SQL Server ger oss ett antal fönsterfunktioner som hjälper oss att utföra beräkningar över en rad rader, utan att behöva upprepa anropen till databasen. Till skillnad från de vanliga aggregerade funktionerna kommer fönsterfunktionerna inte att gruppera raderna i en enda utdatarad, de kommer att returnera ett enda aggregerat värde för varje rad, och behåller de separata identiteterna för dessa rader. Termen Window här är inte relaterad till Microsoft Windows-operativsystemet, den beskriver uppsättningen rader som funktionen kommer att bearbeta.
En av de mest användbara typerna av fönsterfunktioner är Ranking Window Functions som används för att rangordna specifika fältvärden och kategorisera dem efter rangordningen för varje rad, vilket resulterar i ett enda aggregerat värde för varje deltagande rad. Det finns fyra rankningsfönsterfunktioner som stöds i SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() och NTILE(). Alla dessa funktioner används för att beräkna ROWID för det angivna radfönstret på sitt eget sätt.
Fyra rankningsfönsterfunktioner använder OVER()-satsen som definierar en användarspecificerad uppsättning rader inom en frågeresultatuppsättning. Genom att definiera OVER()-satsen kan du också inkludera PARTITION BY-satsen som bestämmer uppsättningen rader som fönsterfunktionen kommer att bearbeta, genom att tillhandahålla kolumn- eller kommaseparerade kolumner för att definiera partitionen. Dessutom kan ORDER BY-satsen inkluderas, som definierar sorteringskriterierna inom partitionerna som funktionen ska gå igenom raderna under bearbetning.
I den här artikeln kommer vi att diskutera hur man praktiskt använder fyra rankningsfönsterfunktioner:ROW_NUMBER(), RANK(), DENSE_RANK() och NTILE() och skillnaden mellan dem.
För att tjäna vår demo kommer vi att skapa en ny enkel tabell och infoga några poster i tabellen med hjälp av T-SQL-skriptet nedan:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Du kan kontrollera att data har infogats med hjälp av följande SELECT-sats:
SELECT * FROM StudentScore ORDER BY Student_ScoreMed det sorterade resultatet tillämpat är resultatuppsättningen som följer nedan:

ROW_NUMBER()
Rangeringsfönsterfunktionen ROW_NUMBER() returnerar ett unikt sekventiellt nummer för varje rad inom partitionen i det angivna fönstret, med början på 1 för den första raden i varje partition och utan att upprepa eller hoppa över nummer i rankningsresultatet för varje partition. Om det finns dubbla värden inom raduppsättningen kommer ranknings-ID-numren att tilldelas godtyckligt. Om PARTITION BY-satsen anges, kommer rankningsradnumret att återställas för varje partition. I den tidigare skapade tabellen visar frågan nedan hur man använder funktionen ROW_NUMBER rankingfönster för att rangordna StudentScore-tabellraderna efter varje elevs poäng:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Det framgår tydligt av resultatuppsättningen nedan att fönsterfunktionen ROW_NUMBER rangordnar tabellraderna enligt kolumnvärdena Student_Score för varje rad, genom att generera ett unikt nummer för varje rad som återspeglar dess Student_Score-rankning med början från nummer 1 utan dubbletter eller luckor och hantera alla rader som en partition. Du kan också se att dubblettpoängen tilldelas olika rangord slumpmässigt:
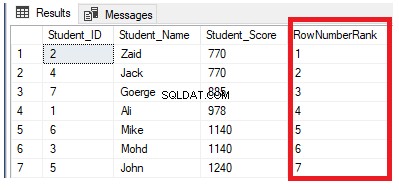
Om vi ändrar den tidigare frågan genom att inkludera PARTITION BY-satsen så att den har mer än en partition, som visas i T-SQL-frågan nedan:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Resultatet kommer att visa att fönsterfunktionen ROW_NUMBER kommer att rangordna tabellraderna enligt kolumnvärdena för Student_Score för varje rad, men den kommer att hantera de rader som har samma Student_Score-värde som en partition. Du kommer att se att ett unikt nummer kommer att genereras för varje rad som återspeglar dess Student_Score-rankning, med början från siffran 1 utan dubbletter eller luckor inom samma partition, och återställer rangnumret när du flyttar till ett annat Student_Score-värde.
Till exempel kommer elever med poäng 770 att rankas inom den poängen genom att tilldela ett rangnummer till det. Men när den flyttas till eleven med poäng 885, kommer startnumret i rangordningen att återställas till att börja igen på 1, som visas nedan:
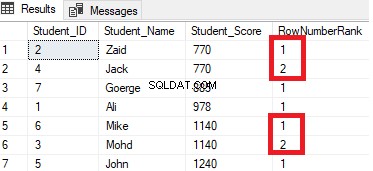
RANK()
Rangeringsfönsterfunktionen RANK() returnerar ett unikt rangnummer för varje distinkt rad inom partitionen enligt ett specificerat kolumnvärde, med början på 1 för den första raden i varje partition, med samma rang för dubbletter av värden och lämnar luckor mellan rangorden.; detta gap visas i sekvensen efter dubblettvärdena. Med andra ord, rankingfönsterfunktionen RANK() beter sig som funktionen ROW_NUMBER() förutom raderna med lika värden, där den kommer att rangordnas med samma rang-ID och generera ett gap efter det. Om vi ändrar den tidigare rankningsfrågan för att använda RANK() rankningsfunktionen:
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreDu kommer att se från resultatet att RANK-fönsterfunktionen kommer att rangordna tabellraderna enligt kolumnvärdena för Student_Score för varje rad, med ett rankningsvärde som återspeglar dess Student_Score från siffran 1, och rangordna raderna som har samma Student_Score med samma rangvärde. Du kan också se att två rader med Student_Score lika med 770 rankas med samma värde och lämnar ett gap, vilket är den missade siffran 2, efter den andra rankade raden. Samma sak händer med de rader där Student_Score är lika med 1140 som rankas med samma värde, vilket lämnar ett gap, vilket är det saknade talet 6, efter den andra raden, som visas nedan:
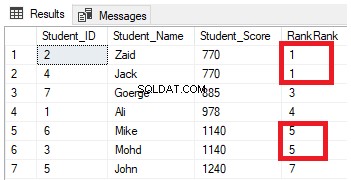
Ändra den tidigare frågan genom att inkludera PARTITION BY-satsen så att den har mer än en partition, som visas i T-SQL-frågan nedan:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreRankningsresultatet kommer inte att ha någon betydelse, eftersom rangordningen kommer att göras enligt Student_Score-värden per partition, och data kommer att delas upp enligt Student_Score-värdena. Och på grund av det faktum att varje partition kommer att ha rader med samma Student_Score-värden, kommer raderna med samma Student_Score-värden i samma partition att rangordnas med ett värde lika med 1. Således, när du flyttar till den andra partitionen, kommer rangordningen att återställas, med början igen med siffran 1, med alla rankningsvärden lika med 1 enligt nedan:
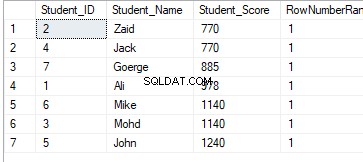
DENSE_RANK()
DENSE_RANK()-rankningsfönsterfunktionen liknar RANK()-funktionen genom att generera ett unikt rangnummer för varje distinkt rad inom partitionen enligt ett specificerat kolumnvärde, med början på 1 för den första raden i varje partition, rangordna raderna med lika värden med samma rangnummer, förutom att den inte hoppar över någon rang och lämnar inga luckor mellan rangorden.
Om vi skriver om den tidigare rankningsfrågan för att använda DENSE_RANK() rankningsfunktionen:
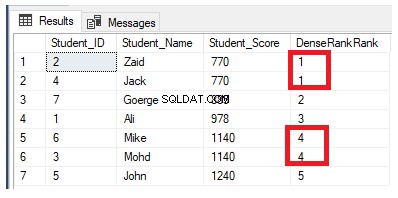
Ändra återigen den föregående frågan genom att inkludera PARTITION BY-satsen så att den har mer än en partition, som visas i T-SQL-frågan nedan:
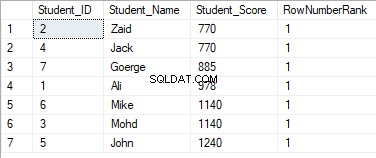
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Rangordningsvärdena kommer inte att ha någon betydelse, där alla rader kommer att rangordnas med värdet 1, på grund av att dubblettvärdena tilldelas samma rangordningsvärde och nollställning av rangstart-id vid bearbetning av en ny partition, som visas nedan:
NTILE(N)
NTILE(N) rankningsfönsterfunktionen används för att fördela raderna i raduppsättningen i ett specificerat antal grupper, vilket ger varje rad i raduppsättningen ett unikt gruppnummer, som börjar med siffran 1 som visar gruppen som denna rad tillhör. till, där N är ett positivt tal, vilket definierar antalet grupper du behöver för att fördela raderna in i.
Med andra ord, om du behöver dela in specifika datarader i tabellen i tre grupper, baserat på specifika kolumnvärden, kommer funktionen NTILE(3) rankingfönster att hjälpa dig att enkelt uppnå detta.
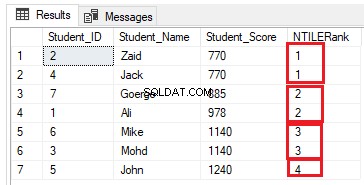
Antalet rader i varje grupp kan beräknas genom att dela upp antalet rader i önskat antal grupper. Om vi ändrar den tidigare rankningsfrågan för att använda NTILE(4) rankningsfönsterfunktion för att rangordna sju tabellrader i fyra grupper som T-SQL-frågan nedan:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Antalet rader bör vara (7/4=1,75) rader i varje grupp. Med funktionen NTILE() kommer SQL Server Engine att tilldela 2 rader till de tre första grupperna och en rad till den sista gruppen, för att få alla rader inkluderade i grupperna, som visas i resultatuppsättningen nedan:
Ändra den tidigare frågan genom att inkludera PARTITION BY-satsen så att den har mer än en partition, som visas i T-SQL-frågan nedan:
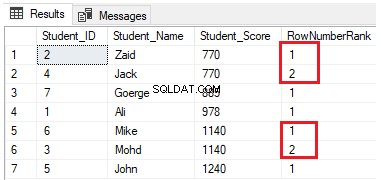
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreRaderna kommer att fördelas i fyra grupper på varje partition. Till exempel kommer de två första raderna med Student_Score lika med 770 att vara i samma partition och kommer att fördelas inom grupperna som rangordnar var och en med ett unikt nummer, som visas i resultatuppsättningen nedan:
Putting All Together
För att få ett tydligare jämförelsescenario, låt oss trunkera föregående tabell, lägga till ytterligare ett klassificeringskriterium, vilket är elevernas klass, och slutligen infoga nya sju rader med hjälp av T-SQL-skriptet nedan:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Efter det kommer vi att rangordna sju rader efter varje elevpoäng, och dela upp eleverna efter deras klass. Med andra ord kommer varje partition att inkludera en klass, och varje klass av elever kommer att rankas enligt deras poäng inom samma klass, med hjälp av fyra tidigare beskrivna rankningsfönsterfunktioner, som visas i T-SQL-skriptet nedan:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOPå grund av att det inte finns några dubbletter av värden kommer fyra rankningsfönsterfunktioner att fungera på samma sätt och returnera samma resultat, som visas i resultatuppsättningen nedan:
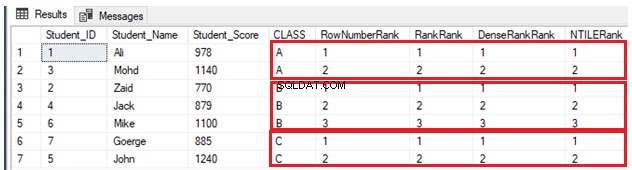
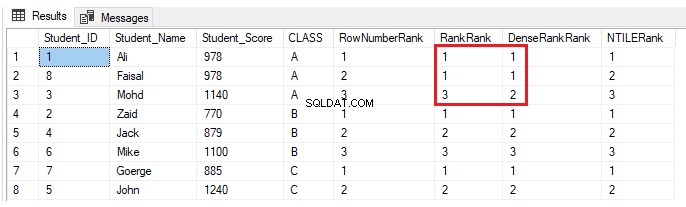
Om en annan elev ingår i klass A med ett poäng, som en annan elev i samma klass redan har, med hjälp av INSERT-satsen nedan:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Ingenting kommer att förändras för rankningsfönsterfunktionerna ROW_NUMBER() och NTILE(). Funktionerna RANK och DENSE_RANK() kommer att tilldela samma rankning för eleverna med samma poäng, med en lucka i rankningarna efter dubblettrankningarna när du använder RANK-funktionen och ingen lucka i rankningarna efter dubblettrankningarna när du använder DENSE_RANK( ), som visas i resultatet nedan:
Praktiskt scenario
Rangordningsfönsterfunktionerna används i stor utsträckning av SQL Server-utvecklare. Ett av de vanliga scenarierna för användning av rankningsfunktioner, när du vill hämta specifika rader och hoppa över andra, med ROW_NUMBER(,) rankningsfönsterfunktionen inom en CTE, som i T-SQL-skriptet nedan som returnerar eleverna med rankningar mellan 2 och 5 och hoppa över de andra:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Resultatet kommer att visa att endast elever med rangen mellan 2 och 5 kommer att returneras:
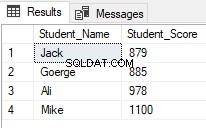
Från och med SQL Server 2012, ett nytt användbart kommando, OFFSET FETCH introducerades som kan användas för att utföra samma tidigare uppgift genom att hämta specifika poster och hoppa över de andra, med hjälp av T-SQL-skriptet nedan:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Hämtar samma tidigare resultat som visas nedan:
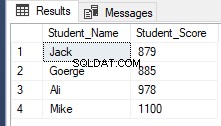
Slutsats
SQL Server förser oss med fyra rankningsfönsterfunktioner som hjälper oss att rangordna de tillhandahållna raderna enligt specifika kolumnvärden. Dessa funktioner är:ROW_NUMBER(), RANK(), DENSE_RANK() och NTILE(). Alla dessa rankningsfunktioner utför rankningsuppgiften på sitt eget sätt, och returnerar samma resultat när det inte finns några dubbletter av värden i raderna. Om det finns ett duplikatvärde inom raduppsättningen kommer RANK-funktionen att tilldela samma rangordnings-ID för alla rader med samma värde, vilket lämnar luckor mellan rangorden efter duplikaterna. Funktionen DENSE_RANK kommer också att tilldela samma ranknings-ID för alla rader med samma värde, men lämnar inte något mellanrum mellan rankningarna efter duplikaterna. Vi går igenom olika scenarier i den här artikeln för att täcka alla möjliga fall som hjälper dig att praktiskt förstå rankningsfönstrets funktioner.
Referenser:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- OFFSET FETCH-klausul (SQL Server Compact)