I denna tid av hård konkurrens är jobbportaler inte bara plattformar för att publicera och hitta jobb. De utnyttjar avancerade tjänster och funktioner för att hålla sina kunder engagerade. Låt oss dyka in i några avancerade funktioner och bygga en datamodell som kan hantera dem.
Jag förklarade de grundläggande funktionerna som behövs för en jobbportalwebbplats i en tidigare artikel. Modellen visas nedan. Vi kommer att betrakta denna modell som en bas, som vi kommer att ändra för att möta de nya kraven. Låt oss först överväga vilka dessa krav (eller förbättringar) bör vara.
Vad lägger vi till i onlinejobbportalens datamodell?
Kortfattat kommer vi att lägga till fyra förbättringar av vår tidigare datamodell:
- En personlig instrumentpanel för arbetssökande. Detta håller reda på alla deras jobbansökningar och ger realtidsuppdateringar om eventuella statusändringar (d.v.s. en ansökan ändras från att ha tagits emot till att bli granskad).
- En profilinstrumentpanel. Detta visar vem som besöker en arbetssökandes profil och hur många gånger deras CV laddades ned under den senaste dagen, veckan eller månaden.
- Hantering av betaltjänster. Jobbportaler erbjuder ofta tjänster som expertförberedelser av CV, hantering av sociala profiler, karriärrådgivning, etc. Våra nya funktioner kommer att kunna stödja erbjudanden mot betalning.
- Hantera formulär före ansökan. När sökande skickar in en jobbansökan kan de bli ombedda att fylla i ett kort frågeformulär relaterat till arbetstider, platser och bakgrundskontroller. Vi kommer att bygga in sätt så att det här formuläret kan anpassas av rekryterare och för att frågor och svar kan fångas upp av systemet.
Förbättring # 1:Personlig instrumentpanel
Frågor att besvara: Vad är aktuell status för en inskickad ansökan? Är den nominerad för en intervju? Har den ens visats ännu?
Vi kan hålla reda på jobbansökningar genom att ange job_application_status_id kolumnen i job_post_activity tabell. Den här kolumnen innehåller den aktuella statusen för en jobbansökan. Vi måste skapa en annan tabell, job_application_status , för att hålla alla möjliga applikationsstatusar. Vissa statusar kan vara "skickat", "under granskning", "arkiverad", "avvisad", "shortlistad för intervju", "under rekryteringsprocess" och så vidare.
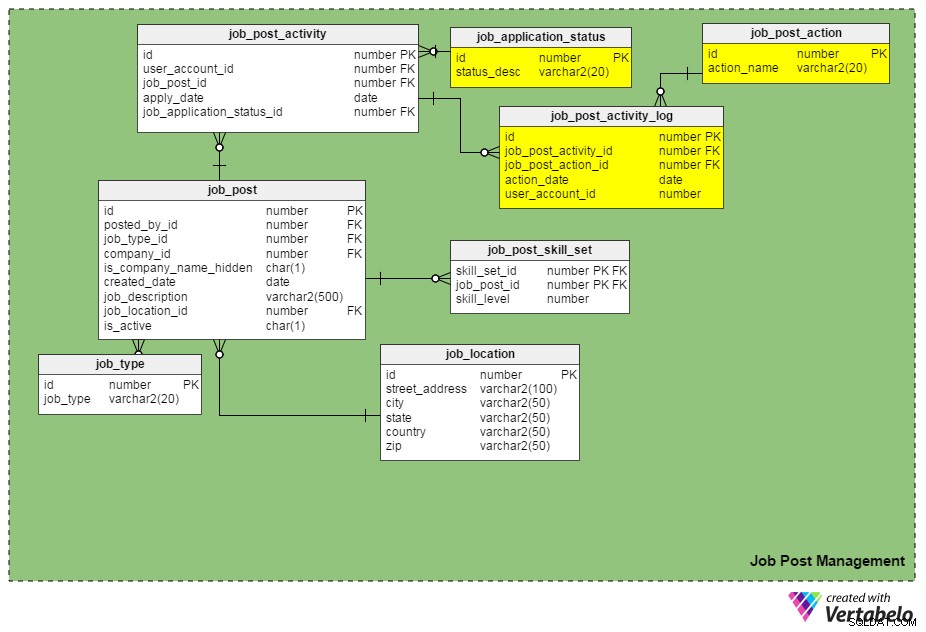
Ytterligare en ny tabell, job_post_activity_log , lagrar information om alla åtgärder som utförts på jobbansökningar, vem som utförde åtgärden och när den utfördes. Den här tabellen innehåller följande kolumner:
id– Tabellens primärnyckel.job_post_activity_id– Applikations-ID som åtgärden utförs på.job_post_action_id– ID för den utförda åtgärden. Detta är en främmande nyckel som länkar tilljob_post_actiontabell. De typer av åtgärder som vi kan lagra här inkluderar "skickat", "visat", "intervjut", "skrivet prov taget", "erbjudande pågår", "erbjudande skickat", "erbjudande accepterat" osv.action_date– Datumet då en åtgärd utfördes.user_account_id– ID för personen som utförde åtgärden.
Är "job_post_action" identisk med "job_application_status"? Hur är de olika?
De verkar identiska till en början, men de är verkligen olika. Det finns giltiga skäl till att vi behöver två liknande fält:
- En kandidat intervjuas av två eller flera personer separat. I det här fallet förblir statusen för jobbansökan densamma (d.v.s. ”genomgår rekryteringsprocess”) tills alla intervjuomgångar är klara. Uppgifter för varje enskild intervjuare infogas dock i
job_post_activity_logtabell, och de har åtgärden "intervjuad". - En ansökan kan ses av mer än en rekryterare i samma företag. Genom att använda dessa två attribut förlorar du inte en sökandes information.
- Att lämna ett erbjudande till en utvald kandidat är föremål för flera godkännanden (dvs godkännande från ekonomiteam, godkännande från rekryteringsavdelningschef, och så vidare). I det här fallet förblir en jobbansökans status "erbjudande under granskning", men databasen kan logga vilka godkännanden som har kommit igenom och vilka som inte har gjort det med hjälp av
job_post_activity_logtabell.
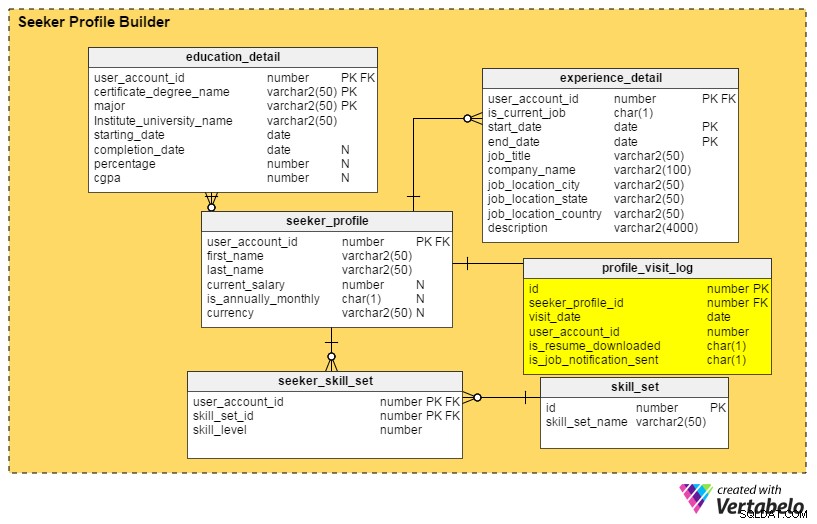
Förbättring # 2:En profilinstrumentpanel
Frågor att besvara: Vem har hittat min profil nyligen? Hur många gånger sågs den av rekryterare under den senaste månaden, veckan eller dagen? Har rekryterare från toppföretag tittat på min profil?
Svaren på alla dessa frågor finns i profile_visit_log tabell. Den här tabellen samlar all profilbesöksdata, inklusive vem som besökte en profil, när den visades och så vidare. Kolumnerna i denna tabell är:
id– Tabellens primärnyckel.seeker_profile_id– Vilken profil besöktes.visit_date– När profilen öppnades.user_account_id– Vem såg profilen.is_resume_downloaded– En flaggkolumn som anger om det relaterade CV:t laddades ner under besöket. Den här kolumnen hjälper oss att ta reda på hur många gånger ett CV laddas ner av rekryterare.is_job_notification_sent– Ytterligare en flaggkolumn, den här som anger om ett jobbmeddelande har skickats till profilens ägare.
Förbättring # 3:Hantering av betaltjänster
Fråga att svara: Hur kan onlineportaler utnyttja ytterligare tjänster mot betalning?
Förutom en plattform för att lägga ut och söka jobb, tillhandahåller många onlineportaler andra tjänster, som expertuppbyggnad av CV, karriärrådgivning, etc. De erbjuder också produkter för att hjälpa arbetssökande att hitta sitt drömjobb i sin drömstad. Till exempel erbjuder en av de ledande jobbsajterna en produkt som håller din profil högst upp på rekryterarnas listor så att du kan få fler intervjuerbjudanden. De flesta av dessa produkter eller tjänster är tillgängliga på abonnemangsbasis. När en användare köper en tjänst eller produkt betalar de under en viss tidsperiod (dvs. en månad, tre månader, ett år) för användningen av den produkten eller tjänsten.
När jag tittade på dessa jobbportaler märkte jag att knappt några produkter eller tjänster erbjuds enskilt. För det mesta paketeras flera produkter och tjänster till ett paket, och detta paket erbjuds antingen till arbetssökande eller rekryterare.
Med hänsyn till alla dessa punkter kom jag på följande datamodell för att integrera betaltjänster och produkter i vår befintliga jobbwebbplats online:
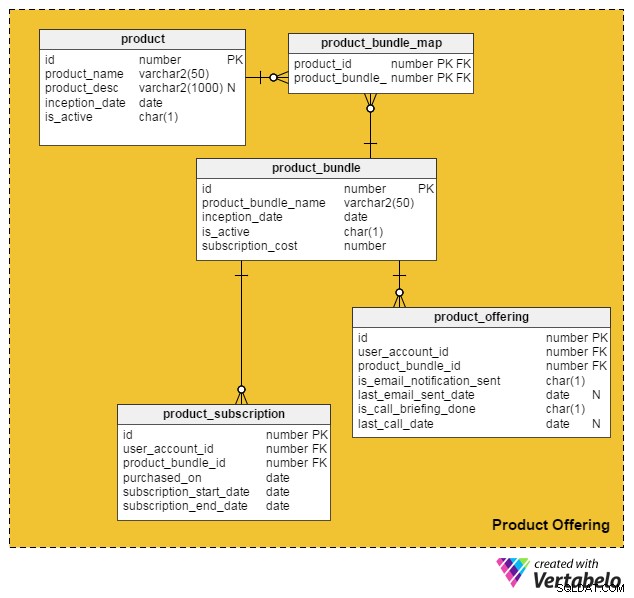
product Tabellen innehåller information om enskilda produkter. (Vi kommer att hänvisa till både produkter och tjänster som "produkter"). Kolumnerna i denna tabell är:
id– Den primära nyckeln i denna tabell, som ger ett unikt ID för varje produkt som erbjuds på vår portal.product_name– Innehåller produktens namn.product_desc– Lagrar en kort beskrivning av produkten.inception_date– Datumet då en produkt introducerades.is_active– Om en produkt är aktiv eller inte.
Eftersom produkter och tjänster kan klubbas ihop i en bunt och erbjudas till kunder, skapade jag product_bundle tabell för att lagra register över alla sådana buntar. Attributen är:
id– Den primära nyckeln i tabellen, som ger ett unikt ID för varje produktpaket.product_bundle_name– Lagrar paketets namn.inception_date– Datumet då paketet introducerades.is_active– Anger om ett paket är aktivt eller inte.subscription_cost– Lagrar det begärda priset för paketet.
Kan en enskild produkt erbjudas till kunder?
Ja. I denna datamodell kan en enskild produkt vara sitt eget "paket". Följande tabeller hanterar detta och några andra viktiga funktioner.
product_bundle_map tabell lagrar en lista över alla produkter som ingår i ett paket. Dess attribut är självförklarande.
Nästa tabell, product_subscription , kommer till spel när kunder prenumererar på produktpaket. Den registrerar detaljerna om vilka kunder som har skrivit till vilka paket. Kolumnerna i denna tabell är:
id– Tabellens primärnyckel.user_account_id– Användaren som köpte paketet.product_bundle_id– Produktpaketet köpt av användaren.purchased_on– Inköpsdatum.subscription_start_date– Datumet då prenumerationen börjar. Observera att produktens inköpsdatum och prenumerationens startdatum kan skilja sig åt. Vi har alltså två olika kolumner för dessa.subscription_end_date– När prenumerationen upphör.
Slutbordet, product_offering , används främst för marknadsföring. Vanligtvis analyserar jobbportaler användarnas senaste aktiviteter (både arbetssökande och rekryterare) och bestämmer sedan vilka produkter som kommer att vara fördelaktiga för vilka användare. De använder sedan mejl eller telefonsamtal för att kontakta kunder med utvalda erbjudanden. Kolumnerna för denna tabell är:
id– Tabellens primärnyckel.user_account_id– Användaren som jobbportalen riktar sig till.product_bundle_id– Produktpaketet som portalmarknadsförarna har matchat till användaren.is_email_notification_sent– Om ett e-postmeddelande angående produkterbjudandet har skickats.last_email_sent_date– När användaren senast fick ett produktmail från marknadsföringsteamet. Det är vanligt att marknadsförare skickar flera aviseringar till en användare och skickar andra meddelanden med jämna mellanrum. Den här kolumnen lagrar datumet när det senaste meddelandet skickades.is_call_briefing_done– Om kunden fick ett telefonsamtal som informerade dem om en produkt.last_call_date– Datumet för det senaste telefonsamtalet. Det kan göras flera samtal (uppföljningssamtal) till kunder.
Förbättring # 4:Hantering av formulär före ansökan
Fråga att svara: Hur kan en rekryterare få ett anpassat samtyckesformulär fyllt av alla potentiella jobbkandidater?
Många gånger, arbetssökande att svara på specifika frågor när de ansöker om en tjänst. Detta inkluderar vanligtvis saker som att samtycka till en brottslig bakgrundskontroll. Det finns dock olika andra typer av samtycken som kan behövas. Till exempel kan ett jobb inom marknadsföring kräva mycket resor; jobb inom outsourcing av affärsprocesser (BPO) kan kräva att anställda arbetar kyrkogårdsskift (dvs. sent på natten). Dessa behandlas i föransökningsformulär.
Det är alltid bäst att inhämta samtycke när arbetsansökan skickas in. På så sätt kommer kandidater som inte är villiga att uppfylla dessa krav inte att ansöka om jobbet.
Innan jag hoppar till datamodellen, låt mig först lyfta fram några grundläggande fakta om samtyckesformulär:
- Ett jobbinlägg kan ha mer än ett samtyckesformulär.
- Varje samtyckesformulär har olika frågor kopplade till olika avsnitt.
- En fråga kan ställas in som obligatorisk eller valfri, beroende på hur frågan är taggad i formuläret. En fråga kan vara valfri i en form och obligatorisk i en annan.
- Varje fråga kan besvaras som antingen (1) ja, (2) nej eller (3) inte tillämplig.
- Alla svar kommer att spelas in.
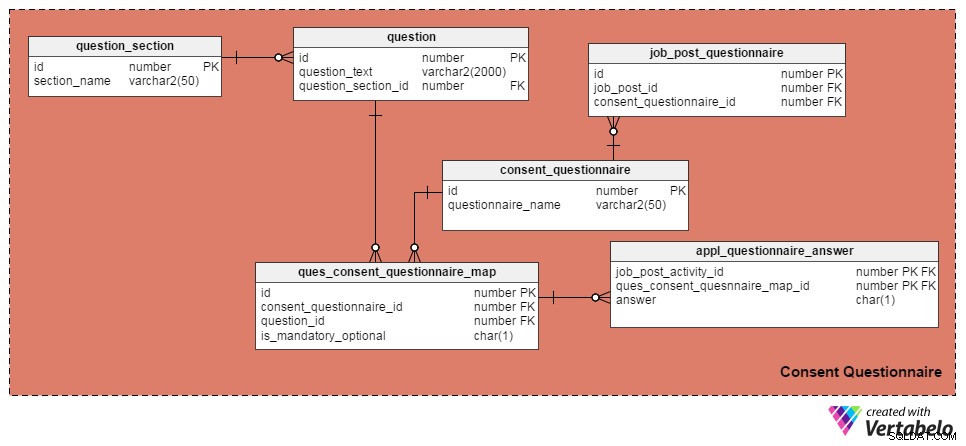
Jag har använt följande fyra tabeller för att hantera frågor och samtyckesformulär. Den första, question tabell, innehåller en lista med frågor. Den har dessa attribut:
id– Tabellens primärnyckel, som ger ett unikt ID-nummer till varje fråga.question_text– Lagrar själva frågetexten.question_section_id– Avsnittet där frågan visas. (T.ex. "Har du arbetat med mjukvaruutveckling i minst fem år?" skulle visas i avsnittet "Arbetserfarenhet".) Detta är en främmande nyckelkolumn som hänvisas tillquestion_sectiontabell.
question_section tabell lagrar avsnittsinformation. Det är ett sätt att gruppera frågor som rör samma ämne. Bortsett från id attribut, som är den primära nyckeln för tabellen, är det enda attributet section_name , vilket är självförklarande.
consent_questionnaire tabellen innehåller samtyckesformulärnamn. Dess två attribut är också självförklarande.
ques_consent_questionnaire_map tabell är kärnan i detta ämnesområde. Alla andra tabeller i detta ämnesområde är direkt eller indirekt kopplade till det. Dess syfte är att hålla en lista över frågor taggade till samtyckesformulär. Kolumnerna i denna tabell är:
id– Den här tabellens primärnyckel.consent_questionnaire_id– Samtyckesformulärets ID-nummer.question_id– Frågans ID-nummer.is_mandatory_optional– Anger om frågan är obligatorisk eller valfri för ett givet samtyckesformulär. En fråga kan vara en del av flera samtyckesformulär, men det kan vara obligatoriskt i vissa och valfritt i andra. Det är den enda anledningen till att behålla denna kolumn här istället för att ha den iquestiontabell.
I de följande tabellerna diskuterar vi formulär för samtycke till individuella jobbinlägg och registrerar kandidaternas svar. Låt oss börja med job_post_questionnaire tabell, som lagrar information om vilka samtyckesformulär som ingår i ett jobbinlägg. Det kan finnas ett eller flera samtyckesformulär taggade med ett jobbinlägg. Kolumnerna i denna tabell är:
id– Tabellens primärnyckel.job_post_id– Anger vilket jobbinlägg samtyckesformuläret är taggat med.consent_questionnaire_id– Samtyckesformuläret taggat till ett jobbinlägg.
Nästa, appl_questionnaire_answer Tabellen loggar de individuella svaren på varje samtyckesformulärsfråga som fylls i av de sökande. Kolumnerna i denna tabell är:
job_post_activity_id– En kolumn för främmande nyckel som refereras frånjob_post_activitytabell. Den lagrar information om kandidaten som har svarat på frågan.quest_consent_quesnnaire_map_id– En annan kolumn för främmande nyckel hänvisade tillquest_consent_questionnaire_maptabell. Den lagrar vilken fråga från vilket samtyckesformulär som besvaras.answer– Den arbetssökandes egentliga svar. Jag har behållit det som en CHAR(1)-kolumn eftersom alla frågor i vår modell kan besvaras som 'Ja' (svar ='Y'), 'Nej' (svar ='N') eller 'Ej tillämpligt' (svar ='X').
Den nya och förbättrade onlinejobbportaldatamodellen
Du kan se den färdiga datamodellen nedan.
Vad skulle du lägga till?
Kan du tänka dig några andra funktioner att lägga till i vår jobbportal online? Vänligen dela dina åsikter i kommentarsfältet.