measurement_method_id , compare_to_normal_id , measurement_unit_id och measurement_context i nästan alla dessa tabeller. Jag kommer att förklara dessa kolumner senare.
body_vitals_log håller reda på vilken information som loggas vid en given tidpunkt för en profil. Kolumnerna i denna tabell är:
user_profile_id– Visar vilken profil som loggar informationen.dt_created– Lagrar datum och tid när informationen matas in.data_source_id– Anger källan till data, såsom en manual, en elektronisk enhet, etc.- IDs av olika viktig statistik – Jag har behållit alla dessa kolumner nullbara, eftersom användare får logga ett eller flera objekt åt gången. Alla användare vill inte spåra samma hälsostatistik.
Hur kan vi få systemet att fungera i olika regioner?
Viss information mäts i olika enheter inom olika områden. Till exempel mäts kroppsvikten i kilogram i Asien, men den mäts i pund i Nordamerika. Så för att göra detta fungerande i vår databas behöver vi ett sätt att spåra mätenheter.
id– Fungerar som den primära nyckeln för denna tabell, och det är den som andra tabeller refererar till.measurement_parameter– Anger vilken typ av vital information (som vikt, längd, blodtryck, etc.) en enhet mäter.unit_name– Lagrar enhetens namn. Tänk på kilogram och pund för vikt, mg/dL och mmol/L för blodsocker.
Hur kommer folk att veta om deras siffror är bra?
Vårt system är inte till mycket hjälp om det inte gör människor uppmärksamma på hälsorisker eller sårbarheter. Vi aktiverar den här funktionen genom att lägga till comparison_to_normal_id kolumn i alla tabeller med viktig information.
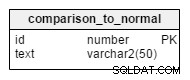
När ny viktig information loggas in i systemet jämförs posterna med motsvarande referensvärden och denna kolumn ställs in i enlighet med detta.
Möjliga värden för denna tabell är:
| I | Text |
|---|---|
| 1 | Vet inte |
| 2 | Mycket lägre |
| 3 | Lägre |
| 4 | Normal |
| 5 | Högre |
| 6 | Mycket högre |
Kan användare registrera när mätningar gjordes?
Användare kan till exempel behöva ange när deras blodsocker mättes – det vill säga före eller efter en måltid. Eller så kan de väga sig och registrera resultaten före och efter träningen. För att underlätta detta har jag lagt till en kolumn, measurement_context , i de viktiga informationstabellerna som kan behöva kontextuell information. Några möjliga värden för denna kolumn visas nedan:
| Före frukost |
| Efter frukost |
| Före lunch |
| Efter lunch |
| Före middagen |
| Efter middagen |
| Före träning |
| Efter träning |
| Fasta |
| Icke-fastande |
| Efter måltid |
| Före måltid |
| Före läggdags |
Vad händer om en person är diabetiker och behöver övervaka sina blodsockernivåer?
Systemet jag föreslår kommer att ha en instrumentpanel som kan visa viktig statistik i ett grafiskt format. Användare får välja vad de vill se på sin profilinstrumentpanel, och varje profil har sin egen instrumentpanel. Kontoinnehavare tillåts se alla profilinstrumentpaneler de har skapat.
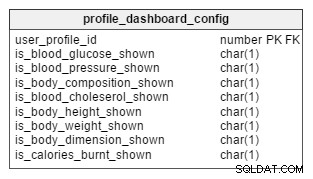
Jag har lagt till en CHAR(1) kolumn för varje parameter som kan visas på en instrumentpanel. Som standard fylls alla kolumner med "N" (visningen är avstängd) när en ny profil skapas. Användare kan senare ändra sin instrumentpanelskonfiguration från ett alternativ i appens användargränssnitt.
Hur hjälper det här systemet människor att hålla sig i form?
Med andra ord, vi pratar om Fitness Data Storage . Förutom hälsoinformation tillåter systemet även deras användare att logga information om sina tränings- och träningsrutiner.
activity_log tabellen är huvudtabellen i detta ämnesområde. Den fångar information om alla typer av aktivitetsprofiler som personer utför.
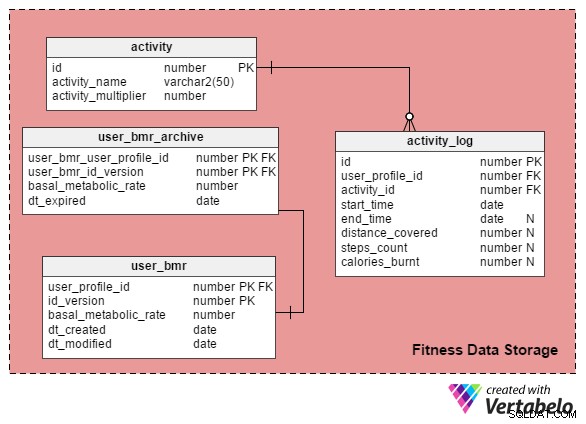
Varje aktivitet kan mätas med en eller flera av följande tre parametrar:
- Start- och sluttid – Aktiviteter som att spela sport eller spela, stå i kö etc. mäts i termer av start- och sluttid. Detta görs via
start_timeochend_timekolumner iactivity_log. - Tryggad sträcka – Aktiviteter som löpning eller cykling mäts i termer av tillryggalagd distans. Detta lagras i
distance_coveredkolumn. - Antal steg – Aktiviteter som att gå mäts i termer av antal steg, och värdena lagras i
steps_countkolumn.
Du måste undra varför calories_burnt kolumnen finns i activity_log tabell. Som namnet antyder innehåller denna kolumn värdet av kalorier som förbränts av profilpersonen när han utför en viss aktivitet. Jag kommer att förklara hur vi kan beräkna dessa värden i ett senare avsnitt.
Jag har skapat en tabell som heter activity att föra en lista över alla möjliga aktiviteter. Kolumnerna i denna tabell är:
id– Tilldelar ett unikt ID-nummer till varje aktivitet.activity_name– Lagrar aktivitetsnamn.activity_multiplier– Den här kolumnen spelar en nyckelroll när det gäller att beräkna antalet kalorier som förbränns av personer som utövar aktiviteter.
Hur beräknar du antalet förbrända kalorier för varje aktivitet?
För att förstå hur man beräknar kaloriförbränning måste vi först förstå en persons BMR, eller basala ämnesomsättning. Detta berättar hur många kalorier en kropp förbränner i vila. Varje persons BMR beror på deras kön, ålder, vikt och längd. Ur ett datamodelleringsperspektiv är en BMR en långsamt föränderlig dimension, och som sådan fortsätter den att förändras med tiden. Vi kommer att lagra de senaste individuella BMR-värdena i user_bmr tabell.
Det finns olika metoder som används för att beräkna BMR-värden:
Metod # 1:Harris-Benedict-metoden
BMR män:66+ (6,23 X vikt i pund) + (12,7 X höjd i tum) – (6,8 X ålder)
BMR kvinnor:655+ (4,35 X vikt i pund) + (4,7 X höjd i tum) – (4,7 X ålder)
Metod # 2:Katch-McArdle-metod
BMR (män + kvinnor):370+ (21,6 * mager massa i kilogram)
Lean Mass =vikt i kilogram – (vikt i kilogram * kroppsfett %)
Vi kan använda en persons BMR och aktivitetsmultiplikatorn som nämns ovan för att ta reda på hur många kalorier en person förbränner när han gör en viss aktivitet. Formeln är:
Kalorier förbrända =aktivitetsmultiplikator * BMR
Obs:Båda ovanstående BMR-beräkningsmetoder använder samma multiplikatorvärden för aktiviteter. Mer information finns i den här artikeln.
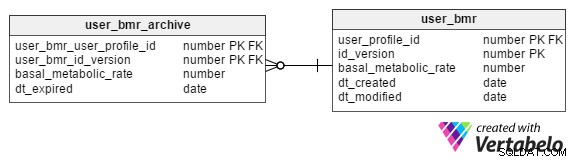
Kan vi behålla profilernas historiska BMR-värden?
Ja. Vi kan arkivera BMR-värden i user_bmr_archive tabell.
Vi börjar med att lägga till en kolumn, id_version , till den befintliga user_bmr tabell. Vi fortsätter att öka detta värde med 1 varje gång en profilpersons BMR-värde uppdateras.
user_bmr_archive tabellen är nästan en replik av user_bmr tabell. Den enda skillnaden är att den har en dt_expired kolumnen istället för dt_created och dt_modified kolumner. dt_expired kolumnen lagrar datumet då versionen blev ogiltig, det vill säga när BMR-värdet uppdateras i user_bmr .
Vad händer om användare vill föra register över sina vaccinationer, familjemedicinsk historia och allergier?
Detta system använder följande tabeller för att ge användare möjlighet att lagra ytterligare hälsoinformation.
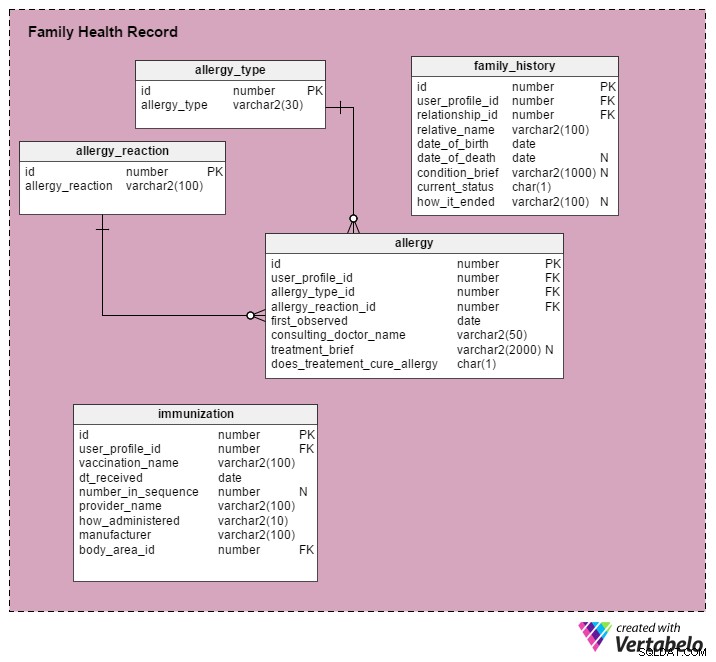
immunization Tabellen lagrar information om immuniseringar som tagits emot av profilpersoner. Efter exemplet ser du en kort beskrivning av kolumnerna som denna tabell innehåller:
Exempel – John Soo fick den andra av tre doser av ett hepatit B-vaccin. Det administrerades av Dr. David Moore den 28 november 2016. Vaccinationen gavs genom en injektion i vänster hand. Den tillverkas av Cipla (ett läkemedelsföretag).
id– Den här tabellens primärnyckeluser_profile_id– Refererar tilluser_profile_IDav John Soovaccination_name– "Hepatit B"dt_received– "28 nov 2016"number_in_sequence– "02"body_area_id– ID:t för vänster hand, hänvisat frånbody_areabordprovider_name– "Dr. David Moore”how_administered– "Injicerad" (andra möjliga värden inkluderar nässpray, tablett, droppar, sirap )manufacturer– "Cipla"
allergy tabellen lagrar information om eventuella allergier som upplevs av profilpersoner. Nedan finns en lista med kolumner, med relevanta värden för var och en enligt exemplet:
Exempel – Alison D’Souza får hosta när hon äter yoghurt. Hon fick denna reaktion första gången när hon var 8 år gammal. Hon konsulterar Dr. Bill Smith, som skriver ut medicin och ger råd om vissa försiktighetsåtgärder. Denna allergi kvarstår fortfarande, men dess intensitet är lägre nu.
id– Tabellens primärnyckeluser_profile_id– Ravseruser_profile_idav Alison D’Souzaallergy_type_id– Refererar till ID:t för "Mat"-allergitypen iallergy_typetabell. (allergy_typeTabellen definierar olika allergityper som mat, medicin, miljö, djur, växt, etc.)allergy_reaction_id– Refererar till ID:t för allergireaktionen "Hosta" iallergy_reactionbord.first_observed– Datumet då denna reaktion först observerades, dvs. när Alison var 8 år gammal.consulting_doctor_name– "Dr. Bill Smith”treatment_brief– En kort beskrivning av de ordinerade läkemedlen och rekommenderade försiktighetsåtgärder.does_treatment_cure_allergy– ”Delvis botad. Sänkt reaktionsintensitet.”
family_history Tabellen lagrar information om användarnas medicinska familjehistoria. Återigen har vi listat kolumnerna och typen av information som skulle lagras i dem baserat på följande exempel.
Exempel – Dianas mamma Lisa har Parkinsons sjukdom (en neurologisk sjukdom). Hon har genomgått behandling, men har inte fått någon påtaglig förbättring.
id– tabellens primärnyckeluser_profile_id– Dianasuser_profile_IDfrånuser_profilebordRelationship_id– 'mamma'-ID frånrelationshipbordRelative_name– "Lisa"Date_of_birth– Lisas födelsedatumDate_of_death– NULL (Lisa lever fortfarande och kämpar hårt mot sjukdomen.)Condition_brief– En kort beskrivning av hur, när och var tillståndet började, konsultationer, eventuell lättnad etc.Current_status– 'Aktuell' (Andra möjliga statusar är 'Intermittent' och 'Förflutna'.)How_it_ended– NULL
Vad skulle du lägga till den här datamodellen?
Systemet låter folk veta hur många kalorier de förbränner medan de utövar olika aktiviteter, men det spårar inte hur många kalorier de konsumerar eller hur näringsrika deras matval är. Dessutom tillåter systemet dem att registrera sina träningsdata dagligen, men det låter dem inte sätta upp ett mål, formulera en plan och spåra deras framsteg så att de förblir motiverade.
Ska vi överväga att bygga in dessa funktioner i den? Vilka ändringar behöver göras för att lägga till dessa funktioner?
Låt oss veta dina idéer!