Du kanske tror att databasunderhåll inte är din sak. Men om du designar dina modeller proaktivt får du databaser som gör livet lättare för dem som ska underhålla dem.
En bra databasdesign kräver proaktivitet, en väl ansedd kvalitet i alla arbetsmiljöer. Om du inte är bekant med termen, är proaktivitet förmågan att förutse problem och ha lösningar redo när problem uppstår – eller ännu bättre, planera och agera så att problem inte uppstår i första hand.
Arbetsgivare förstår att deras anställdas eller entreprenörers proaktivitet är lika med kostnadsbesparingar. Det är därför de värdesätter det och därför uppmuntrar de människor att utöva det.
I din roll som datamodellerare är det bästa sättet att visa proaktivitet att designa modeller som förutser och undviker problem som rutinmässigt plågar databasunderhållet. Eller, åtminstone, som avsevärt förenklar lösningen på dessa problem.
Även om du inte är ansvarig för databasunderhåll, skördar modellering för enkelt databasunderhåll många fördelar. Till exempel hindrar det dig från att bli uppringd när som helst för att lösa datanödsituationer som tar bort värdefull tid som du kan lägga på design- eller modelleringsuppgifterna du tycker så mycket om!
Gör livet enklare för IT-killarna
När vi designar våra databaser måste vi tänka bortom leveransen av en DER och genereringen av uppdateringsskript. När en databas väl sätts i produktion måste underhållsingenjörer ta itu med alla möjliga möjliga problem, och en del av vår uppgift som databasmodellerare är att minimera chanserna att dessa problem uppstår.
Låt oss börja med att titta på vad det innebär att skapa en bra databasdesign och hur den aktiviteten relaterar till vanliga databasunderhållsuppgifter.
Vad är datamodellering?
Datamodellering är uppgiften att skapa en abstrakt, vanligtvis grafisk, representation av ett informationsarkiv. Målet med datamodellering är att exponera attributen för, och relationerna mellan, de enheter vars data lagras i arkivet.
Datamodeller är byggda kring behoven hos ett affärsproblem. Regler och krav definieras i förväg genom input från affärsexperter så att de kan införlivas i utformningen av ett nytt datalager eller anpassas i iterationen av ett befintligt.
Helst är datamodeller levande dokument som utvecklas med förändrade affärsbehov. De spelar en viktig roll för att stödja affärsbeslut och vid planering av systemarkitektur och strategi. Datamodellerna måste hållas synkroniserade med de databaser de representerar så att de är användbara för underhållsrutinerna för dessa databaser.
Vanliga utmaningar för databasunderhåll
Att underhålla en databas kräver konstant övervakning, automatiserad eller på annat sätt, för att säkerställa att den inte förlorar sina fördelar. Bästa metoder för databasunderhåll säkerställer att databaser alltid behåller sina:
- Informationens integritet och kvalitet
- Prestanda
- Tillgänglighet
- Skalbarhet
- Anpassbarhet till förändringar
- Spårbarhet
- Säkerhet
Många datamodelleringstips finns tillgängliga för att hjälpa dig att skapa en bra databasdesign varje gång. De som diskuteras nedan syftar specifikt till att säkerställa eller underlätta underhållet av de ovan nämnda databaskvaliteterna.
Integritet och informationskvalitet
Ett grundläggande mål för bästa praxis för databasunderhåll är att säkerställa att informationen i databasen behåller sin integritet. Detta är avgörande för att användarna ska behålla sin tilltro till informationen.
Det finns två typer av integritet:fysisk integritet och logisk integritet .
Fysisk integritet
Att upprätthålla den fysiska integriteten hos en databas görs genom att skydda informationen från externa faktorer som hårdvara eller strömavbrott. Det vanligaste och allmänt accepterade tillvägagångssättet är genom en adekvat säkerhetskopieringsstrategi som möjliggör återställning av en databas inom rimlig tid om en katastrof förstör den.
För DBA:er och serveradministratörer som hanterar databaslagring är det användbart att veta om databaser kan partitioneras i sektioner med olika uppdateringsfrekvenser. Detta gör att de kan optimera lagringsanvändning och backupplaner.
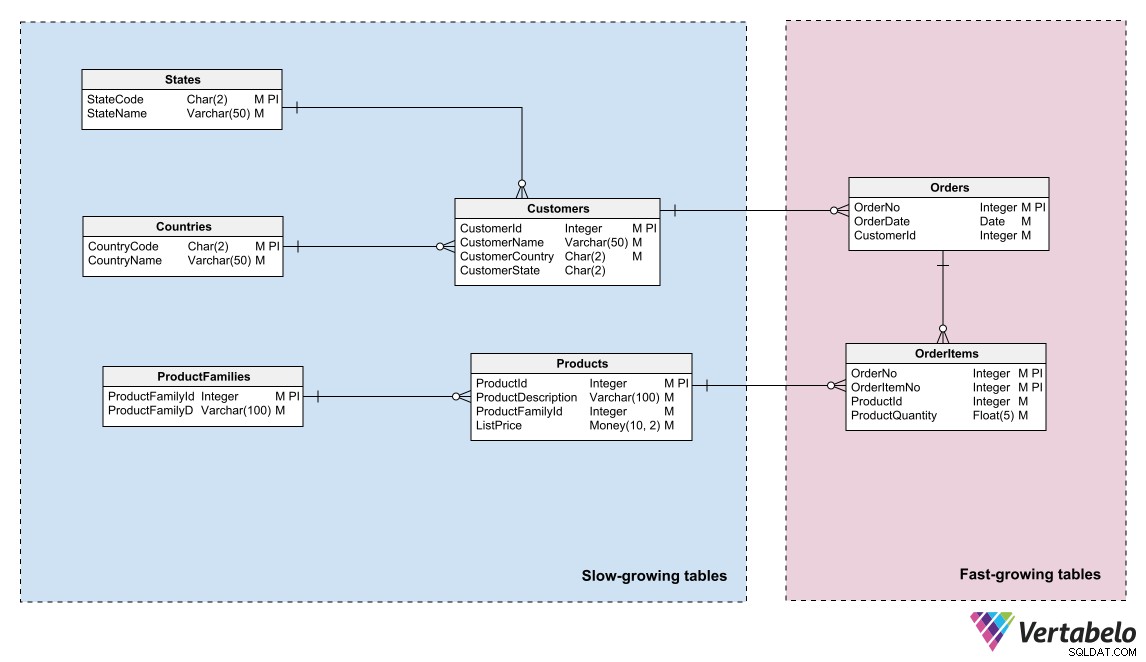
Datamodeller kan återspegla denna uppdelning genom att identifiera områden med olika data "temperatur" och genom att gruppera enheter i dessa områden. "Temperatur" avser den frekvens med vilken tabeller får ny information. Tabeller som uppdateras mycket ofta är de "hetaste"; de som aldrig eller sällan uppdateras är de "kallaste".
 Datamodell för ett e-handelssystem som särskiljer varm, varm och kall data.
Datamodell för ett e-handelssystem som särskiljer varm, varm och kall data. En DBA eller systemadministratör kan använda denna logiska gruppering för att partitionera databasfilerna och skapa olika backupplaner för varje partition.
Logisk integritet
Att upprätthålla den logiska integriteten hos en databas är avgörande för tillförlitligheten och användbarheten av den information den levererar. Om en databas saknar logisk integritet avslöjar applikationerna som använder den inkonsekvenser i data förr eller senare. Inför dessa inkonsekvenser misstror användarna informationen och letar helt enkelt efter mer tillförlitliga datakällor.
Bland databasunderhållsuppgifterna är att upprätthålla informationens logiska integritet en förlängning av databasmodelleringsuppgiften, bara att den börjar efter att databasen har satts i produktion och fortsätter under hela dess livstid. Den mest kritiska delen av detta underhållsområde är att anpassa sig till förändringar.
Ändringshantering
Förändringar i affärsregler eller krav är ett ständigt hot mot databasernas logiska integritet. Du kanske känner dig nöjd med datamodellen du har byggt, med vetskapen om att den är perfekt anpassad till verksamheten, att den svarar med rätt information på alla frågor och att den utelämnar eventuella insättnings-, uppdaterings- eller raderingsavvikelser. Njut av detta ögonblick av tillfredsställelse, eftersom det är kortlivat!
Underhåll av en databas innebär att möta behovet av att göra förändringar i modellen dagligen. Det tvingar dig att lägga till nya objekt eller ändra de befintliga, modifiera relationernas kardinalitet, omdefiniera primärnycklar, ändra datatyper och göra andra saker som får oss modellbyggare att rysa.
Förändringar sker hela tiden. Det kan vara något krav som förklarades fel från början, nya krav har dykt upp eller så har du oavsiktligt infört något fel i din modell (trots allt är vi datamodellerare bara människor).
Dina modeller ska vara lätta att modifiera när ett behov av förändringar uppstår. Det är viktigt att använda ett databasdesignverktyg för modellering som låter dig versionera dina modeller, generera skript för att migrera en databas från en version till en annan och korrekt dokumentera varje designbeslut.
Utan dessa verktyg skapar varje förändring du gör i din design integritetsrisker som dyker upp vid de mest olämpliga tidpunkterna. Vertabelo ger dig all denna funktionalitet och tar hand om att underhålla versionshistoriken för en modell utan att du ens behöver tänka på det.
Den automatiska versionshanteringen som är inbyggd i Vertabelo är en enorm hjälp för att underhålla ändringar i en datamodell.
Ändringshantering och versionskontroll är också avgörande faktorer för att bädda in datamodelleringsaktiviteter i mjukvaruutvecklingens livscykel.
Omfaktorer
När du tillämpar ändringar på en databas som används måste du vara 100 % säker på att ingen information går förlorad och att dess integritet inte påverkas som en konsekvens av ändringarna. För att göra detta kan du använda refactoring-tekniker. De används normalt när du vill förbättra en design utan att påverka dess semantik, men de kan också användas för att korrigera designfel eller anpassa en modell till nya krav.
Det finns ett stort antal refaktoreringstekniker. De används vanligtvis för att ge nytt liv åt äldre databaser, och det finns läroboksprocedurer som säkerställer att ändringarna inte skadar den befintliga informationen. Det har skrivits hela böcker om det; Jag rekommenderar att du läser dem.
Men för att sammanfatta kan vi gruppera refaktoreringstekniker i följande kategorier:
- Datakvalitet: Göra ändringar som säkerställer datakonsistens och sammanhållning. Exempel inkluderar att lägga till en uppslagstabell och migrera till den data som upprepas i en annan tabell och lägga till en begränsning på en kolumn.
- Strukturell: Göra ändringar i tabellstrukturer som inte ändrar modellens semantik. Exempel är att kombinera två kolumner till en, lägga till en ersättningsnyckel och dela upp en kolumn i två.
- Referensintegritet: Tillämpa ändringar för att säkerställa att en refererad rad finns i en relaterad tabell eller att en rad utan referens kan tas bort. Exempel inkluderar att lägga till en främmande nyckelrestriktion i en kolumn och lägga till en icke-nullvärdesrestriktion i en tabell.
- Arkitektonisk: Göra ändringar som syftar till att förbättra interaktionen mellan applikationer och databasen. Exempel inkluderar att skapa ett index, göra en tabell skrivskyddad och kapsla in en eller flera tabeller i en vy.
Tekniker som modifierar modellens semantik, såväl som de som inte ändrar datamodellen på något sätt, anses inte som refactoring-tekniker. Dessa inkluderar att infoga rader i en tabell, lägga till en ny kolumn, skapa en ny tabell eller vy och uppdatera data i en tabell.
Upprätthålla informationskvalitet
Informationskvaliteten i en databas är i vilken grad uppgifterna uppfyller organisationens förväntningar på noggrannhet, giltighet, fullständighet och konsekvens. Att upprätthålla datakvaliteten under hela livscykeln för en databas är avgörande för att dess användare ska kunna fatta korrekta och informerade beslut med hjälp av data i den.
Ditt ansvar som datamodellerare är att säkerställa att dina modeller håller sin informationskvalitet på högsta möjliga nivå. För att göra detta:
- Designen måste följa åtminstone den tredje normala formen så att insättnings-, uppdaterings- eller raderingsavvikelser inte uppstår. Detta övervägande gäller främst databaser för transaktionell användning, där data läggs till, uppdateras och raderas regelbundet. Det gäller inte strikt i databaser för analytisk användning (d.v.s. datalager), eftersom datauppdatering och radering sällan, om någonsin, utförs.
- Datatyperna för varje fält i varje tabell måste vara lämpliga för det attribut de representerar i den logiska modellen. Detta går längre än att korrekt definiera om ett fält är av en numerisk, datum- eller alfanumerisk datatyp. Det är också viktigt att korrekt definiera intervallet och precisionen för värden som stöds av varje fält. Ett exempel:ett attribut av typen Datum implementerat i en databas som ett datum/tid-fält kan orsaka problem i frågor, eftersom ett värde som lagras med dess tidsdel annan än noll kan falla utanför omfånget för en fråga som använder ett datumintervall.
- De dimensioner och fakta som definierar strukturen för ett datalager måste överensstämma med verksamhetens behov. När man designar ett datalager måste modellens dimensioner och fakta definieras korrekt från första början. Att göra ändringar när databasen väl är i drift kommer med en mycket hög underhållskostnad.
Hantera tillväxt
En annan stor utmaning för att underhålla en databas är att förhindra att dess tillväxt oväntat når lagringskapacitetsgränsen. För att hjälpa till med hantering av lagringsutrymme kan du tillämpa samma princip som används i säkerhetskopieringsprocedurer:gruppera tabellerna i din modell efter hur snabbt de växer.
En uppdelning i två områden brukar vara tillräckligt. Placera tabellerna med frekventa radtillägg i ett område, de där rader sällan infogas i ett annat. Genom att ha modellen uppdelad på detta sätt kan lagringsadministratörer partitionera databasfilerna enligt tillväxthastigheten för varje område. De kan fördela partitionerna mellan olika lagringsmedia med olika kapacitet eller tillväxtmöjligheter.
En gruppering av tabeller efter deras tillväxthastighet hjälper till att fastställa lagringskraven och hantera dess tillväxt.
Loggning
Vi skapar en datamodell och förväntar oss att den ska tillhandahålla informationen som den är vid tidpunkten för frågan. Vi tenderar dock att förbise behovet av en databas för att komma ihåg allt som har hänt tidigare om inte användarna specifikt kräver det.
En del av att underhålla en databas är att veta hur, när, varför och av vem en viss databit har ändrats. Det kan handla om saker som att ta reda på när ett produktpris ändrades eller att granska förändringar i journalen för en patient på ett sjukhus. Loggning kan även användas för att korrigera användar- eller applikationsfel eftersom det låter dig återställa informationens tillstånd till en punkt i det förflutna utan att behöva ta till komplicerade procedurer för återställning av säkerhetskopior.
Återigen, även om användarna inte behöver det uttryckligen, är behovet av proaktiv loggning ett mycket värdefullt sätt att underlätta databasunderhållet och visa din förmåga att förutse problem. Att ha loggdata tillåter omedelbara svar när någon behöver granska historisk information.
Det finns olika strategier för en databasmodell för att stödja loggning, som alla lägger till komplexitet till modellen. En metod kallas in-place logging, som lägger till kolumner i varje tabell för att registrera versionsinformation. Detta är ett enkelt alternativ som inte involverar att skapa separata scheman eller loggningsspecifika tabeller. Det påverkar dock modelldesignen eftersom de ursprungliga primärnycklarna i tabellerna inte längre är giltiga som primärnycklar – deras värden upprepas i rader som representerar olika versioner av samma data.
Ett annat alternativ för att behålla logginformation är att använda skuggtabeller. Skuggtabeller är repliker av modelltabellerna med tillägg av kolumner för att registrera loggspårdata. Den här strategin kräver inte att tabellerna i den ursprungliga modellen ändras, men du måste komma ihåg att uppdatera motsvarande skuggtabeller när du ändrar din datamodell.
Ännu en strategi är att använda ett underschema av generiska tabeller som registrerar varje infogning, radering eller modifiering av någon annan tabell.
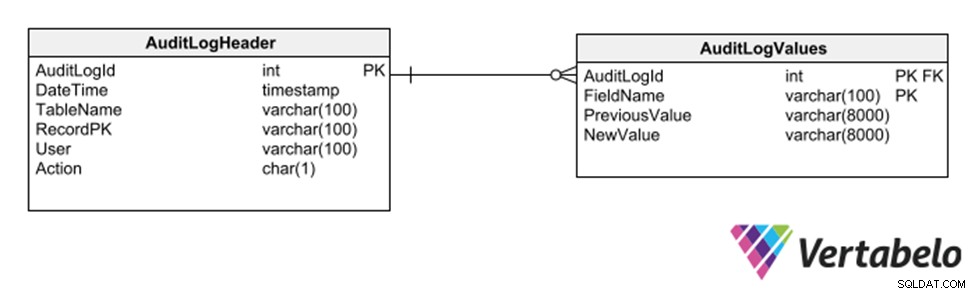
Allmänna tabeller för att hålla ett granskningsspår av en databas.
Denna strategi har fördelen att den inte kräver modifieringar av modellen för att registrera ett revisionsspår. Men eftersom den använder generiska kolumner av typen varchar, begränsar den de typer av data som kan registreras i loggspåret.
Prestandaunderhåll och indexskapande
Praktiskt taget vilken databas som helst har bra prestanda när den precis har börjat användas och dess tabeller bara innehåller ett fåtal rader. Men så snart applikationer börjar fylla den med data, kan prestandan försämras mycket snabbt om försiktighetsåtgärder inte vidtas vid utformningen av modellen. När detta händer ringer DBA:er och systemadministratörer dig för att hjälpa dem att lösa prestandaproblem.
Automatiskt skapande/förslag av index på produktionsdatabaser är ett användbart verktyg för att lösa prestandaproblem "i stundens hetta." Databasmotorer kan analysera databasaktiviteter för att se vilka operationer som tar längst tid och var det finns möjligheter att snabba upp genom att skapa index.
Det är dock mycket bättre att vara proaktiv och förutse situationen genom att definiera index som en del av datamodellen. Detta minskar avsevärt underhållsinsatser för att förbättra databasens prestanda. Om du inte är bekant med fördelarna med databasindex föreslår jag att du läser allt om index, och börjar med det allra grundläggande.
Det finns praktiska regler som ger tillräcklig vägledning för att skapa de viktigaste indexen för effektiva frågor. Den första är att generera index för den primära nyckeln i varje tabell. Praktiskt taget varje RDBMS genererar automatiskt ett index för varje primärnyckel, så du kan glömma den här regeln.
En annan regel är att generera index för alternativa nycklar till en tabell, särskilt i tabeller för vilka en surrogatnyckel skapas. Om en tabell har en naturlig nyckel som inte används som en primärnyckel, gör frågor om att sammanfoga den tabellen med andra sannolikt det med den naturliga nyckeln, inte surrogatet. Dessa frågor fungerar inte bra om du inte skapar ett index på den naturliga nyckeln.
Nästa tumregel för index är att generera dem för alla fält som är främmande nycklar. Dessa fält är utmärkta kandidater för att skapa kopplingar till andra tabeller. Om de ingår i index används de av frågetolkare för att påskynda exekvering och förbättra databasprestanda.
Slutligen är det en bra idé att använda ett profileringsverktyg på en iscensättnings- eller QA-databas under prestandatester för att upptäcka eventuella möjligheter att skapa index som inte är uppenbara. Att införliva indexen som föreslås av profileringsverktygen i datamodellen är oerhört användbart för att uppnå och bibehålla prestanda för databasen när den väl är i produktion.
Säkerhet
I din roll som datamodellerare kan du hjälpa till att upprätthålla databassäkerhet genom att tillhandahålla en solid och säker bas för att lagra data för användarautentisering. Tänk på att denna information är mycket känslig och får inte utsättas för cyberattacker.
För att din design ska förenkla underhållet av databassäkerhet, följ de bästa metoderna för att lagra autentiseringsdata, den främsta är att inte lagra lösenord i databasen ens i krypterad form. Genom att bara lagra dess hash istället för lösenordet för varje användare kan en applikation autentisera en användarinloggning utan att skapa någon risk för lösenordsexponering.
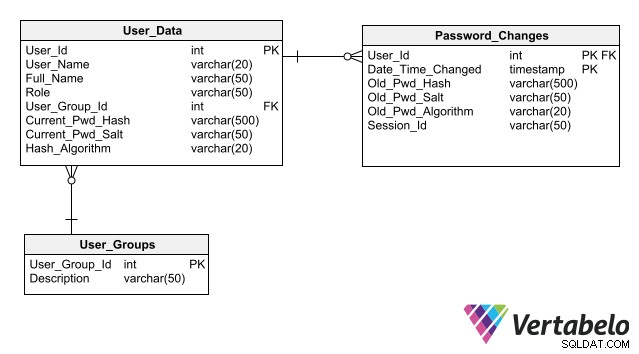
Ett komplett schema för användarautentisering som inkluderar kolumner för lagring av lösenordshashar.
Vision för framtiden
Så skapa dina modeller för enkelt databasunderhåll med bra databasdesigner genom att ta hänsyn till tipsen ovan. Med mer underhållsbara datamodeller ser ditt arbete bättre ut och du får uppskattning av DBA:er, underhållsingenjörer och systemadministratörer.
Du investerar också i sinnesro. Att skapa databaser som är lätta att underhålla innebär att du kan ägna din arbetstid åt att designa nya datamodeller, snarare än att springa runt och patcha databaser som inte levererar korrekt information i tid.