Det finns ett antal sätt att kontakta någon nuförtiden, eller hur?
Vi har olika telefoner:mobil och fast telefon, privat och jobb. Vi har olika adresser – bostäder, post, fakturering, företag, etc. – och förmodligen flera e-postadresser också. Glöm inte Skype och olika meddelandeappar. Lägg nu till LinkedIn och Facebook – som förresten båda har sina egna meddelandeelement.
För inte så länge sedan fanns många av dessa inte. Så du kan i stort sett garantera att vi om några år kommer att ha något nytt sätt att kontakta människor och organisationer.
Kan vi modellera all denna kontaktinformation på ett sådant sätt att vi inte behöver ändra vår databasdesign när "det senaste" kommer? Läs vidare för att ta reda på...
Partykontaktpunktsmodellen
Med ett ord, ja. Databaser kan utformas för att rymma information som vi inte ens har ännu.
Jag ska hoppa direkt in och visa dig lösningen, sedan ska jag beskriva hur bitarna fungerar tillsammans. Jag kommer att kalla de olika sätten att kontakta parter för kontaktpunkter , även om jag har sett kontaktmetoder och till och med kontaktplatser används.
Fysiskt kommer alla dessa kontaktpunkter att lagras i en enda tabellkolumn, contact_point.contact_value . Tänk på ett telefonnummer, en e-postadress eller en webbadress (URL) så förstår du varför vi kan lagra dem alla här; de är bara strängar (varchars) på den här nivån. Differentieringen finns i metadata. Det enda undantaget från detta är postadressen, som kommer att beskrivas mer i detalj senare.
De gula tabellerna till vänster innehåller metadata och de blå tabellerna till höger innehåller affärsdata.
De viktigaste kategorierna
Även om vi har många sätt att kontakta någon, faller dessa sätt faktiskt in i ett litet antal kategorier eller typer. Du ser vad jag menar när du tittar på listan nedan:
| Typ av kontaktpunkt |
|---|
| Telefonnummer (fast telefon) |
| Mobilnummer |
| Faxnummer |
| E-postadress |
| Postadress |
| Webbadress |
| Personsökare |
På sätt och vis är dessa fysiskt olika. Självklart kan du använda en mobiltelefon för att ringa en fast telefon eller en annan mobil. När det kommer till röstsamtal mellan fasta telefoner och mobiler är skillnaden inte så viktig. Ändå är det mer sannolikt att vi skickar ett sms (SMS) till en mobil än en fast telefon.
Men det är inte troligt att du medvetet röstsamtal ett faxnummer. När allt kommer omkring, vad ska du säga till den när du hör den, förutom "Hoppsan, fel nummer"? Du är naturligtvis mycket mer benägen att ringa med en annan fax, oavsett om den är fysisk eller emulerad. Du skulle inte heller skicka ett brev till fast telefon eller försöka ringa ett röstsamtal till en postadress.
Det är viktigt att vi särskiljer dessa typer, eftersom vi interagerar olika med dem. Detta gäller särskilt om din applikation har någon form av integration med kommunikationstjänster. Den måste veta vilken typ den ska interagera med.
Hur parterna använder kontaktpunkter
Detta är nog lite mer intuitivt, lite mer i linje med hur vi tänker kring kontakttyper. Här är en längre lista (men inte en uttömmande!) som hjälper dig att få en känsla för dessa typer:
| Typ av partskontakt (typ kontaktpunkt) |
|---|
| Konferenslinje (telefonnummer) |
| Faktureringsadress (Postadress) |
| Leveransadress (Postadress) |
| Direktlinje (telefonnummer) |
| Semester-/semesteradress (postadress) |
| Semester-/semestertelefon (telefonnummer) |
| Hemadress (Postadress) |
| Hemtelefon (telefonnummer) |
| Hemtelefon/fax (telefonnummer) |
| LinkedIn-profil (webbadress) |
| Huvudadress (Postadress) |
| Huvudmail (e-postadress) |
| Huvudfax (faxnummer) |
| Huvudtelefon (telefonnummer) |
| Huvudwebbplats (webbadress) |
| Personlig e-post (e-postadress) |
| Personligt fax (faxnummer) |
| Personlig mobil (mobilnummer) |
| Personlig personsökare (personsökare) |
| Personlig webbplats (webbadress) |
| Sekundär adress (postadress) |
| Sekundär telefon (telefonnummer) |
| Profil för sociala medier (webbadress) |
| Arbetsadress (postadress) |
| Arbets-e-post (e-postadress) |
| Arbetsfax (faxnummer) |
| Arbetsmobil (mobilnummer) |
| Arbetstelefon (telefonnummer) |
Postadressen – ett specialfall
Alla dessa kontaktpunktstyper lagras i ett enda fält, med undantag för en postadress. Detta kräver normalt ett antal rader (eller fält).
Det finns en bloggartikel här som föreslår ett enkelt, språkagnostiskt sätt att lagra postadresser. Om dina krav är ganska grundläggande – t.ex. att skriva ut adressetiketter i stort sett när de skrivs in i systemet – detta tillvägagångssätt kommer sannolikt att räcka. Om dina behov är mer sofistikerade måste du förmodligen utveckla en annan lösning.
För att få en uppfattning om hur komplex adressering kan vara, ta en snabb titt på detta schema för British Standard BS7666 adresstyper. Standarden omfattar ett antal delar som täcker gatutidningar, mark- och fastighetstidningar och utlämningsställen. Den gör ingen skillnad mellan kommersiella fastigheter eller bostadsfastigheter; mellan ockuperad, utvecklad eller ledig mark; mellan stads- eller landsbygdsområden; eller mellan postadresserbara enheter och icke-postadresserbara enheter s såsom kommunikationsmaster (torn). För att uppnå detta introducerar den termer som de flesta av oss förmodligen inte är bekanta med, till exempel Primary Addressable Object (PAO), som är namnet som ges till ett adresserbart objekt som kan adresseras utan referens till ett annat adresserbart objekt. Bekanta exempel på PAO är ett byggnadsnamn eller ett gatunummer. Ett sekundärt adresserbart objekt (SAO) ges till alla adresserbara objekt som adresseras med hänvisning till en PAO. Det här kan vara första våningen i en namngiven byggnad.
För att ge oss en visualisering av detta, omvandlade jag det snabbt till ett UML-modelleringsverktyg. Det här är vad vi får:
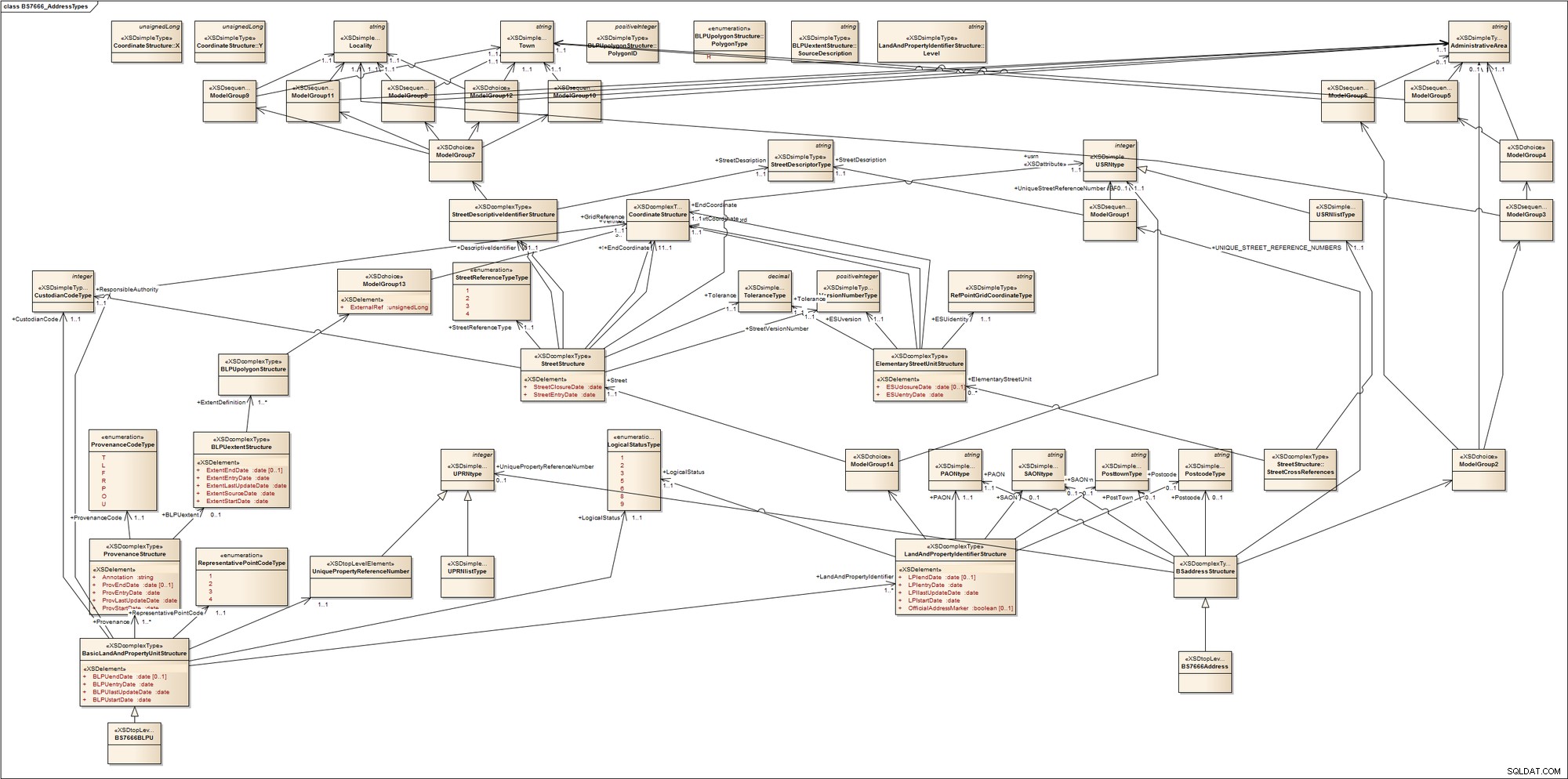
Min poäng är att det kan bli ganska komplicerat och rörigt; adressering i vissa domäner kan verkligen vara mycket komplex.
Om du skulle platta ut detta till en enda relationstabell, skulle du få något i stil med följande:
Även om detta fångar BS7666-adresskomponenter, berättar det inte hur modellen fungerar. All relationslogik i XML-schemat göms undan i applikationslogiken.
Dessa två diagram representerar två datamodelleringsextremer . Men finns det en medelväg att modellera adresser?
Det är verkligen möjligt att ha en relativt enkel adressmodell som är flexibel och konfigurerbar.
Adresskomponenter
En adresskomponent är vanligtvis en rad på en adressetikett, eller snarare en typ av rad på en adressetikett. Den typ av komponenter som vi vanligtvis använder för adresser i Storbritannien listas i följande tabell:
| Adresskomponenttyp |
|---|
| Adressat |
| Område |
| Byggnadens namn |
| Byggnadsnummer |
| Land |
| Län |
| Avdelningens namn |
| Beroende ort |
| Beroende genomfartsnamn |
| Dubbel beroende lokalitet |
| Internationellt postnummer |
| Nivå |
| Ort |
| Mailsort SSC |
| Organisationens namn |
| PAO-slutnummer |
| PAO-slutsuffix |
| PAO-startnummer |
| PAO-startsuffix |
| PAO-text |
| Postbox |
| Postnummer |
| Poststad |
| Postnummer |
| Postnummertyp |
| SAO-slutnummer |
| SAO-slutsuffix |
| SAO-startnummer |
| SAO-startsuffix |
| SAO-text |
| Gata |
| Gatubeskrivning |
| Underbyggnadens namn |
| Gårvägsnamn |
| Stad |
Du kan ha tre eller fyra adressrader, plus postort och postnummer. Men svårigheten du kommer att stöta på är att identifiera vad dessa rader faktiskt innehåller när det gäller – t.ex. vid kartläggning av data mellan system. När du utför dataprofilering kommer du att upptäcka att adressrad 3 ibland innehåller en beroende ort, men ibland ett län eller ort. Nu är du inne på naturlig språkbehandling (NLP); du måste känna igen skillnaden mellan ort och län. Och permutationerna multipliceras när du lägger till fler länder.
Så vi måste definiera alla adresskomponenter för alla länder vi är verksamma i.
Adressformat
Adressformat består av två delar:en rubrik och dess detalj. Rubriken är i princip namnet eller titeln som adressformatet har är känd av. Exempel kan vara:
| Typ av adressformat |
|---|
| Generisk 3-rads |
| Generisk 5-rads |
| British Forces Post Office (BFPO) |
| Internationellt |
| Postkontorsadress (PAF) |
| USA Adress |
| Fransk adress |
Med Storbritanniens Full Post Office Address Format (PAF) som exempel definierar vi följande adressformatkomponenter:
| Format | Komponent | Sekvens | Är obligatoriskt? |
|---|---|---|---|
| PAF | Adressatör | 1 | N |
| PAF | Organisationens namn | 2 | N |
| PAF | Avdelningens namn | 3 | N |
| PAF | Postbox | 4 | N |
| PAF | Byggnadens namn | 5 | N |
| PAF | Underbyggnadens namn | 6 | N |
| PAF | Byggnadsnummer | 7 | N |
| PAF | Gårväg | 8 | N |
| PAF | Gata | 9 | N |
| PAF | Dubbel beroende ort | 10 | N |
| PAF | Beroende ort | 11 | N |
| PAF | Poststad | 12 | Y |
| PAF | Postnummer | 13 | Y |
Vår applikation läser denna metadata och visar adresskomponenterna i rätt ordning. När adressfångst krävs berättar metadata för oss om adresskomponenten är obligatorisk eller inte.
Oftare begär vår applikation postnumret från slutanvändaren och söker upp motsvarande värden och fyller i adresskomponenterna automatiskt. Vissa applikationer tillåter användaren att redigera adressen; andra [irriterande] gör det inte!
Det visas inte i PDM, men om din organisation verkar internationellt kan du definiera en många-till-många-relation mellan address_format_type och country så att rätt adressformat (baserat på användarens land) presenteras för slutanvändaren (party ).
När och endast när contact_point är en postadress contact_point_type , måste den ha en relation till en adressformat_typ. Omvänt följer det att icke-postadresser aldrig har en relation till en address_format_type . Dessutom måste formatet förbli fast under contact_points livstid , annars introducerar du möjligheten för dataintegritetsproblem. (För att detta inte ska vara fallet , målet address_format_components måste vara en delmängd av källkoden address_format_components ).
Kolumnen contact_value har ingen betydelse för en postadress eftersom värdena lagras i enddress_line.line_content . Omvänt, contact_value är obligatoriskt för alla andra contact_point_types . I princip contact_point.contact_value och address_line.line_content utesluter varandra.
Många-till-många-relationen mellan part och kontaktpunkt
Du kan tänka på contact_point (plus address_line ) som innehåller värdena och party_contact som definierar användningen. Detta tillåter en enda contact_point att ha flera användningsområden . Vår hemadress [postadress] kan också vara vår faktureringsadress och leveransadress, beroende på sammanhanget.
Hittills har berättelsen antagit att en part äger en viss contact_point . Men datamodellen påtvingar inte denna äganderegel! Det gör ingen som helst sådan begränsning. Det finns en annan möjlighet som finns med denna design:flera parter för samma kontaktpunkter.
Du måste överväga konsekvenserna noggrant innan du ger dig ut på den här vägen.
Här är ett exempel. I Storbritannien anställer Awarding Organizations (AOs) i allmänhet lärare som examinatorer. En lärare har två relationer:en med skolan där han eller hon arbetar och en annan med AO som examinator. Skolan kommer att ha en bank med contact_points med olika telefonnummer och eventuellt en eller flera postadresser. Dessa kommer att vara saker som skolans huvudadress (postadress), huvudsaklig e-postadress (e-postadress), huvudfax (faxnummer) och huvudtelefon (telefonnummer).
Det är fullt möjligt att vår examinator kan använda samma contact_points som hans eller hennes skola, men han eller hon kommer att använda party_contact att definiera dem som arbetsrelaterade. Om skolans huvudtelefonnummer ändras uppdateras lärarens arbetsnummer automatiskt, vilket är ganska snyggt.
Om du går den här vägen måste du definiera på applikationsnivå vilken part eller vilka parter som har tillåtelse att uppdatera contact_points .
Ett snabbt ord om prestanda
De gula metadatatabellerna kommer ständigt att användas av frågor. Följaktligen kommer de sannolikt att finnas kvar i minnet. På de flesta RDBMS:er kan du fästa tabeller i minnet för att säkerställa detta. I Oracle skulle jag skapa dessa som indexorganiserade tabeller, som är små och presterar bra. Gör vad motsvarande är för din RDBMS.
Du vill också se till att party_contact rader är samlokaliserade i samma block (eller sida) med hjälp av ett klustrat index på party_id . Gör samma sak med address_line.contact_point_id . Detta minskar mängden IO.
Ett annat alternativ finns om du vill ha ett party att exklusivt äga en contact_point . Du kan sedan slå samman contact_point till party_contact för att skapa party_contact_point (fortfarande klustrade på party_id ). Detta förenklar modellen och kan hjälpa prestanda.
Att ändra kontakter betyder inte att du byter databaser
Vi lever i en tid då man kan säga att förändring är den enda konstanta.
Det betyder inte att varje gång något ändras måste det påverka din databas. Med lite eftertanke kan vi framtidssäkra våra konstruktioner – kanske mer än vi har gjort hittills. Att göra det hjälper oss att reagera snabbt på den oundvikliga förändringen.
Om du ger dig igång med ett grönt projekt skulle jag rekommendera att använda Party Model (som kontaktpunkten är en del av) för organisationer och människor. Varför inte öppna upp modellen och anpassa den efter dina behov? Ta gärna en kopia och gör den till din egen.
Men om din databas eller databaser redan är fastställda, kan schemat som jag har presenterat här fortfarande användas, i XML-form, för att definiera din nyttolast när data integreras mellan system.