I en katastrofåterställningsplan är ditt återställningspunktsmål (RPO) en viktig återställningsparameter som dikterar hur mycket data du har råd att förlora. RPO listas i tid, från sekunder till dagar. RPO är i praktiken direkt beroende av ditt backupsystem. Det markerar åldern på dina säkerhetskopierade data som du måste återställa för att kunna återuppta normal drift.
Om du gör en nattlig backup klockan 22.00. och ditt databassystem kraschar bortom reparation kl. 15.00. följande dag förlorar du allt som har ändrats sedan din senaste säkerhetskopiering. Din RPO i detta specifika sammanhang är föregående dags backup, vilket innebär att du har råd att förlora en dags förändringar.
Diagrammet nedan från vår vitbok om katastrofåterställning illustrerar konceptet.
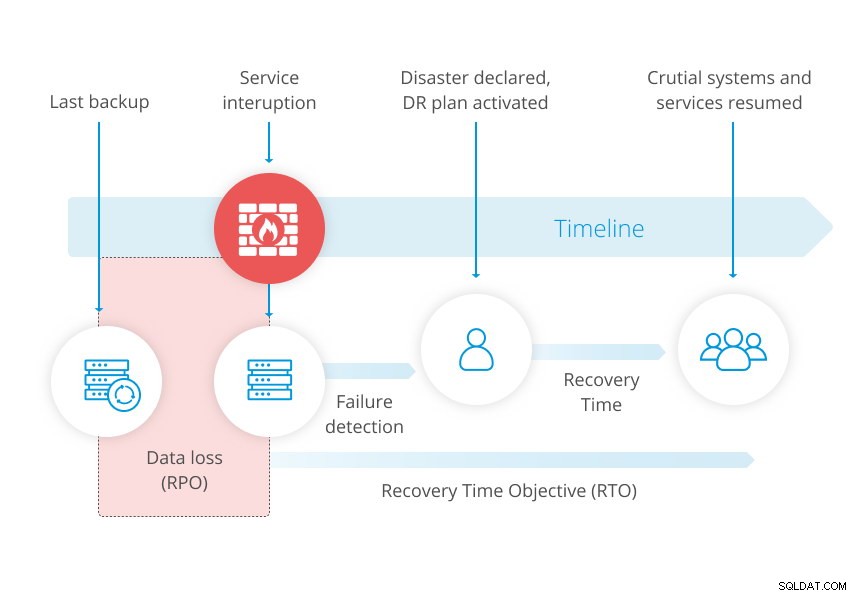
För snävare RPO kanske det inte räcker med en säkerhetskopia. När du säkerhetskopierar din databas tar du faktiskt en ögonblicksbild av data vid ett givet ögonblick. Så när du återställer en säkerhetskopia kommer du att missa ändringarna som hände mellan den senaste säkerhetskopieringen och felet.
Det är här konceptet Point In Time Recovery (PITR) kommer in.
Vad är PITR?
Point In Time Recovery (PITR), som namnet säger, innebär att databasen återställs när som helst i det förflutna. För att kunna göra detta måste vi återställa en säkerhetskopia och sedan tillämpa alla ändringar som hände efter säkerhetskopieringen tills precis före felet.
För PostgreSQL lagras ändringarna i WAL-loggarna (för mer information om WAL och den data de lagrar kan du kolla in den här bloggen).
Så det finns två saker vi måste säkerställa för att kunna utföra en PITR:Säkerhetskopiorna och WAL:erna (vi måste ställa in kontinuerlig arkivering för dem).
För att utföra PITR måste vi återställa säkerhetskopian och sedan tillämpa WALs.
När kan det vara användbart?
Du kan använda den här strategin när du återställer från ett problem som orsakade att data skadades. Du måste komma ihåg att du försöker minimera dataförlusten, men det finns några problem som kan göra att data inte längre är användbara efter det.
Några exempel på detta kan vara oplanerade dataändringar (DML eller DDL), mediafel eller databasunderhåll (som uppgraderingar) som leder till datakorruption. Du kommer inte att kunna återställa dataändringarna som skedde efter problemet.
Låt oss anta att en användare felaktigt har utfört en DML, vilket gör att data från en hel tabell felaktigt har ändrats eller raderats. Du kan utföra en PITR av databasen på en separat plats och sedan exportera innehållet i tabellen. Du kan sedan återställa den tabellen till den befintliga databasen och rulla tillbaka till en kopia av hur tabellen var innan problemet inträffade.
Naturligtvis är det inte alltid möjligt att återställa endast en del av databasen på detta sätt, så i så fall måste du återställa hela databasen till en given punkt, och kommer att ha en minimal men oundviklig dataförlust (du kommer att missa eventuella ändringar som hände efter att problemet inträffade).
Hur använder man det med ClusterControl?
I en tidigare blogg kunde vi se hur man implementerar PITR manuellt, nu ska vi se hur man använder ClusterControl för att utföra denna uppgift.
Aktivera Point In Time Recovery
För att aktivera PITR-funktionen måste vi ha WAL-arkivering aktiverad. För detta kan vi gå till ClusterControl -> Välj PostgreSQL-kluster -> Nodåtgärder -> Aktivera WAL-arkivering, eller bara gå till ClusterControl -> Välj PostgreSQL-kluster -> Säkerhetskopiering -> Inställningar och aktivera alternativet "Enable Point-In-Time Recovery" (WAL Archiving)” som vi kommer att se i följande bild.
Vi måste komma ihåg att för att aktivera WAL-arkivering måste vi starta om vår databas. ClusterControl kan göra detta åt oss också.
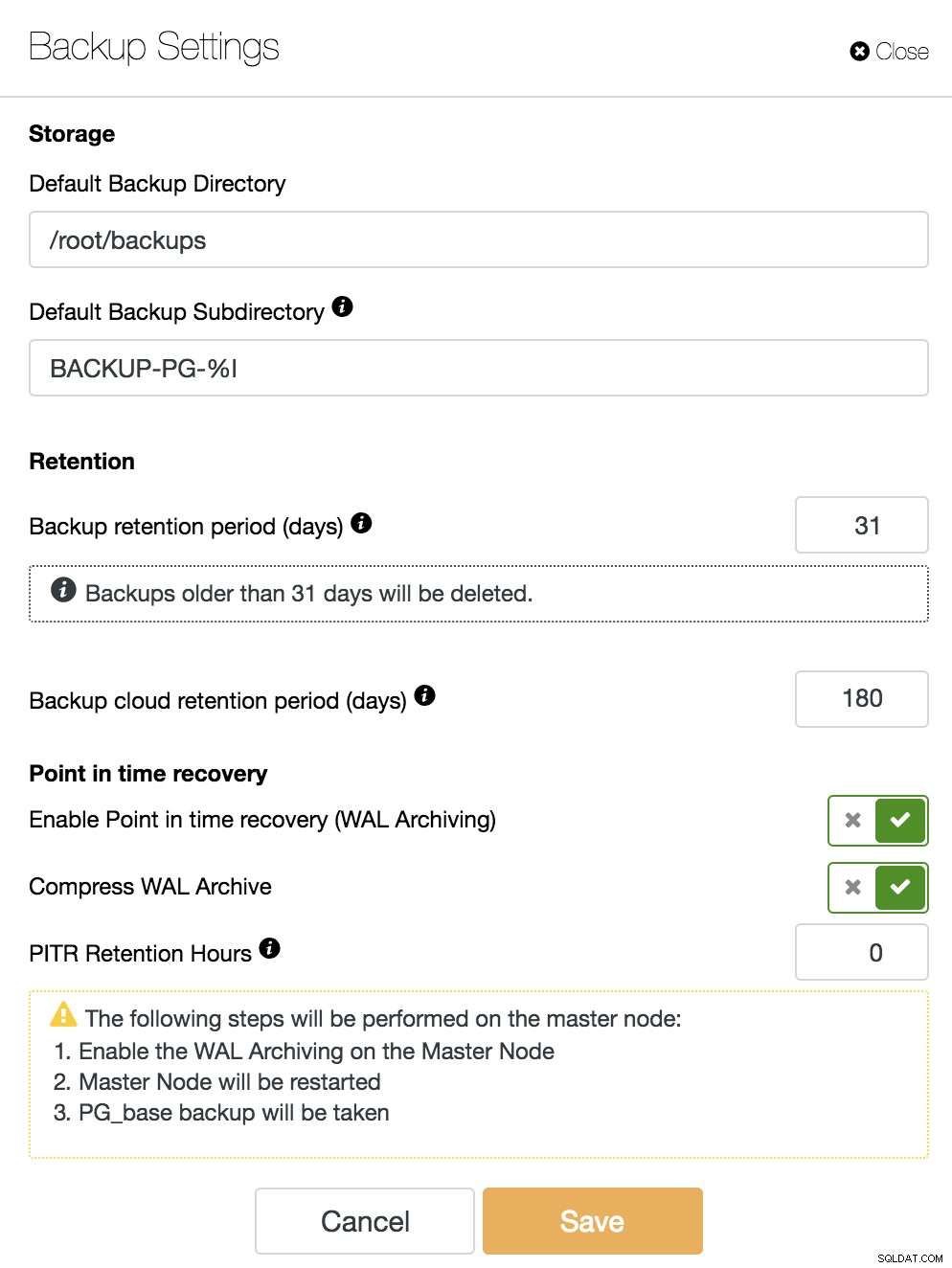
Utöver de alternativ som är gemensamma för alla säkerhetskopior som "Backup Directory" och "Backup Retention Period", här kan vi också ange WAL Retention Period. Som standard är 0, vilket betyder för alltid.
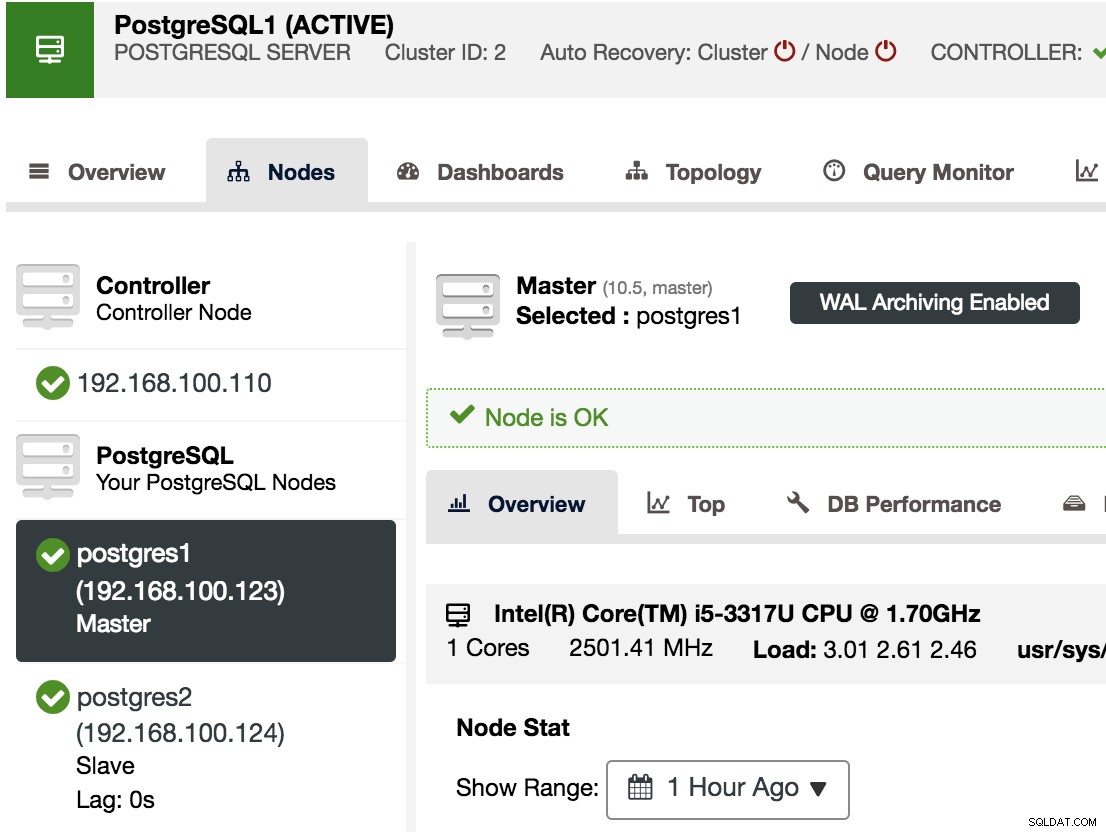
För att bekräfta att vi har aktiverat WAL Archiving kan vi välja vår huvudnod i ClusterControl -> Välj PostgreSQL Cluster -> Noder, och vi bör se meddelandet WAL Archiving Enabled, som vi kan se i följande bild.
Skapa en säkerhetskopia som är kompatibel med Point In Time Recovery
Med WAL-arkivering aktiverat, som vi såg i föregående steg, kan vi skapa vår säkerhetskopia som är kompatibel med PITR. För detta, gå till ClusterControl -> Välj PostgreSQL Cluster -> Backup -> Create Backup.
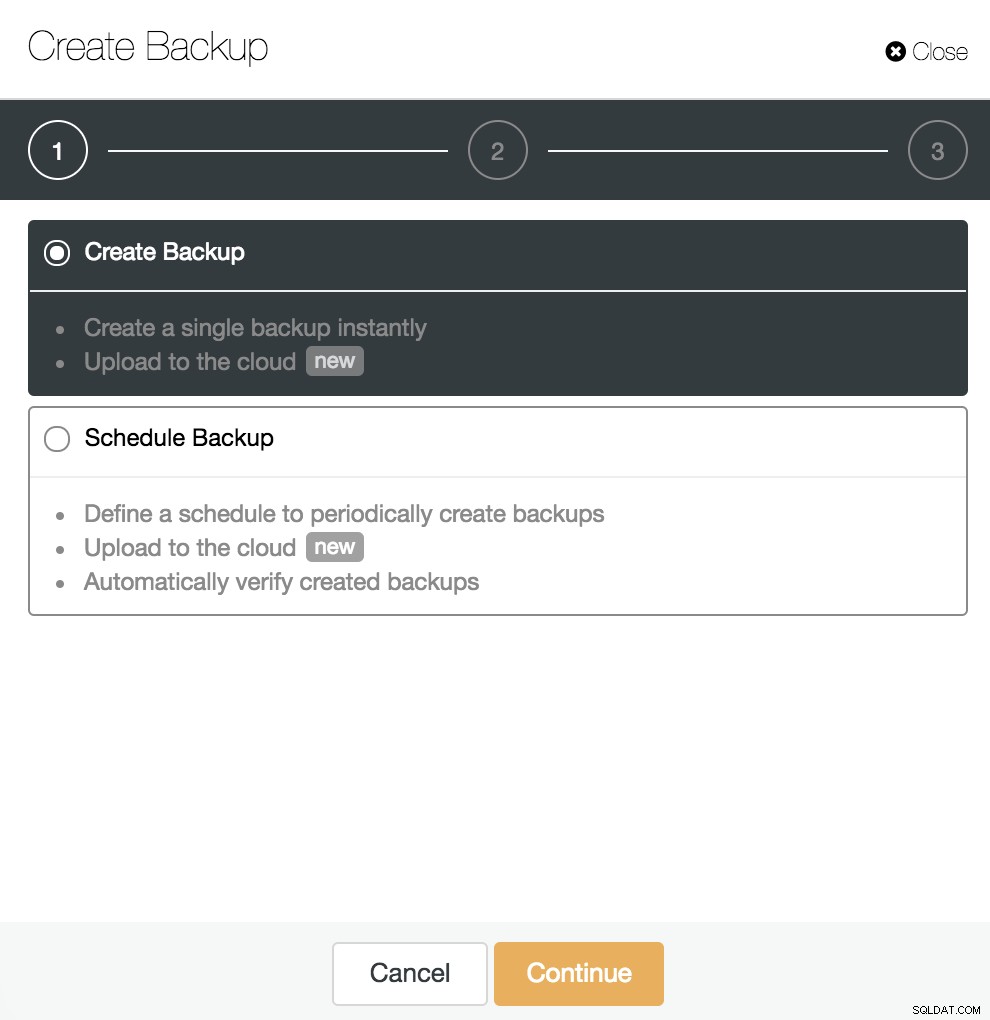
Vi kan skapa en ny säkerhetskopia eller konfigurera en schemalagd. För vårt exempel kommer vi att skapa en enda säkerhetskopia direkt.
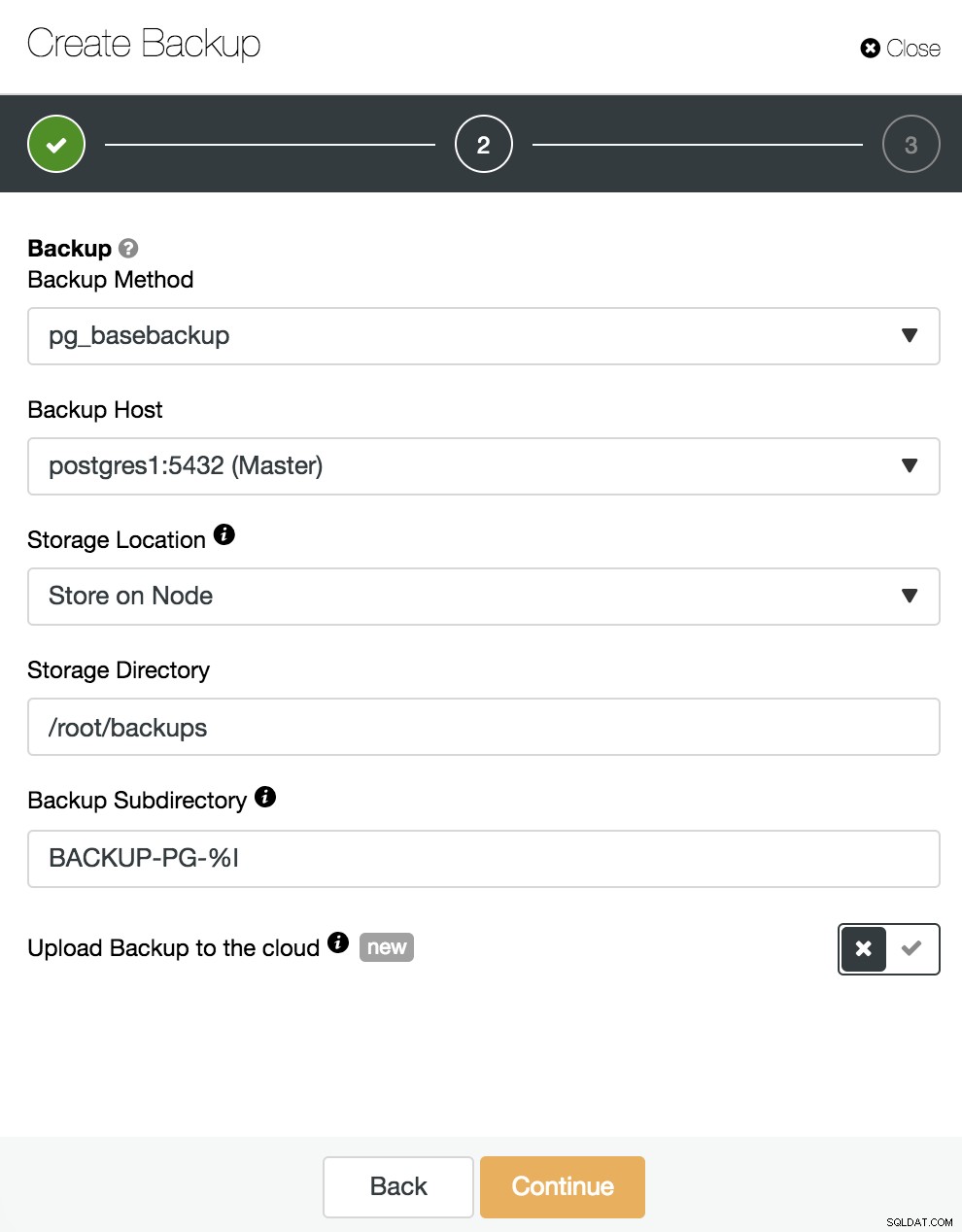
Här måste vi välja metoden "pg_basebackup", kompatibel med PITR, servern från vilken säkerhetskopieringen ska tas (för att vara kompatibel med PITR måste den vara mastern), och var vi vill lagra säkerhetskopian. Vi kan också ladda upp vår säkerhetskopia till molnet (AWS, Google eller Azure) genom att aktivera motsvarande knapp.
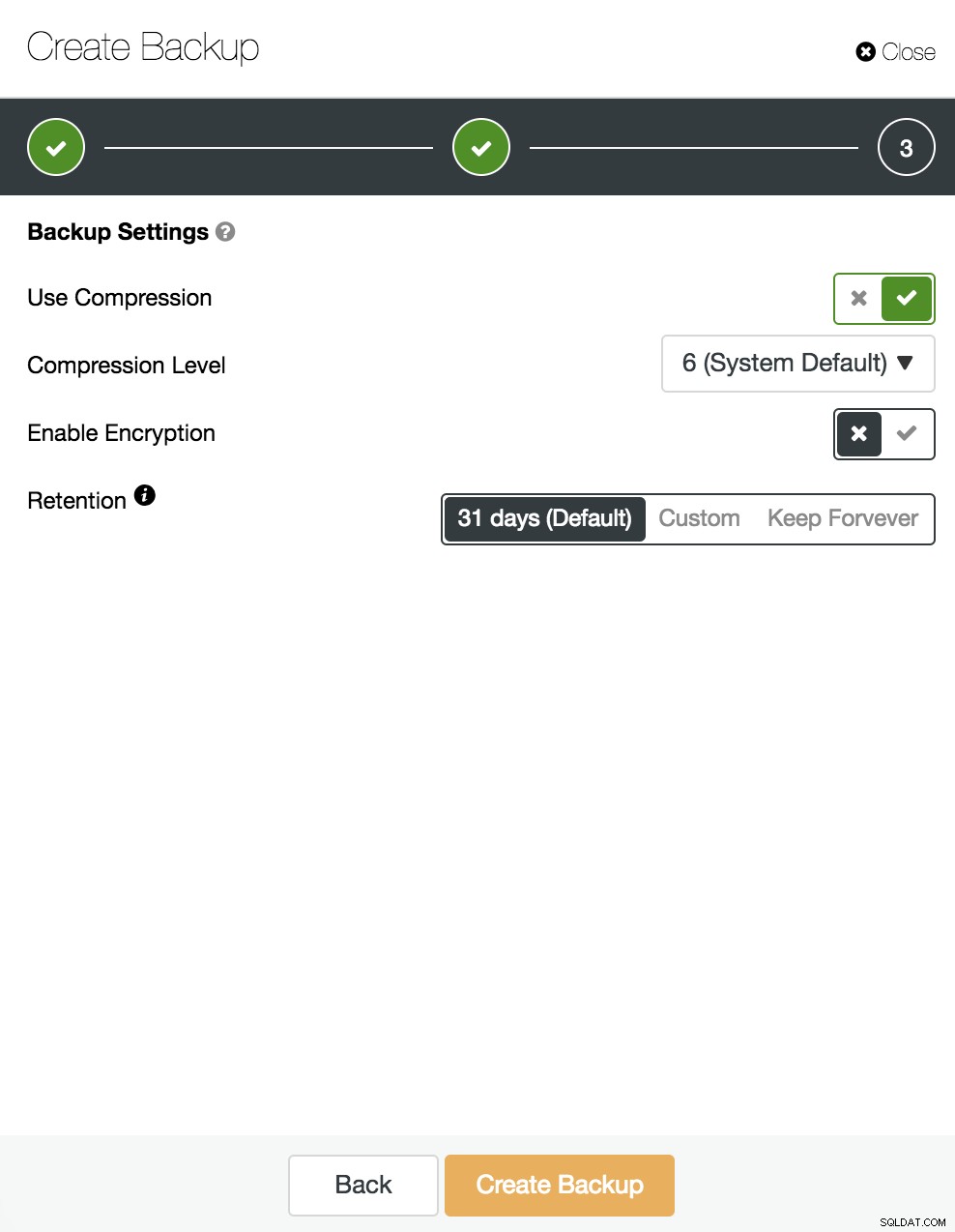
Sedan specificerar vi användningen av komprimering, kryptering och bevarandet av vår säkerhetskopia.
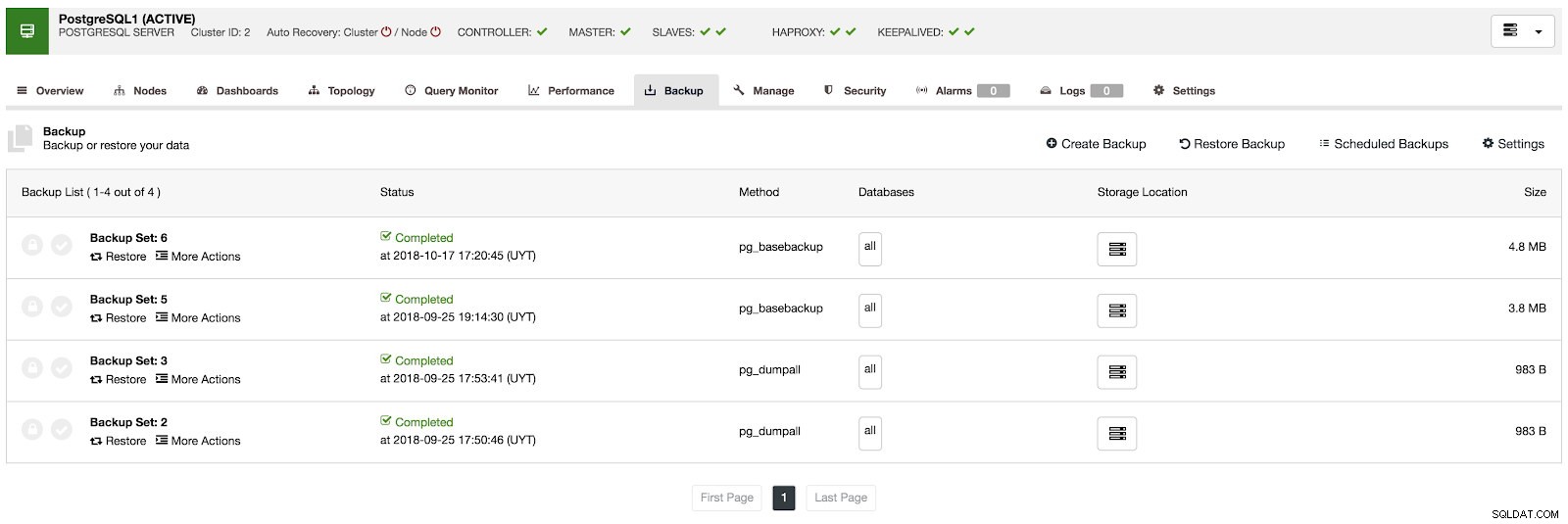
I avsnittet för säkerhetskopiering kan vi se hur säkerhetskopieringen fortskrider och information som metod, storlek, plats och mer.
Time-återställning från en säkerhetskopia
När säkerhetskopieringen är klar kan vi återställa den med funktionen ClusterControl PITR. För detta, i vår säkerhetskopieringssektion (ClusterControl -> Välj PostgreSQL Cluster -> Säkerhetskopiering), kan vi välja "Återställ säkerhetskopia", eller direkt "Återställ" på säkerhetskopian som vi vill återställa.
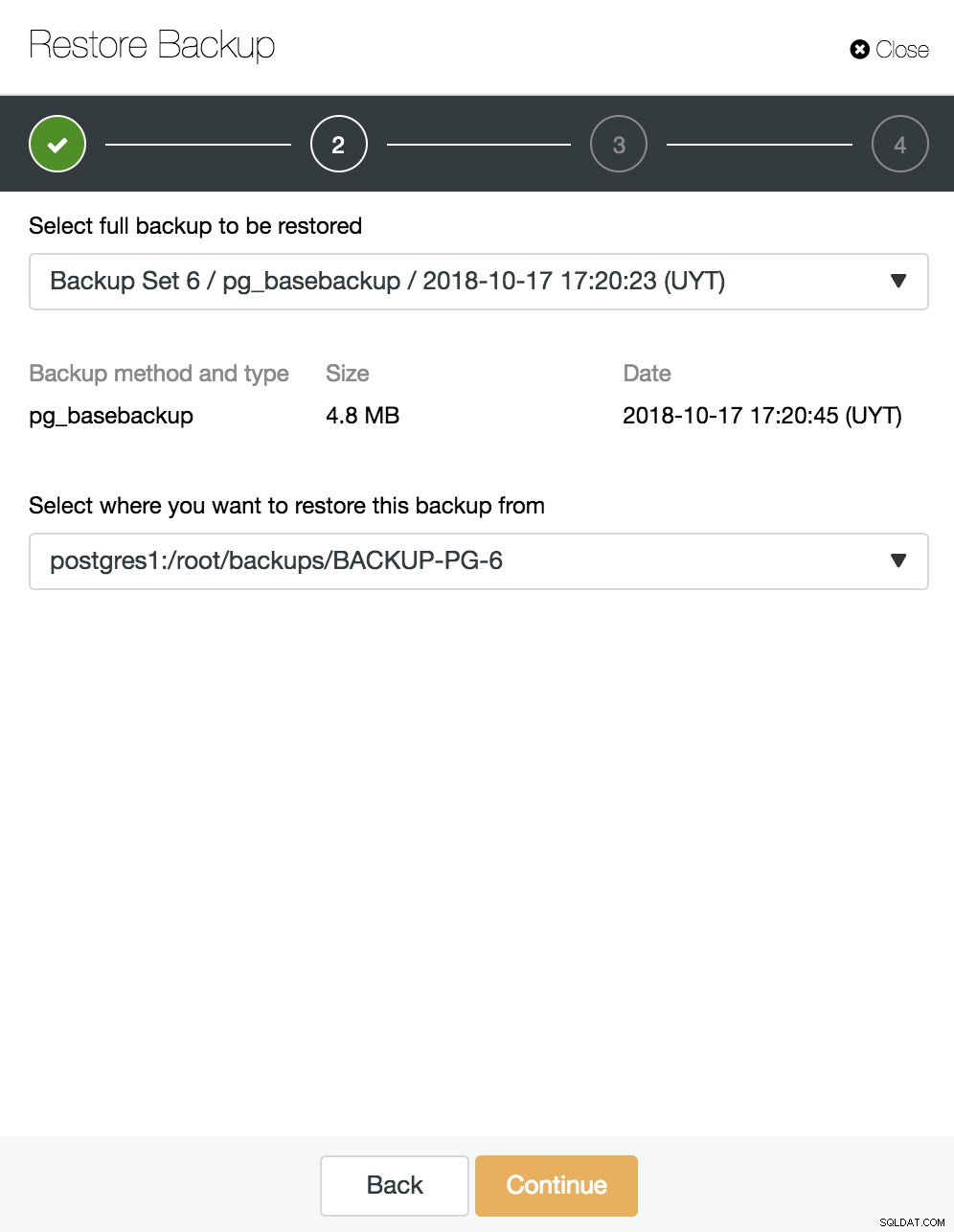
Här väljer vi vilken backup vi vill återställa och från vilken katalog.
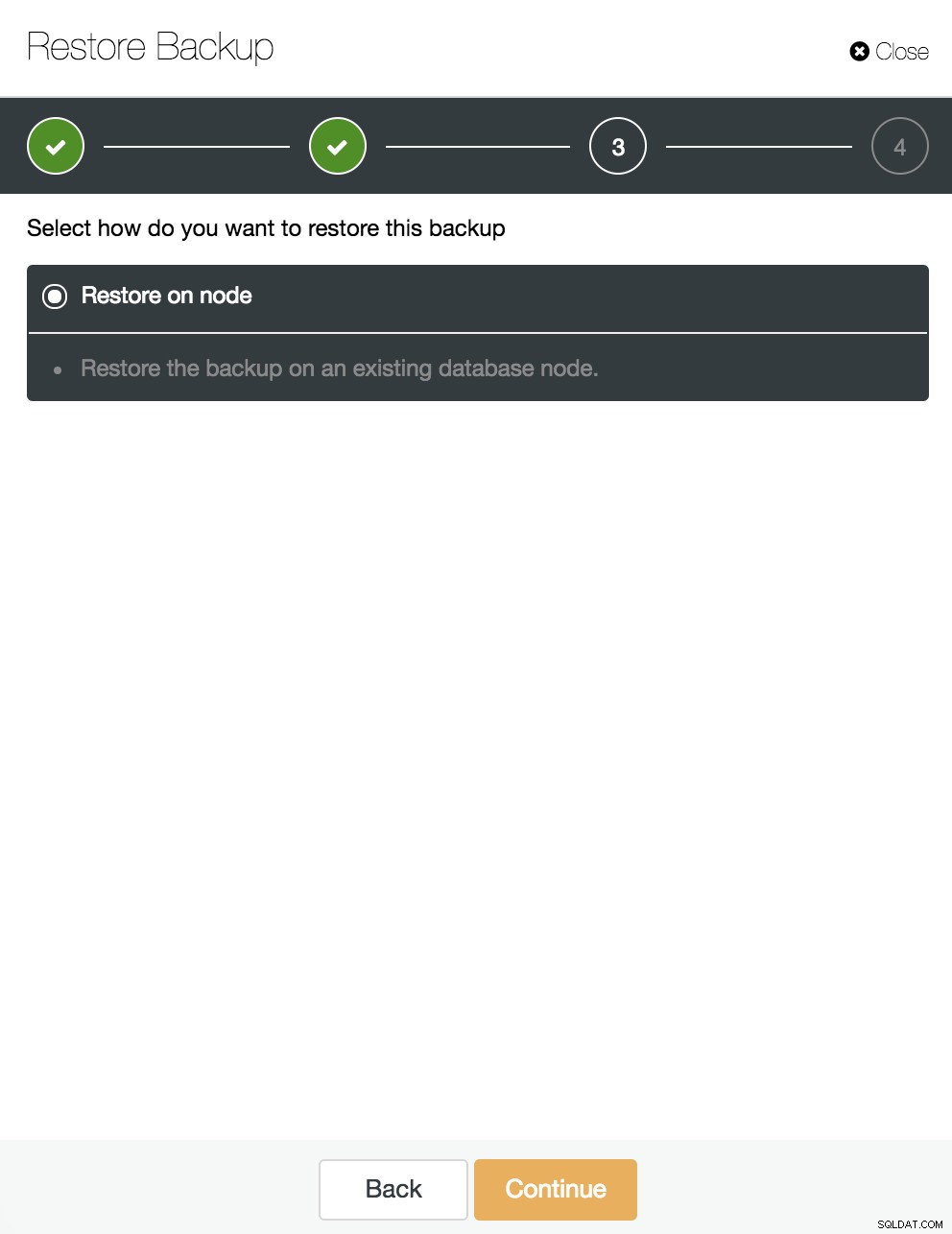
Vi lämnar alternativet "Återställ på nod" markerat och fortsätter.
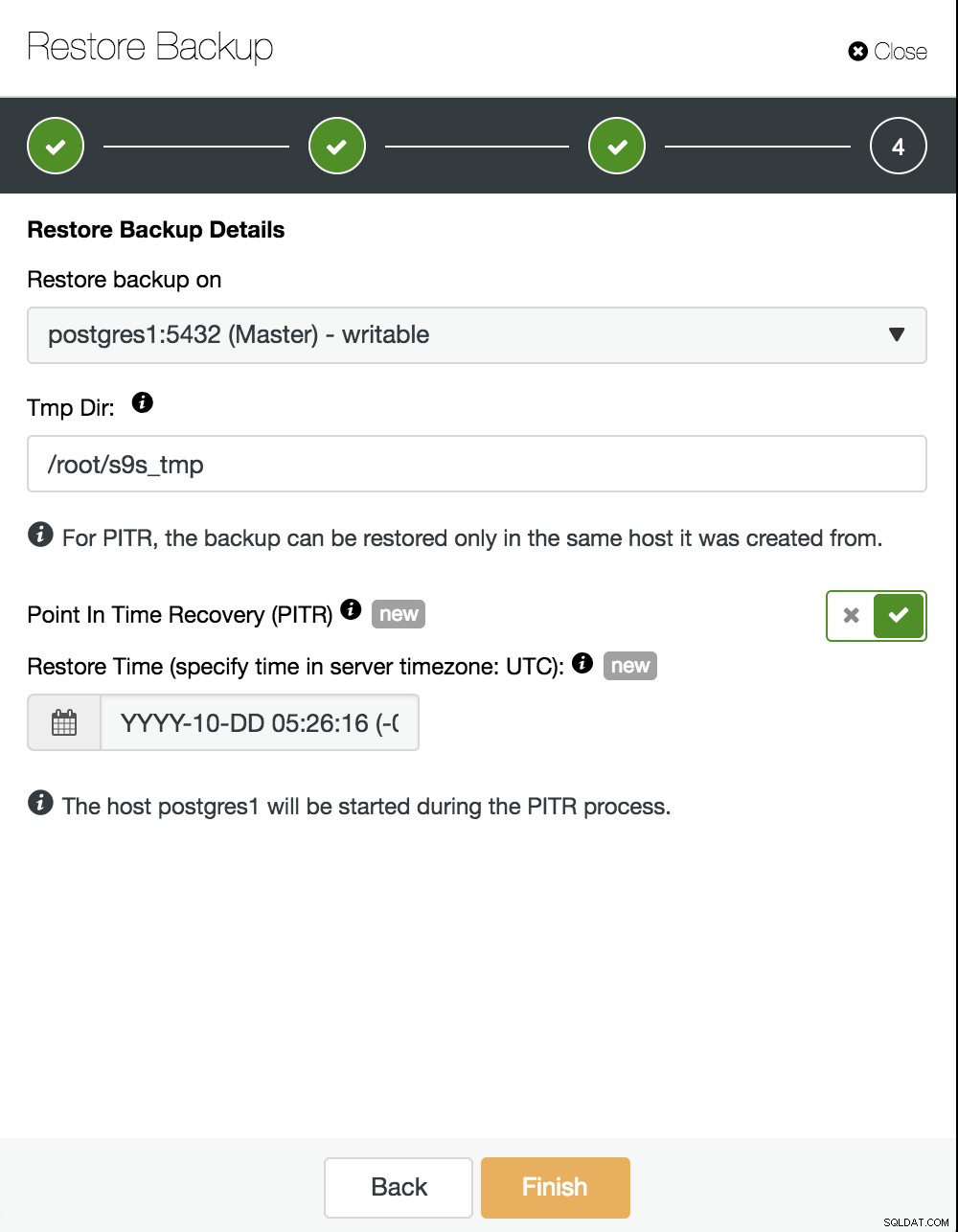
Nu måste vi välja var vi ska återställa vår säkerhetskopia och aktivera PITR-alternativet. Genom att ange tiden kommer det att vara tiden tills vi återhämtar oss. Tänk på att UTC-tidszonen används och att vår PostgreSQL-tjänst i mastern kommer att startas om.
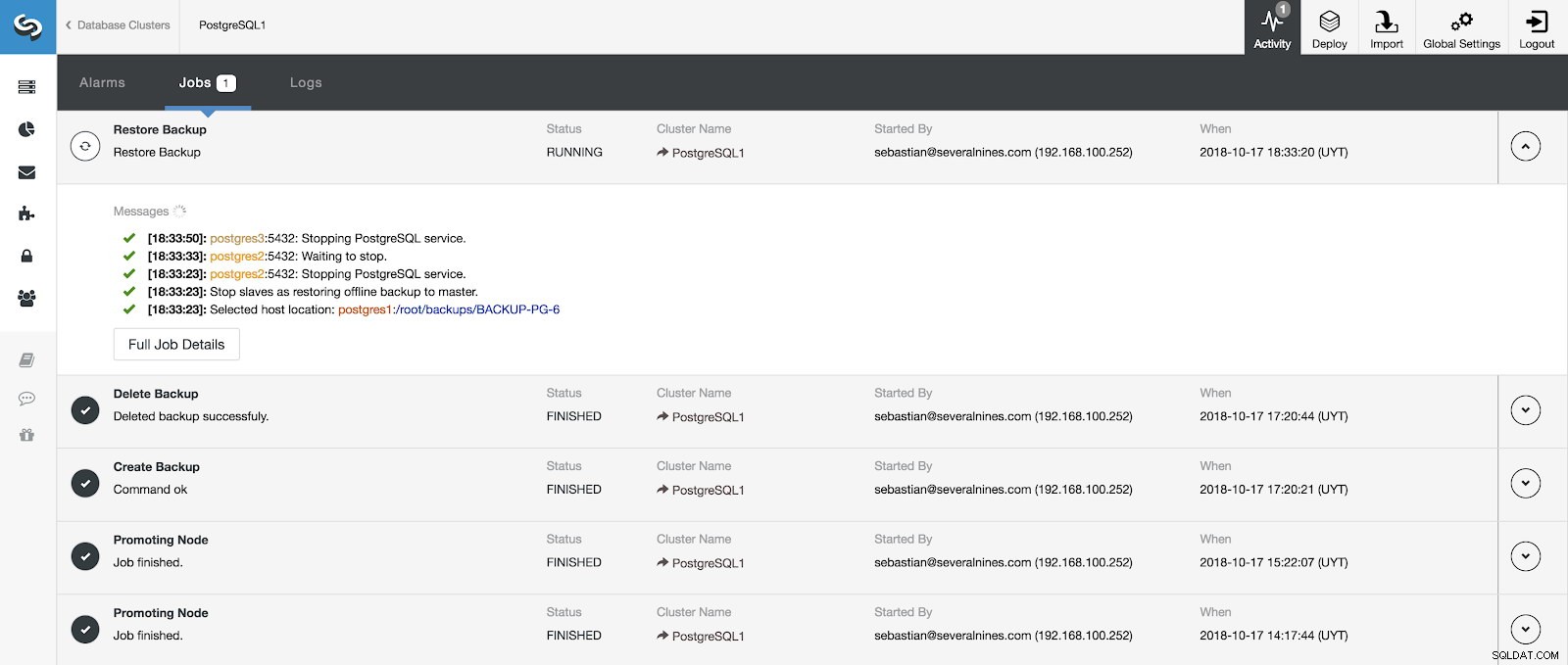
Vi kan övervaka utvecklingen av vår återställning från aktivitetssektionen i vår ClusterControl.
Slutsats
PITR är en nödvändig funktion för att möta en snäv RPO. Vi måste ställa in det korrekt för att säkerställa en korrekt katastrofåterställningsplan. ClusterControl tillhandahåller ett lättanvänt gränssnitt som hjälper dig att implementera PITR för dina PostgreSQL-databaser.