Kameror, svängdörrar, hissar, temperatursensorer, larm – alla dessa enheter producerar ett stort antal sammankopplade signaler som är relaterade till händelser som händer runt omkring oss. Föreställ dig nu att du är personen som behöver spåra status, producera realtidsrapporter och göra förutsägelser baserat på all denna signaldata. För att göra detta måste du först lagra denna data. En datamodell som stöder sådan signalbehandling är ämnet för dagens artikel.
Det enklaste sättet att lagra inkommande signaler skulle vara att helt enkelt lagra en textrepresentation av dem i en stor lista. Detta tillvägagångssätt skulle göra det möjligt för oss att utföra infogning snabbt, men uppdateringar skulle vara problematiska. Dessutom skulle en sådan modell inte normaliseras, och därför kommer vi inte att gå i den riktningen.
Vi kommer att skapa en normaliserad datamodell som kan användas för att lagra data som genereras av olika enheter och även definiera hur enheterna är relaterade. En sådan modell skulle effektivt lagra allt vi behöver och skulle också kunna användas för analys och prediktiv analys.
Datamodell
Datamodellen för signalbehandling
Modellen består av tre ämnesområden:
ComplexesInstallations & DevicesSignals & Events
Vi kommer att beskriva vart och ett av dessa ämnesområden i den ordning de är listade.
Komplex
När jag skapade denna datamodell utgick jag från antagandet att vi kommer att använda den för att spåra vad som händer i större komplex. Komplexen varierar i storlek från ett enkelrum till ett köpcentrum. Det är viktigt att varje komplex har minst en enhet/sensor, men den kommer förmodligen att ha många fler.
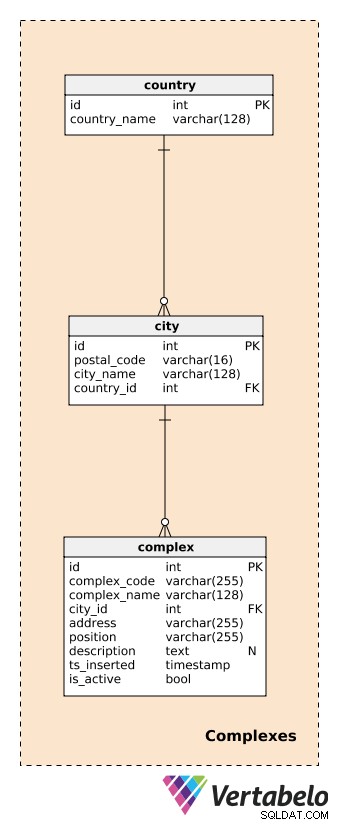
Innan vi beskriver komplex måste vi definiera tabellerna som hanterar länder och städer. Dessa kommer att ge en ganska detaljerad beskrivning av platsen för varje komplex.
För varje country , vi lagrar dess UNIKA country_name; för varje city , lagrar vi den UNIKA kombinationen av postal_code , city_name och country_id . Jag kommer inte att gå in på detaljer här, och vi antar att varje stad bara har ett postnummer. I verkligheten kommer de flesta städer att ha mer än ett postnummer; i så fall kan vi använda huvudkoden för varje stad.
Ett complex är den faktiska byggnaden eller platsen där datagenererande enheter är installerade. Som nämnts tidigare kan komplex variera från ett enkelrum eller en mätstation till mycket större platser som parkeringsplatser, köpcentra, biografer etc. De är föremål för vår analys. Vi vill kunna följa vad som händer på den komplexa nivån i realtid och senare ta fram rapporter och analyser. För varje komplex kommer vi att definiera en:
complex_code– En UNIK identifierare för varje komplex. Medan vi har ett separat primärnyckelattribut (id) för den här tabellen kan vi förvänta oss att vi kommer att ärva ytterligare en identifieringskod för varje komplex från ett annat system.complex_name– Ett namn som används för att beskriva det komplexet. När det gäller köpcentra och biografer kan detta vara deras faktiska och välkända namn; för en mätstation kan vi använda ett generiskt namn.city_id– En referens till staden där komplexet ligger.address– Den fysiska adressen till komplexet.position– Komplexets position (dvs geografiska koordinater) definierad i textformat.description– En textbeskrivning som närmare beskriver detta komplex.ts_inserted– En tidsstämpel när denna post infogades.is_active– Ett booleskt värde som anger om detta komplex fortfarande är aktivt eller inte.
Installationer och enheter
Nu går vi närmare hjärtat av vår modell. Vi kommer sannolikt att ha ett antal enheter installerade i varje komplex. Vi kommer också nästan säkert att gruppera dessa enheter baserat på deras syfte – t.ex. vi kan sätta kameror, dörrsensorer och en motor som används för att öppna och stänga en dörr i en grupp eftersom de fungerar tillsammans.
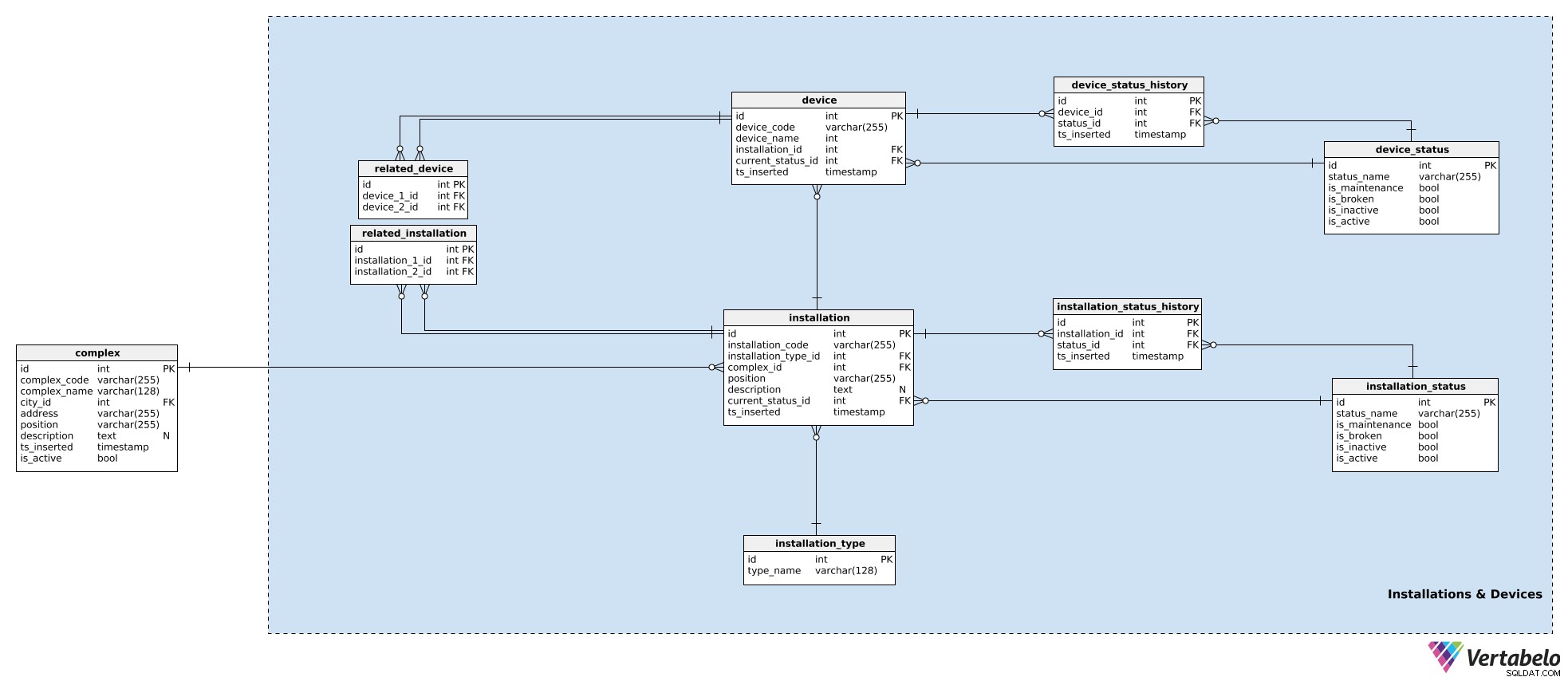
I vår modell är enheter som arbetar tillsammans i ett komplex grupperade i installationer. Dessa kan vara för ytterdörrar, rulltrappor, temperatursensorer etc. För varje installation lagrar vi följande detaljer i installation tabell:
installation_code– En UNIK kod som används för att beteckna den installationen.installation type_id– En referens tillinstallation_typelexikon. Denna ordbok lagrar endast ett UNIKTtype_nameattribut som beskriver typen, t.ex. rulltrappa, hiss.complex_id– En referens tillcomplexsom installationen tillhör.position– Koordinaterna, i textformat, för installationen i komplexet.description– En textbeskrivning av installationen.current_status_id– En referens till den aktuella statusen (fråninstallation_statustabell) för den installationen.ts_inserted– En tidsstämpel när denna post infogades i vårt system.
Vi har redan nämnt installationsstatusar. En lista över alla möjliga statusar lagras i installation_status lexikon. Varje status definieras UNIKT av dess status_name . Förutom det kommer vi att lagra flaggor som anger om den statusen, när den används, antyder att installationen is_broken , is_inactive , is_maintenance , eller is_active . Endast en av dessa flaggor bör ställas in åt gången.
Vi har redan tilldelat en aktuell status till installationen. Om vi ska spåra vad som händer med enheten måste vi också lagra dess historik. För att göra det använder vi ytterligare en tabell, installation_status_history . För varje post här lagrar vi referenser till den relaterade installationen och statusen samt ögonblicket (ts_inserted ) när den statusen tilldelades.
Installationer är en del av våra komplex. Även om varje installation är en enda enhet, kan den fortfarande vara relaterad till andra installationer. (T.ex. ett videosystem vid ett köpcentrums främre ingång är uppenbarligen relaterat till gallerians ytterdörrar – folk kommer att ses av kameran först och sedan öppnas dörrarna.) Om vi vill hålla reda på dessa relationer kommer vi att lagra dem i related_installation tabell. Observera att den här tabellen endast innehåller UNIKA par av två nycklar, båda hänvisar till installation tabell.
Samma logik används för att lagra enheter. Enheter är enstaka delar av hårdvara som producerar de signaler vi är intresserade av. Medan installationer tillhör komplex, tillhör enheterna installationer. För varje device , vi lagrar:
device_code– ETT UNIKT sätt att beteckna varje enhet.device_name– Ett namn för den här enheten.installation_id– En referens till den installation som denna enhet tillhör.current_status_id– Enhetens aktuella status.ts_inserted– En tidsstämpel när denna post infogades.
Statuser hanteras på samma sätt. Vi använder device_status tabell för att lagra en lista över alla möjliga enhetsstatusar. Den här tabellen har samma struktur som installation_status och attributen används på samma sätt. Anledningen till att ha de två separata statusordböckerna är att enheter och deras installationer kan ha olika status – åtminstone till namnet.
Den aktuella statusen lagras i device.current_status_id attributet och statushistoriken lagras i device_status_history tabell. För varje post här lagrar vi relationer till enheten och status samt ögonblicket när denna post infogades.
Den sista tabellen i detta ämnesområde är related_device tabell. Även om det är ganska uppenbart att alla enheter i samma installation är nära besläktade, vill jag ha möjligheten att relatera två enheter som tillhör vilken installation som helst. Vi gör det genom att lagra deras två enhets-ID:n i den här tabellen.
Signaler och händelser
Nu är vi redo för hela modellens hjärta.
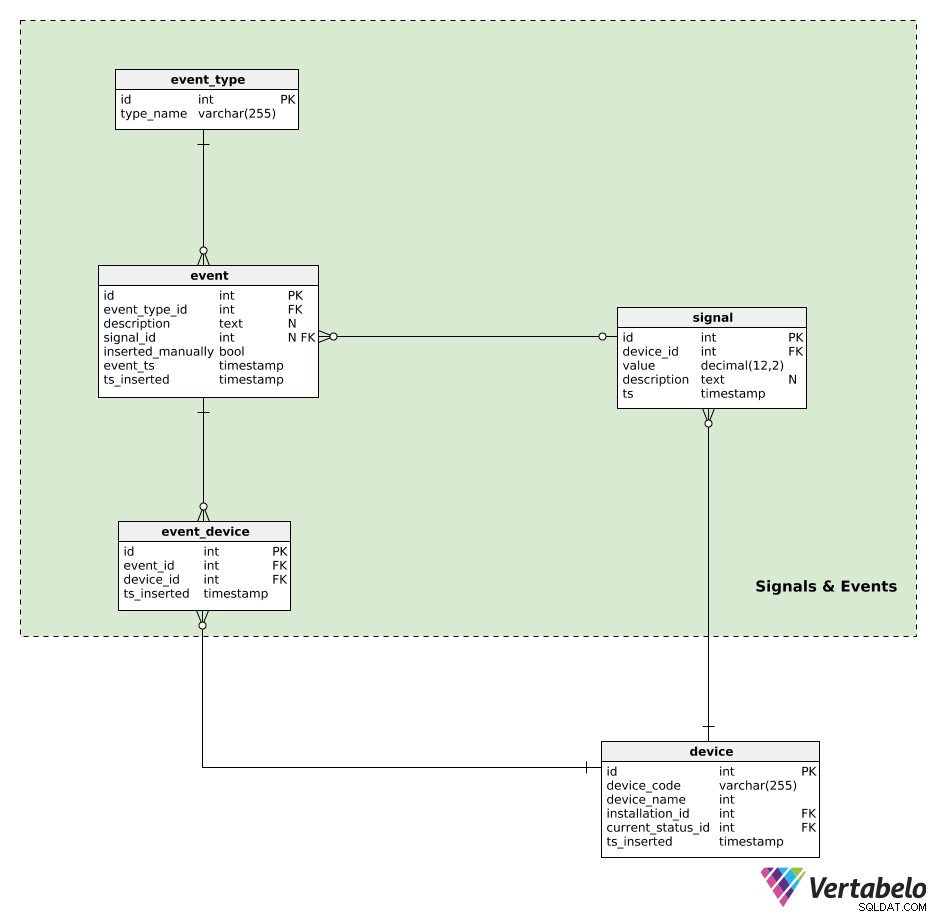
Enheter genererar signaler. All signaldata hålls i signal tabell. För varje signal lagrar vi:
device_id– En referens till enheten som genererade den signalen.value– Det numeriska värdet för den signalen.description– Ett textvärde som kan innehålla ytterligare parametrar (t.ex. signaltyp, värden, använd mätenhet) relaterade till den enskilda signalen. Denna data lagras i ett JSON-liknande format.ts– En tidsstämpel när denna signal infogades i tabellen.
Vi kan förvänta oss att detta bord kommer att få extremt mycket användning, med ett stort antal insättningar som utförs per sekund. Därför bör databasunderhållet fokusera på att spåra storleken på denna tabell.
Det sista jag vill göra är att lägga till händelser i vår datamodell. Händelser kan genereras automatiskt av en signal eller infogas manuellt. En automatiskt genererad händelse kan vara "dörren öppen i 5 minuter", medan en manuellt införd händelse kan vara "enheten var tvungen att stängas av på grund av denna signal". Hela idén är att lagra åtgärder som inträffade som ett resultat av enhetens beteende. Senare kunde vi använda dessa händelser när vi utförde en enhetsbeteendeanalys.
Händelser kommer att granuleras av event_type . Varje typ definieras UNIKT av dess type_name .
Alla automatiskt genererade eller manuellt infogade händelser registreras i event tabell. För varje post här lagrar vi:
event_type_id– En referens till den relaterade händelsetypen.description– En textbeskrivning av den händelsen.signal_id– En referens till signalen, om någon, som orsakade händelsen.inserted_manually– En flagga som anger om denna post har infogats manuellt eller inte.event_tsochts_inserted–Tidsstämplar när den här händelsen faktiskt hände och när en registrering av den infogades. Dessa två kan skilja sig åt, särskilt när händelseposter infogas manuellt.
Den sista tabellen i vår modell är event_device tabell. Den här tabellen används för att relatera händelser med alla enheter som var inblandade. För varje post lagrar vi det UNIKA paret event_id – device_id och tidsstämpeln när posten infogades.
Vad tycker du om vår datamodell för signalbehandling?
Idag har vi analyserat en förenklad datamodell som vi kan använda för att spåra signaler från en uppsättning enheter installerade på olika platser. Modellen i sig borde räcka för att lagra allt vi behöver för att spåra status och utföra analyser. Ändå är många förbättringar möjliga. Vad kan vi lägga till? Berätta för oss i kommentarerna nedan.