Du behöver datamodellering för att spara dig själv eller din organisation massor av pengar, timmar och problem. Läs vidare för att ta reda på hur datamodeller gör sin magi.
Datamodellering är processen att skapa en konceptuell bild av informationen som en databas innehåller eller bör innehålla. Som ett resultat av denna process skapas en datamodell som ger form åt dataobjekt (alla de enheter för vilka information ska lagras), associationerna eller relationerna mellan dem och regler eller begränsningar som styr informationen som kommer in i databasen .
Mycket trevligt, men är det verkligen nödvändigt att arbeta med datamodeller? Kan vi inte bara hoppa över det här steget, spara lite tid och gå direkt till att skapa objekt i databasen? En kurs i databasmodellering kommer att besvara dessa frågor, men om du vill ha en sammanfattning så ger jag dig tillräckligt med skäl att ha en datamodell till hands när du behöver arbeta med information lagrad i en databas. När du har läst klart den här artikeln kommer du att hålla med mig om att att arbeta med en databas utan en ordentlig modell är likvärdigt med att bygga ett hus – eller till och med en skyskrapa – utan en ordentlig grund.
Låt oss börja med att överväga två sammanhang där datamodellering huvudsakligen görs:
- Strategisk modellering, som utförs som en del av den allmänna informationssystemstrategin i en organisation.
- Databasdesign, som är en del av designfasen i mjukvaruutvecklingsprocessen.
I båda situationerna finns det gott om skäl att göra datamodellering. Först kommer vi att se de som har att göra med informationssystemstrategi, sedan de som är relaterade till mjukvaruutveckling.
Högre informationskvalitet
En datamodell är väsentlig för att ge klarhet och konsekvens i metadata , definitionerna av objekten som utgör en databas. Detta bidrar till att öka informationskvaliteten. En datamodell kan till exempel säkerställa att rätt format används för dataelement som telefonnummer och postnummer, och i en databas där kunddata lagras kan den säkerställa att varje kund har minst en adress.
Du kan också säkerställa kvaliteten på informationen som lagras i en databas genom att införa regler så att endast giltig data kommer in i tabellerna. För att göra detta när du designar datamodellen ställer du in värdedomänen för varje fält och skiljer de fält som måste ha värden från de som kan lämnas tomma.
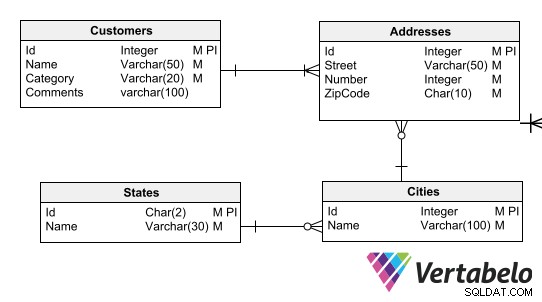
Datamodelldefinitioner säkerställer dataöverensstämmelse med affärsregler. Du kanske till exempel vill tvinga varje klient att ha en adress med rätt postnummerformat, eller att varje adress ska associeras med en stad och varje stad med en stat.
Informationskvaliteten förbättras också genom att införa restriktioner som säkerställer referensintegritet och upprätthåller den avsedda kardinaliteten i relationerna mellan enheter. Dessa begränsningar kan endast härledas från en riktig datamodell.
Återanvändning av datatillgångar
När man utvecklar ett nytt system eller lägger till ny funktionalitet i ett befintligt system är det vanligt att en del av de dataenheter som krävs av den nya utvecklingen redan finns i en databas och därför kan återanvändas. Det enda sättet att ta reda på vilka enheter som redan finns är att bläddra i uppdaterade datamodeller som på ett adekvat sätt beskriver strukturerna för de databaser som används av organisationen.
Konceptuella, logiska och fysiska datamodeller bör underhållas för att ge vyer med olika abstraktionsnivåer så att du enkelt kan upptäcka återanvändbara datatillgångar. Du kan använda ett specialiserat designverktyg, såsom Vertabelo-plattformen, för att underlätta skapandet av olika typer av datamodeller och till och med härleda en från en annan.
Denna goda praxis undviker att generera redundant data i olika scheman, vilket leder till inkonsekvent information förr eller senare (mer om detta nedan).
Migrering till molnmiljöer
Med DaaS (Data as a Service) infrastrukturer eller databaser i molnet, vissa krav, såsom databassekretess , dynamisk skalbarhet , och effektivitet i att hantera flera hyresgäster , bli mer kritisk.
Datamodeller är ett ovärderligt verktyg för att uppfylla dessa krav, eftersom de underlättar verifiering av att en schemadesign överensstämmer med dem. I sin tur låter de dig definiera partitionerna för scheman och deras lagringskrav, vilket är viktigt för att korrekt dimensionera den servicenivå som krävs och den förväntade lagringstillväxten när databaser finns i privata eller offentliga moln.
Databasdesignartefakter som ER-diagram är de bästa verktygen när man förbereder sig för en migrering till en molnmiljö. En guide om hur du använder ER-diagram kan ge dig en glimt av deras användbarhet vid databasmigrering.
Databasmodellering för Big Data och NoSQL
Icke-relationella databaser, som NoSQL och dimensionsscheman, kan tvinga oss att lägga åt sidan (åtminstone för ett ögonblick) vårt traditionella relationella tankesätt. Men det betyder inte att vi klarar oss utan datamodeller. Tvärtom, datamodellering blir ännu viktigare.
När du behöver arbeta med Big Data står du vanligtvis inför enorma silos av information som måste brytas ned, förfinas och struktureras på ett sådant sätt att du eller en dataanalytiker kan få strategiska insikter från den. En noggrann schemadesign krävs, både för förfinade informationsförråd eller datalager och för iscensättningsförråd som används för datarensning och datastruktureringsprocesser.
Det finns en missuppfattning, främst av programmerare, att NoSQL-databaser inte använder scheman och därför inte kräver datamodeller. Ingenting kan vara längre från sanningen. Eftersom NoSQL-teknologier inte tillhandahåller ett standardiserat sätt att se metadata (något varje RDBMS gör), blir datamodeller viktiga för att låta människor använda och dela informationen som lagras i databasen.
Fusioner och förvärv
Varje sammanslagning mellan två organisationer innebär en gigantisk utmaning för deras respektive IT-avdelningar. En betydande del av denna utmaning ligger i databaskonsolidering. Om båda organisationerna har uppdaterade datamodeller kan denna konsolidering göras i modellerna istället för direkt i databaserna, vilket avsevärt minskar ansträngningen som ägnas åt uppgiften.
Hittills har vi sett fördelarna med datamodellering i samband med IT-strategisk planering av en organisation. Om dessa skäl inte räcker för att övertyga dig om vikten av datamodellering, låt oss också titta på fördelarna det medför för mjukvaruutveckling.
Minskade utvecklingskostnader
I de tidiga stadierna av ett utvecklingsprojekt när budgeten analyseras kan behovet av att lägga kraft på att bygga en datamodell ifrågasättas. Om projektledarna och cheferna är smarta nog kommer de att jämföra vad det kostar att bygga och underhålla en datamodell med de kostnader som kommer att sparas och besluta sig för att bygga modellen.
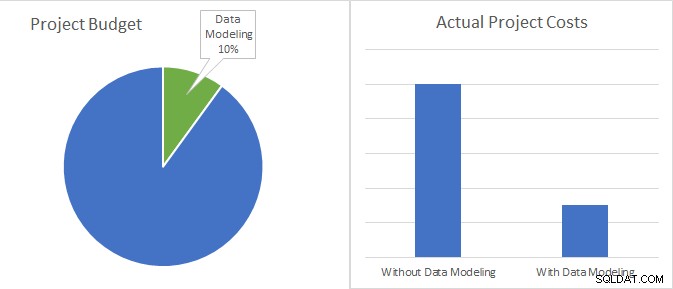
Datamodellering är bara 10 % av en utvecklingsprojektbudget och har potential att minska de faktiska projektkostnaderna till mindre än en tredjedel.
Tänk bara på följande. I de flesta fall är kostnaden för datamodellering (det vill säga kostnaden för den ansträngning som krävs för att bygga och underhålla modellen) mindre än 10 % av den totala budgeten för ett programvaruprojekt. I jämförelse är kostnadsbesparingarna förknippade med att använda datamodeller upp till 70 %, allt från minskningarna av timmarna för kodning och underhåll.
Så inom mjukvaruutveckling är det första och viktigaste skälet att göra datamodellering den obestridliga ROI (return on investment), som projektledare måste överväga i de tidiga stadierna av varje projekt.
Bättre definitioner av krav
Inom mjukvaruutveckling kan du garantera en större förståelse för det system som ska utvecklas om datamodelleringsaktiviteter genomförs parallellt med kravinsamling. Kraven blir mer kompletta och mer korrekta.
Datamodellering hjälper till att avslöja affärsregler och ställa frågor under kravutveckling, samtidigt som dataintegriteten säkerställs. Det är mer effektivt än processmodelleringsaktiviteter som användningsfallsdesign eller arbetsflödesdesign, och uppenbarligen mer uttrycksfullt och mindre utförligt än prosabeskrivningen av affärsreglerna.
Snabbare utveckling
När utvecklare har ordentliga datamodeller till hands kan de göra sitt jobb med färre fel. Datamodelleringsverktyg genererar och underhåller automatiskt databasscheman och skapar DDL-skript (Data Definition Language) som ofta är för långa, komplexa och röriga för utvecklare att generera manuellt.
Dessa verktyg främjar i sin tur samarbete genom att tillåta modeller att delas mellan utvecklare. När ändringar behövs kan du göra dem i datamodellen, vilket säkerställer att alla utvecklare kommer att informeras och att de kommer att tillämpas på databaserna utan att bryta något.
Allt detta gör att systemen kan levereras snabbare och med färre buggar.
Förbättra agila metoder
Agila metoder syftar till att påskynda utvecklingsprocessen genom att fokusera ansträngningarna på att leverera fungerande mjukvara och undvika byråkrati, överdriven dokumentation och faser som exekveras en efter en.
Databasmodellering står inför en betydande utmaning när man arbetar i agila miljöer, eftersom designern måste kunna arbeta med "den stora bilden", medan utvecklare bara behöver de dataobjekt som krävs för varje användarberättelse. För att nå konsensus mellan datamodellerare och utvecklare använder agila metoder tekniker som sandboxing och förgrening .
En sandlåda är arbetsmiljön för varje utvecklare. Designern kan arbeta med grenarna av huvuddatamodellen i sandlådan för varje utvecklare, som kommer att ge feedback för att förfina den. I slutet av varje steg (eller sprint) slår databasdesignern samman de olika grenarna för att hålla hela modellen uppdaterad.
Du kanske tror att datamodellering saktar ner agila team och att utvecklare måste vänta tills modellerna är redo att börja sitt arbete. Men i verkligheten, att använda tekniker som sandboxning och förgrening upprätthåller principerna för smidighet och uppnår samtidigt hastighetsförbättringarna som nämns ovan.
Vad händer om jag inte använder datamodeller?
Du kanske tror att du fortfarande kan överleva utan fördelarna med datamodeller som nämnts hittills för att spara tid. Men om du väljer bort datamodellering riskerar du att stöta på allvarliga problem som:
- Onödig redundans:Eftersom det inte finns någon modell för att se dataobjekten tydligt, kommer olika versioner av samma objekt att visas med olika information. Till exempel kan ett lagersystem rapportera att 500 enheter av en vara såldes under den senaste månaden, medan ett logistiksystem kan rapportera att 1000 enheter av samma vara har skickats under samma period. Vilket är rätt? Vem vet.
- Slåga appar:Frånvaron av en datamodell gör optimeringsuppgifter svåra, vilket minskar apparnas lyhördhet.
- Oförmåga att uppfylla kvalitetsstandarder:Om det inte finns någon datamodell kommer dina databaser inte att dokumenteras, vilket är obligatoriskt i scenarier som databasmigreringar.
- Dålig mjukvarukvalitet:Kraven på mjukvaruutveckling kommer att vara dåliga och användarna kommer inte att ha de applikationer de behöver eller önskar.
- Högre utvecklingskostnader:Jag har redan nämnt de betydande kostnadsbesparingar som kan uppnås i ett utvecklingsprojekt genom att använda datamodeller. Om du väljer att inte använda dem måste du bestämma vem som ska betala för de extra utvecklings- och underhållskostnaderna. Och vem kommer med ursäkter när tidsfristerna inte hålls.
Är du fortfarande inte övertygad?
Om det du har läst hittills inte räcker för att övertyga dig om vikten av datamodellering, kom ihåg att data blir en alltmer värdefull tillgång för alla typer av organisationer. Att modellera strukturerna för att dra nytta av information har oöverträffad relevans idag.
Tänk på detta:under guldrushen var killarna som tjänade mest pengar inte de som grävde efter guldkorn utan snarare de som gav verktygen för att utvinna guldet. År 2021 kommer guldkorn i form av insiktsfull information, och gruvarbetarna som utvinner sådant värdefullt material måste förses med datamodeller.