I del 2 av den här serien lade du till möjligheten att spara ändringar som gjorts via REST API till en databas med SQLAlchemy och lärde dig hur man serialiserar dessa data för REST API med Marshmallow. Att ansluta REST API till en databas så att applikationen kan göra ändringar i befintliga data och skapa nya data är jättebra och gör applikationen mycket mer användbar och robust.
Det är dock bara en del av kraften en databas erbjuder. En ännu kraftfullare funktion är R del av RDBMS system:relationer . I en databas är en relation förmågan att koppla samman två eller flera tabeller på ett meningsfullt sätt. I den här artikeln får du lära dig hur du implementerar relationer och förvandlar din Person databas till en miniblogg-webbapplikation.
I den här artikeln får du lära dig:
- Varför mer än en tabell i en databas är användbar och viktig
- Hur tabeller är relaterade till varandra
- Hur SQLAlchemy kan hjälpa dig att hantera relationer
- Hur relationer hjälper dig att bygga en minibloggapplikation
Vem den här artikeln är till för
Del 1 av den här serien guidade dig genom att bygga ett REST API, och del 2 visade hur du ansluter det REST API till en databas.
Den här artikeln utökar ditt programmeringsverktygsbälte ytterligare. Du kommer att lära dig hur du skapar hierarkiska datastrukturer representerade som en-till-många-relationer av SQLAlchemy. Dessutom utökar du REST API som du redan har byggt för att ge CRUD-stöd (Skapa, läs, uppdatera och ta bort) för elementen i denna hierarkiska struktur.
Webbapplikationen som presenteras i del 2 kommer att ha sina HTML- och JavaScript-filer modifierade på stora sätt för att skapa en mer fullt fungerande minibloggapplikation. Du kan granska den slutliga versionen av koden från del 2 i GitHub-arkivet för den artikeln.
Vänta medan du börjar skapa relationer och din minibloggapplikation!
Ytterligare beroenden
Det finns inga nya Python-beroenden utöver vad som krävdes för del 2-artikeln. Du kommer dock att använda två nya JavaScript-moduler i webbapplikationen för att göra saker enklare och mer konsekventa. De två modulerna är följande:
- Handlebars.js är en mallmotor för JavaScript, ungefär som Jinja2 för Flask.
- Moment.js är en datetime parsing- och formateringsmodul som gör det enklare att visa UTC-tidsstämplar.
Du behöver inte ladda ner någon av dessa, eftersom webbapplikationen får dem direkt från Cloudflare CDN (Content Delivery Network), som du redan gör för jQuery-modulen.
Persondata utökas för bloggning
I del 2, People data fanns som en ordbok i build_database.py Python-kod. Detta är vad du använde för att fylla databasen med några initiala data. Du kommer att ändra People datastruktur för att ge varje person en lista med anteckningar associerade med dem. Det nya People datastrukturen kommer att se ut så här:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Varje person i People ordboken innehåller nu en nyckel som heter notes , som är associerad med en lista som innehåller tuplar av data. Varje tupel i notes listan representerar en enda anteckning som innehåller innehållet och en tidsstämpel. Tidsstämplarna initieras (snarare än dynamiskt skapade) för att demonstrera beställning senare i REST API.
Varje enskild person är associerad med flera anteckningar, och varje enskild anteckning är associerad med endast en person. Denna hierarki av data är känd som en en-till-många-relation, där ett enskilt överordnat objekt är relaterat till många underordnade objekt. Du kommer att se hur denna en-till-många-relation hanteras i databasen med SQLAlchemy.
Brute Force Approach
Databasen du byggde lagrade data i en tabell, och en tabell är en tvådimensionell uppsättning av rader och kolumner. Kan People ordboken ovan representeras i en enda tabell med rader och kolumner? Det kan vara, på följande sätt, i din person databastabell. Att inkludera alla faktiska data i exemplet skapar tyvärr en rullningslist för tabellen, som du ser nedan:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Cool, en minibloggapplikation! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Det här kan vara användbart | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Tja, lite användbart | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Jag ska göra riktigt djupgående observationer | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Kanske blir de mer uppenbara än jag trodde | 2019-02-06 22:17:54 |
| 6 | Påsk | Kanin | 2018-08-08 21:16:01 | Har någon sett mina påskägg? | 2019-01-07 22:47:54 |
| 7 | Påsk | Kanin | 2018-08-08 21:16:01 | Jag är verkligen sen med att leverera dessa! | 2019-04-06 22:17:54 |
Tabellen ovan skulle faktiskt fungera. All data är representerad, och en enda person är associerad med en samling olika anteckningar.
Fördelar
Konceptuellt har ovanstående tabellstruktur fördelen att den är relativt enkel att förstå. Du kan till och med hävda att data kan sparas till en platt fil istället för en databas.
På grund av den tvådimensionella tabellstrukturen kan du lagra och använda dessa data i ett kalkylblad. Kalkylblad har tagits i bruk som datalagring en hel del.
Nackdelar
Även om ovanstående tabellstruktur skulle fungera, har den några verkliga nackdelar.
För att representera samlingen av anteckningar upprepas all data för varje person för varje unik anteckning, persondata är därför överflödig. Det här är inte så stor sak för dina personuppgifter eftersom det inte finns så många kolumner. Men tänk om en person hade många fler kolumner. Även med stora hårddiskar kan detta bli ett lagringsproblem om du har att göra med miljontals rader med data.
Att ha överflödig data som denna kan leda till underhållsproblem med tiden. Tänk till exempel om påskharen bestämde sig för att byta namn var en bra idé. För att göra detta måste varje post som innehåller påskharens namn uppdateras för att hålla uppgifterna konsekventa. Denna typ av arbete mot databasen kan leda till datainkonsekvens, särskilt om arbetet utförs av en person som kör en SQL-fråga för hand.
Att namnge kolumner blir besvärligt. I tabellen ovan finns en timestamp kolumn som används för att spåra skapandet och uppdateringstiden för en person i tabellen. Du vill också ha liknande funktionalitet för att skapa och uppdatera tid för en anteckning, men eftersom timestamp redan används, ett konstruerat namn på note_timestamp används.
Tänk om du ville lägga till ytterligare en-till-många-relationer till person tabell? Till exempel att inkludera en persons barn eller telefonnummer. Varje person kan ha flera barn och flera telefonnummer. Detta kan göras relativt enkelt för Python People ordboken ovan genom att lägga till children och phone_numbers nycklar med nya listor som innehåller data.
Men representerar de nya en-till-många-relationerna i din person databastabellen ovan blir betydligt svårare. Varje ny en-till-många-relation ökar antalet rader som krävs för att representera den för varje enskild post i underordnade data dramatiskt. Dessutom blir problemen i samband med dataredundans större och svårare att hantera.
Slutligen, data du skulle få tillbaka från ovanstående tabellstruktur skulle inte vara särskilt pytonisk:det skulle bara vara en stor lista med listor. SQLAlchemy skulle inte kunna hjälpa dig särskilt mycket eftersom relationen inte finns där.
Relationsdatabasmetoden
Baserat på vad du har sett ovan, blir det tydligt att det blir ohanterligt ganska snabbt att försöka representera även en måttligt komplex datauppsättning i en enda tabell. Med tanke på det, vilket alternativ erbjuder en databas? Det är här R del av RDBMS databaser spelar in. Att representera relationer tar bort de ovan beskrivna nackdelarna.
Istället för att försöka representera hierarkiska data i en enda tabell, delas data upp i flera tabeller, med en mekanism för att relatera dem till varandra. Tabellerna är uppdelade längs insamlingslinjer, så för dina People ordboken ovan betyder det att det kommer att finnas en tabell som representerar personer och en annan som representerar anteckningar. Detta tar tillbaka din ursprungliga person tabell, som ser ut så här:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Påsk | Kanin | 2018-08-08 21:16:01.886834 |
För att representera den nya anteckningsinformationen skapar du en ny tabell som heter note . (Kom ihåg vår singular tabellnamnkonvention.) Tabellen ser ut så här:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Cool, en minibloggapplikation! | 2019-01-06 22:17:54 |
| 2 | 1 | Det här kan vara användbart | 2019-01-08 22:17:54 |
| 3 | 1 | Tja, lite användbart | 2019-03-06 22:17:54 |
| 4 | 2 | Jag ska göra riktigt djupgående observationer | 2019-01-07 22:17:54 |
| 5 | 2 | Kanske blir de mer uppenbara än jag trodde | 2019-02-06 22:17:54 |
| 6 | 3 | Har någon sett mina påskägg? | 2019-01-07 22:47:54 |
| 7 | 3 | Jag är verkligen sen med att leverera dessa! | 2019-04-06 22:17:54 |
Lägg märke till att, som person tabellen, note tabellen har en unik identifierare som heter note_id , som är den primära nyckeln för note tabell. En sak som inte är uppenbar är inkluderingen av person_id värde i tabellen. Vad används det till? Det är detta som skapar relationen till person tabell. Medan note_id är den primära nyckeln för tabellen, person_id är vad som kallas en främmande nyckel.
Den främmande nyckeln ger varje post i note tabell primärnyckeln för person spela in den är kopplad till. Med detta kan SQLAlchemy samla alla anteckningar som är associerade med varje person genom att ansluta person.person_id primärnyckeln till note.person_id främmande nyckel, skapa en relation.
Fördelar
Genom att dela upp datamängden i två tabeller och introducera konceptet med en främmande nyckel, har du gjort data lite mer komplex att tänka på, du har löst nackdelarna med en enskild tabellrepresentation. SQLAlchemy hjälper dig att koda den ökade komplexiteten ganska enkelt.
Uppgifterna är inte längre redundanta i databasen. Det finns bara en personpost för varje person du vill lagra i databasen. Detta löser lagringsproblemet omedelbart och förenklar underhållsproblemen dramatiskt.
Om påskharen fortfarande ville byta namn, skulle du bara behöva ändra en enda rad i person tabell och allt annat relaterat till den raden (som note tabell) skulle omedelbart dra nytta av förändringen.
Kolumnnamn är mer konsekvent och meningsfullt. Eftersom person- och anteckningsdata finns i separata tabeller kan tidsstämpeln för skapande och uppdatering namnges konsekvent i båda tabellerna, eftersom det inte finns någon konflikt för namn mellan tabeller.
Dessutom skulle du inte längre behöva skapa permutationer för varje rad för nya en-till-många-relationer som du kanske vill representera. Ta våra children och phone_numbers exempel från tidigare. Att implementera detta skulle kräva children och phone_numbers tabeller. Varje tabell skulle innehålla en främmande nyckel av person_id relatera det tillbaka till person bord.
Genom att använda SQLAlchemy skulle data du får tillbaka från ovanstående tabeller vara mer omedelbart användbar, eftersom det du får är ett objekt för varje personrad. Det objektet har namngivna attribut som motsvarar kolumnerna i tabellen. Ett av dessa attribut är en Python-lista som innehåller de relaterade anteckningsobjekten.
Nackdelar
Där brute force-metoden var enklare att förstå, gör konceptet med främmande nycklar och relationer tänkandet om data något mer abstrakt. Denna abstraktion måste övervägas för varje relation du upprättar mellan tabeller.
Att använda relationer innebär att åta sig att använda ett databassystem. Detta är ytterligare ett verktyg för att installera, lära sig och underhålla utöver det program som faktiskt använder data.
SQLAlchemy-modeller
För att använda de två tabellerna ovan, och förhållandet mellan dem, måste du skapa SQLAlchemy-modeller som är medvetna om båda tabellerna och förhållandet mellan dem. Här är SQLAlchemy Person modell från del 2, uppdaterad för att inkludera en relation till en samling notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Raderna 1 till 8 i ovanstående Python-klass ser exakt ut som det du skapade tidigare i del 2. Raderna 9 till 16 skapar ett nytt attribut i Person klass som heter notes . Denna nya notes attribut definieras i följande kodrader:
-
Rad 9: Liksom de andra attributen i klassen skapar den här raden ett nytt attribut som heter
notesoch sätter den lika med en instans av ett objekt som heterdb.relationship. Det här objektet skapar relationen du lägger tillPersonklass och skapas med alla parametrar definierade i raderna som följer. -
Rad 10: Strängparametern
'Note'definierar SQLAlchemy-klassen somPersonklass kommer att vara relaterad till.Noteklass är inte definierad ännu, varför det är en sträng här. Detta är en framåtriktad referens och hjälper till att hantera problem som definitionsordningen kan orsaka när något behövs som inte definieras förrän senare i koden.'Note'sträng tillåterPersonklass för att hittaNoteklass vid körning, vilket är efter bådaPersonochNotehar definierats. -
Rad 11:
backref='person'parametern är svårare. Det skapar vad som kallas en bakåtreferens iNoteföremål. Varje instans av enNoteobjektet kommer att innehålla ett attribut som heterperson.personattribut refererar till det överordnade objektet som en vissNoteinstans är förknippad med. Att ha en referens till det överordnade objektet (personi det här fallet) i barnet kan vara mycket användbart om din kod itererar över anteckningar och måste inkludera information om föräldern. Detta händer förvånansvärt ofta i visningsrenderingskod. -
Rad 12:
cascade='all, delete, delete-orphan'parametern bestämmer hur anteckningsobjektinstanser ska behandlas när ändringar görs i den överordnadePersonexempel. Till exempel när enPersonobjekt raderas, kommer SQLAlchemy att skapa den SQL som krävs för att raderaPersonfrån databasen. Dessutom säger den här parametern att den också ska radera allaNotefall som är förknippade med det. Du kan läsa mer om dessa alternativ i SQLAlchemy-dokumentationen. -
Rad 13:
single_parent=Trueparameter krävs omdelete-orphanär en del av den tidigarecascadeparameter. Detta talar om för SQLAlchemy att inte tillåta föräldralösaNoteinstanser (enNoteutan en förälderPersonobjekt) existerar eftersom varjeNotehar en ensamstående förälder. -
Rad 14:
order_by='desc(Note.timestamp)'parametern talar om för SQLAlchemy hur man sorterarNoteinstanser associerade med enPerson. När enPersonobjektet hämtas, som standardnotesattributlistan kommer att innehållaNoteföremål i okänd ordning. SQLAlchemydesc(...)funktionen kommer att sortera anteckningarna i fallande ordning från nyaste till äldsta. Om denna rad istället varorder_by='Note.timestamp', SQLAlchemy skulle som standard användaasc(...)funktion och sortera anteckningarna i stigande ordning, äldst till senaste.
Nu när din Person modellen har de nya notes attribut, och detta representerar en-till-många-relationen till Note objekt måste du definiera en SQLAlchemy-modell för en Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
Note klass definierar attributen som utgör en anteckning som visas i vårt exempel note databastabell från ovan. Attributen definieras här:
-
Rad 1 skapar
Noteklass, som ärver fråndb.Model, precis som du gjorde tidigare när du skapadePersonklass. -
Rad 2 talar om för klassen vilken databastabell som ska användas för att lagra
Noteobjekt. -
Rad 3 skapar
note_idattribut, som definierar det som ett heltalsvärde och som primärnyckel förNoteobjekt. -
Rad 4 skapar
person_idattribut, och definierar det som den främmande nyckeln, relaterat tillNoteklass tillPersonklass medperson.person_idprimärnyckel. Detta ochPerson.notesattribut, är hur SQLAlchemy vet vad man ska göra när man interagerar medPersonochNoteobjekt. -
Rad 5 skapar
contentattribut, som innehåller själva texten i anteckningen.nullable=Falseparametern indikerar att det är okej att skapa nya anteckningar som inte har något innehåll. -
Rad 6 skapar
timestampattribut och exakt somPersonklass, innehåller detta skapandet eller uppdateringstiden för en vissNoteinstans.
Initiera databasen
Nu när du har uppdaterat Person och skapade Note modeller, använder du dem för att bygga om testdatabasen people.db . Du gör detta genom att uppdatera build_database.py kod från del 2. Så här kommer koden att se ut:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Koden ovan kom från del 2, med några ändringar för att skapa en-till-många-relationen mellan Person och Note . Här är de uppdaterade eller nya raderna som lagts till i koden:
-
Rad 4 har uppdaterats för att importera
Noteklass definierad tidigare. -
Rad 7 till 39 innehålla den uppdaterade
PEOPLEordbok som innehåller våra personuppgifter, tillsammans med listan över anteckningar för varje person. Dessa data kommer att infogas i databasen. -
Rad 49 till 61 iterera över
PEOPLEordbok, får varjepersoni sin tur och använda den för att skapa enPersonobjekt. -
Linje 53 itererar över
person.noteslista, hämtar varjenotei sin tur. -
Linje 54 packar upp
contentochtimestampfrån varjenotetuppel. -
Rad 55 till 60 skapar en
Noteobjekt och lägger till det i personanteckningssamlingen medp.notes.append(). -
Linje 61 lägger till
Personobjektptill databassessionen. -
Linje 63 överför all aktivitet i sessionen till databasen. Det är vid denna tidpunkt som all data skrivs till
personochnotetabeller ipeople.dbdatabasfil.
Du kan se att det fungerar med notes samling i Person objektinstans p är precis som att arbeta med vilken lista som helst i Python. SQLAlchemy tar hand om den underliggande en-till-många-relationsinformationen när db.session.commit() samtal görs.
Till exempel precis som en Person instans har sitt primära nyckelfält person_id initieras av SQLAlchemy när den är ansluten till databasen, instanser av Note kommer att få sina primära nyckelfält initierade. Dessutom, Note främmande nyckel person_id kommer också att initieras med det primära nyckelvärdet för Person instans den är kopplad till.
Här är ett exempel på en Person objekt före db.session.commit() i en slags pseudokod:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Här är exemplet på Person objekt efter db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Den viktiga skillnaden mellan de två är att den primära nyckeln för Person och Note objekt har initierats. Databasmotorn tog hand om detta när objekten skapades på grund av den automatiska inkrementeringsfunktionen hos primärnycklar som diskuteras i del 2.
Dessutom, person_id främmande nyckel i alla Note instanser har initierats för att referera till dess överordnade. Detta händer på grund av den ordning i vilken Person och Note objekt skapas i databasen.
SQLAlchemy är medveten om förhållandet mellan Person och Note föremål. När en Person objektet är engagerat i person databastabell, SQLAlchemy får person_id primärnyckelvärde. Det värdet används för att initiera det främmande nyckelvärdet för person_id i en Note objekt innan det har anslutits till databasen.
SQLAlchemy tar hand om detta databashushållningsarbete på grund av informationen du skickade när Person.notes attributet initierades med db.relationship(...) objekt.
Dessutom, Person.timestamp attributet har initierats med den aktuella tidsstämpeln.
Kör build_database.py program från kommandoraden (i den virtuella miljön återskapar databasen med de nya tilläggen, gör den redo för användning med webbapplikationen. Denna kommandorad kommer att bygga om databasen:
$ python build_database.py
build_database.py verktygsprogrammet matar inte ut några meddelanden om det körs framgångsrikt. Om det ger ett undantag, kommer ett fel att skrivas ut på skärmen.
Uppdatera REST API
Du har uppdaterat SQLAlchemy-modellerna och använt dem för att uppdatera people.db databas. Nu är det dags att uppdatera REST API för att ge tillgång till den nya anteckningsinformationen. Här är REST API som du byggde i del 2:
| Åtgärd | HTTP-verb | URL-sökväg | Beskrivning |
|---|---|---|---|
| Skapa | POST | /api/people | URL för att skapa en ny person |
| Läs | GET | /api/people | URL för att läsa en samling personer |
| Läs | GET | /api/people/{person_id} | URL för att läsa en enskild person av person_id |
| Uppdatera | PUT | /api/people/{person_id} | URL för att uppdatera en befintlig person med person_id |
| Ta bort | DELETE | /api/people/{person_id} | URL för att radera en befintlig person med person_id |
REST API ovan tillhandahåller HTTP URL-vägar till samlingar av saker och till själva sakerna. Du kan få en lista över personer eller interagera med en enda person från den listan med personer. Denna vägstil förfinar det som returneras på ett vänster-till-höger-sätt och blir mer detaljerat allt eftersom.
Du fortsätter det här mönstret från vänster till höger för att bli mer detaljerat och komma åt anteckningssamlingarna. Här är det utökade REST API som du skapar för att ge anteckningar till miniblogg-webbapplikationen:
| Åtgärd | HTTP-verb | URL-sökväg | Beskrivning |
|---|---|---|---|
| Skapa | POST | /api/people/{person_id}/notes | URL för att skapa en ny anteckning |
| Läs | GET | /api/people/{person_id}/notes/{note_id} | URL för att läsa en enskild persons anteckning |
| Uppdatera | PUT | api/people/{person_id}/notes/{note_id} | URL för att uppdatera en enskild persons anteckning |
| Ta bort | DELETE | api/people/{person_id}/notes/{note_id} | URL för att ta bort en enskild persons anteckning |
| Läs | GET | /api/notes | URL för att få alla anteckningar för alla personer sorterade efter note.timestamp |
Det finns två varianter av notes del av REST API jämfört med konventionen som används i people avsnitt:
-
Det finns ingen URL definierad för att få alla
noteskopplat till en person, bara en URL för att få en enda anteckning. Detta skulle ha gjort REST API komplett på ett sätt, men webbapplikationen du skapar senare behöver inte den här funktionen. Därför har den utelämnats. -
Det finns inkluderingen av den sista URL:en
/api/notes. Detta är en bekvämlighetsmetod skapad för webbapplikationen. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml fil.
Obs!
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relationship. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes list. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Obs!
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or drift. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
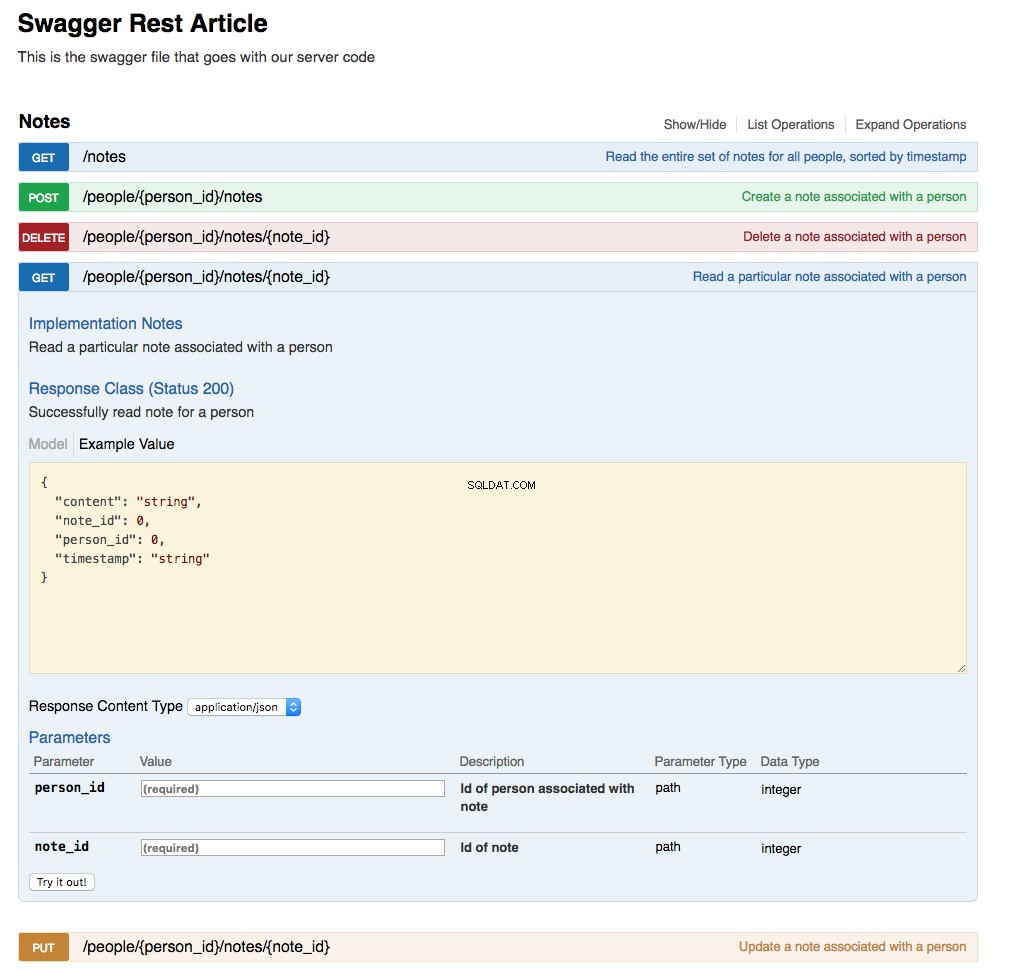
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
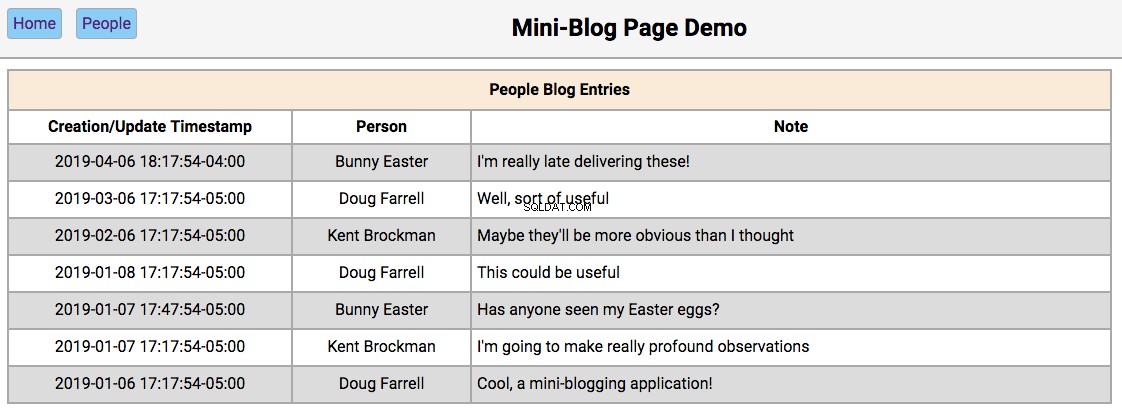
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
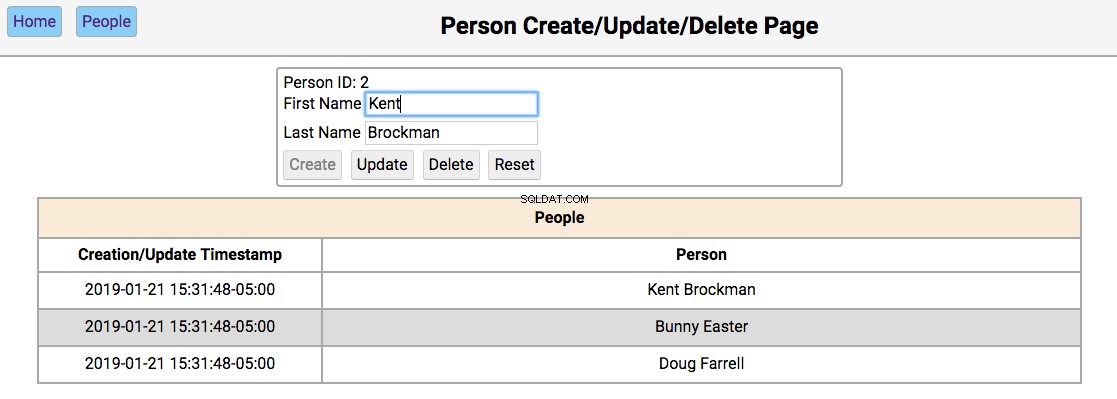
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
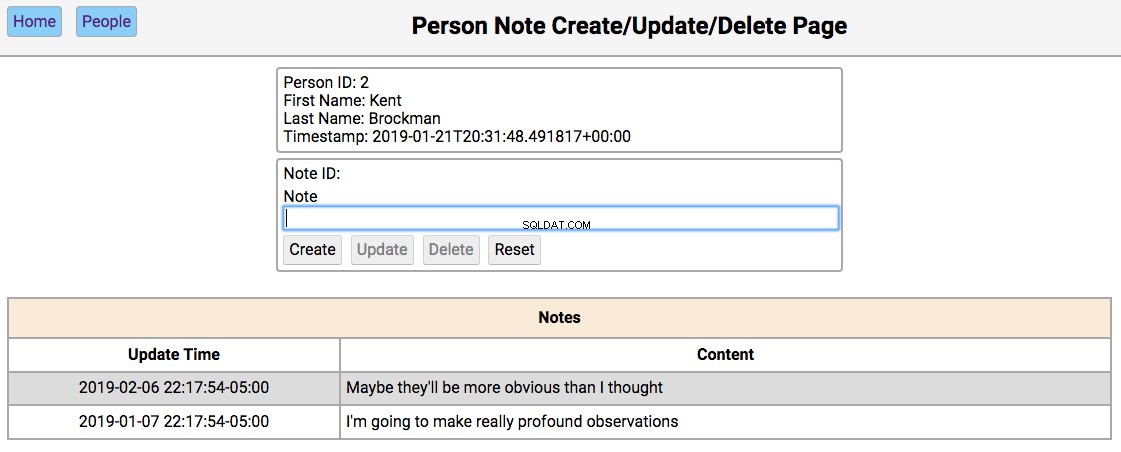
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Slutsats
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »