Med introduktionen av Azure SQL Database och tillägget av mer funktionalitet i v12, börjar databasadministratörer se sina organisationer mer intresserade av att flytta databaser till den här plattformen.
Jag började nyligen dyka mer in i Azure SQL Database för att se vad som skiljer sig drastiskt från att stödja boxversionen i datacenter över hela världen och Azure SQL Database. I min tidigare artikel, "Tuning:A Good Place to Start", täckte jag min metod för att komma igång med att trimma SQL Server. Jag bestämde mig för att granska detta mot Azure SQL Database för att upptäcka de stora skillnaderna.
I min ursprungliga artikel började jag med vanliga inställningar på instansnivå som jag ser ignorerade eller lämnade som standard, samt underhållsobjekt. Dessa inkluderar minne, maxdop, kostnadströskel för parallellitet, möjliggörande av optimering för ad hoc-arbetsbelastningar och konfigurering av tempdb. Med Azure SQL Database är du inte ansvarig för instansen och kan inte ändra dessa inställningar. Azure SQL Database är en plattform som en tjänst (PaaS), vilket innebär att Microsoft hanterar instansen åt dig; du är helt enkelt en hyresgäst med din databas eller databaser.
Du är dock ansvarig för underhållet, så du måste uppdatera statistik och hantera indexfragmentering som du gör för boxprodukten. För dessa uppgifter har jag upptäckt att de flesta klienter hanterar dessa processer med en dedikerad Azure VM som kör SQL Server och använder SQL Server Agent med schemalagda jobb.
Efter stegen från min artikel, nästa områden jag börjar titta på är fil- och väntastatistik och högkostnadsfrågor. Om du undrar om den här aspekten av ditt jobb som produktionsdba med lokala databaser kommer att förändras när du arbetar med Azure SQL Database, är svaret inte riktigt . Fil och vänta-statistik finns fortfarande kvar, men vi måste komma till dem på ett lite annorlunda sätt. Om du är van vid att använda Paul Randals skript för filstatistik och väntestatistik (eller frågorna om filstatistik under en tidsperiod och väntestatistik under en period), måste du göra några ändringar för att dessa skript för att fungera med Azure SQL Database.
När jag först provade Pauls filstatistikskript misslyckades det på grund av att Azure SQL Database inte stöder sys.master_files :
Ogiltigt objektnamn 'sys.master_files'.
Jag kunde modifiera skriptet för att använda sys.databases i join för att få databasnamnet och ta bort delen av skriptet för att få de individuella filnamnen eftersom vi bara kommer att ha att göra med en enda data och loggfil. Du kan se ändringarna jag var tvungen att göra i följande bild:
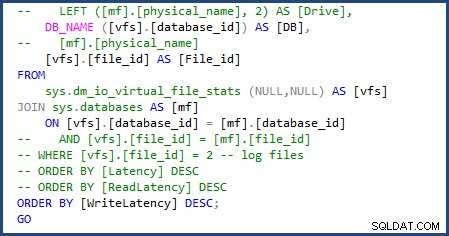
När jag körde skriptet file-stats-over-en-period-of-time efter, gjorde samma ändring till sys.databases och ta bort referenserna till file_id i anslutningen misslyckades den på grund av att Azure SQL Database v12 inte stöder globala ##temp-tabeller.
När jag ändrade alla globala ##temp-tabeller till lokala, hade jag ett annat problem med att skriptet inte kunde släppa befintliga temp-tabeller som användes, eftersom lokala #temp-tabeller inte kan refereras direkt med namn på det sätt som globala ##temp-tabeller kan, men detta var lätt att övervinna genom att ändra sådana kontroller till OBJECT_ID('tempdb..#SQLskillsStats1') . Jag gjorde samma ändring för den andra temporära tabellen och uppdaterade kodblocket i början och slutet av skriptet.
Jag var tvungen att göra ytterligare en ändring och ta bort [mf].[type_desc] och LEFT ([mf].[physical_name], 2) AS [Drive] eftersom de är beroende av sys.master_files . Skriptet var sedan komplett och redo att användas med Azure SQL Database.
Jag använder file-stats-over-en-period-of-time regelbundet när jag felsöker prestandaproblem. Den kumulativa informationen har sitt syfte, men jag är mer intresserad av specifika tidssegment när användarnas arbetsbelastningar körs.
Med filstatistik är vi bekymrade över vår latens per databasfil och hur vi kan ställa in för att minska den totala I/O. Tillvägagångssättet är detsamma som SQL Server, där du måste ställa in dina frågor ordentligt och ha rätt index. Om arbetsbelastningen bara är för stor måste du flytta till en DTU-databasnivå med snabbare prestanda. För mig är det här bra:du kastar bara hårdvara på det; men det är inte riktigt hårdvara i traditionell mening. Med Azure SQL Database får du börja med en billigare nivå och skala allt eftersom ditt företags och I/O-krav växer – huvudsakligen genom att bara vända på en switch.
Att försöka hitta den bästa metoden för att få väntestatistik var lättare. Standardskriptet som många av oss använder fungerar fortfarande, men det hämtar väntestatistik för behållaren där din databas körs. Dessa väntetider gäller fortfarande för ditt system, men kan inkludera väntetider som uppstår av andra databaser i samma behållare. Azure SQL Database innehåller en ny DMV, sys.dm_db_wait_stats , som filtrerar till den aktuella databasen. Om du är som jag och främst använder Pauls väntestatistikskript som utelämnar alla godartade väntetider, ändra bara sys.dm_os_wait_stats till sys.dm_db_wait_stats . Samma ändring fungerar även för skriptet väntar över en tidsperiod, men du måste också göra ändringen från globala variabler till lokala.
När det gäller att hitta högkostnadsfrågor hittar ett av mina favoritskript att köra de mest använda exekveringsplanerna. Enligt min erfarenhet är att ställa in en fråga som kallas 100 000 gånger per dag vanligtvis en större vinst än att ställa in en fråga som har den högsta IO men som bara körs en gång i veckan. Följande fråga är vad jag använder för att hitta de mest använda planerna:
VÄLJ usecounts , cacheobjtype , objtype , [text]FRÅN sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE usecounts> 1 AND objtype IN (N'Adhoc', N'DESCEDBY's OR DESCEDBY's count) före>När jag använder den här frågan i demos spolar jag alltid min plancache för att återställa värdena. När jag försökte köra
DBCC FREEPROCCACHEi Azure SQL Database fick jag följande fel:Det visar sig att
SQL Azure stöder för närvarande inte DBCC FREEPROCCACHE (Transact-SQL), så du kan inte manuellt ta bort en exekveringsplan från cachen. Men om du gör ändringar i tabellen eller vyn som hänvisas till av frågan (ALTER TABLE och ALTER VIEW) kommer planen att tas bort från cachen.DBCC FREEPROCCACHEstöds inte i Azure SQL Database. Detta var oroande för mig, tänk om jag är i produktion och har några dåliga planer och vill rensa procedurens cache som jag kan med boxversionen. Lite Google/Bing-forskning ledde till att jag hittade Microsoft-artikeln "Understanding the Procedure Cache on SQL Azure", som säger:När man diskuterar detta med Kimberly Tripp efter att inte ha sett det beskrivna beteendet, spolar den inte planen från cachen, men den ogiltigförklarar planen (och sedan kommer planen så småningom att åldras ur cachen). Även om detta är användbart i vissa situationer, var det inte vad jag behövde. För min demo ville jag återställa räknarna i sys.dm_exec_cached_plans. Att skapa en ny plan skulle inte ge mig det önskade resultatet. Jag kontaktade mitt team och Glenn Berry sa åt mig att prova följande manus:
ALTER DATABASE SCOPED CONFIGURATION RENSA PROCEDURE_CACHE;Detta kommando fungerade; Jag kunde rensa procedurcachen för den specifika databasen. Databas Scoped Configurations är en ny funktion som läggs till i SQL Server 2016 RC0; Glenn bloggade om det här:Använder ALTER DATABASE SCOPED CONFIGURATION i SQL Server 2016.
Jag är glad att flytta flera av mina egna databaser till Azure SQL Database och att fortsätta lära mig om de nya funktionerna och skalbarhetsalternativen. Jag ser också fram emot att arbeta med SentryOne DB Sentry, ett nyligen tillägg till SentryOne-plattformen. Jag är mest intresserad av att experimentera med DTU Usage dashboard, som Mike Wood beskrev i sitt senaste inlägg.