Begreppet bra eller dålig design är relativt. Samtidigt finns det några programmeringsstandarder som i de flesta fall garanterar effektivitet, underhållbarhet och testbarhet. Till exempel i objektorienterade språk är detta användningen av inkapsling, arv och polymorfism. Det finns en uppsättning designmönster som i ett antal fall har en positiv eller negativ effekt på applikationsdesignen beroende på situationen. Å andra sidan finns det motsatser, vilket ibland leder till problemdesignen.
Denna design har vanligtvis följande indikatorer (en eller flera åt gången):
- Styvhet (det är svårt att ändra koden, eftersom en enkel ändring påverkar många platser);
- Immobilitet (det är komplicerat att dela upp koden i moduler som kan användas i andra program);
- Viskositet (det är ganska svårt att utveckla eller testa koden);
- Onödig komplexitet (det finns en oanvänd funktion i koden);
- Onödiga upprepningar (kopiera/klistra in);
- Dålig läsbarhet (det är svårt att förstå vad koden är designad för och att underhålla den);
- Bräcklighet (det är lätt att bryta funktionalitet även med små ändringar).
Du måste kunna förstå och särskilja dessa funktioner för att undvika en problemdesign eller för att förutse möjliga konsekvenser av dess användning. Dessa indikatorer beskrivs i boken «Agile Principles, Patterns, And Practices in C#» av Robert Martin. Det finns dock en kort beskrivning och inga kodexempel i den här artikeln och i andra översiktsartiklar.
Vi kommer att eliminera denna nackdel med varje funktion.
Styvhet
Som det har nämnts är en stel kod svår att modifiera, även de minsta sakerna. Detta kanske inte är ett problem om koden inte ändras ofta eller alls. Således visar sig koden vara ganska bra. Men om det är nödvändigt att modifiera koden och svårt att göra detta, blir det ett problem, även om det fungerar.
Ett av de populära rigiditetsfallen är att explicit specificera klasstyperna istället för att använda abstraktioner (gränssnitt, basklasser, etc.). Nedan hittar du ett exempel på koden:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Här beror klass A på klass B väldigt mycket. Så om du i framtiden behöver använda en annan klass istället för klass B, kommer detta att kräva att du byter klass A och kommer att leda till att den testas om. Dessutom, om klass B påverkar andra klasser, kommer situationen att bli mycket komplicerad.
Lösningen är en abstraktion som är att introducera IComponent-gränssnittet via konstruktorn av klass A. I det här fallet kommer det inte längre att bero på den specifika klassen В och kommer bara att bero på IComponent-gränssnittet. Сlass В måste i sin tur implementera IComponent-gränssnittet.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Låt oss ge ett specifikt exempel. Anta att det finns en uppsättning klasser som loggar informationen – ProductManager och Consumer. Deras uppgift är att lagra en produkt i databasen och beställa den på motsvarande sätt. Båda klasserna loggar relevanta händelser. Föreställ dig att det först fanns en inloggning till en fil. För att göra detta användes klassen FileLogger. Dessutom var klasserna placerade i olika moduler (sammansättningar).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Om det först räckte att bara använda filen, och sedan blir det nödvändigt att logga in på andra arkiv, till exempel en databas eller en molnbaserad datainsamling och lagringstjänst, måste vi ändra alla klasser i affärslogiken modul (Modul 2) som använder FileLogger. Detta kan trots allt visa sig vara svårt. För att lösa det här problemet kan vi introducera ett abstrakt gränssnitt för att fungera med loggern, som visas nedan.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} I det här fallet, när du ändrar en loggertyp, räcker det med att ändra klientkoden (Main), som initierar loggern och lägger till den i konstruktören av ProductManager och Consumer. Därför stängde vi klasserna för affärslogik från modifiering av loggertypen efter behov.
Förutom direktlänkar till de använda klasserna kan vi övervaka stelhet i andra varianter som kan leda till svårigheter vid modifiering av koden. Det kan finnas en oändlig uppsättning av dem. Vi ska dock försöka ge ett annat exempel. Anta att det finns en kod som visar arean av ett geometriskt mönster på konsolen.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Som du kan se, när vi lägger till ett nytt mönster, måste vi ändra metoderna för ShapeHelper-klassen. Ett av alternativen är att passera algoritmen för rendering i klasserna av geometriska mönster (rektangel och cirkel), som visas nedan. På detta sätt kommer vi att isolera den relevanta logiken i motsvarande klasser och därigenom minska ansvaret för ShapeHelper-klassen innan information visas på konsolen.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} Som ett resultat stängde vi faktiskt ShapeHelper-klassen för ändringar som lägger till nya typer av mönster genom att använda arv och polymorfism.
Orörlighet
Vi kan övervaka orörlighet när vi delar upp koden i återanvändbara moduler. Som ett resultat kan projektet sluta utvecklas och vara konkurrenskraftigt.
Som ett exempel kommer vi att överväga ett skrivbordsprogram, vars hela kod är implementerad i den körbara applikationsfilen (.exe) och har utformats så att affärslogiken inte är inbyggd i separata moduler eller klasser. Senare har utvecklaren ställts inför följande affärskrav:
- För att ändra användargränssnittet genom att förvandla det till en webbapplikation;
- Att publicera programmets funktionalitet som en uppsättning webbtjänster tillgängliga för tredjepartsklienter för att användas i deras egna applikationer.
I det här fallet är dessa krav svåra att uppfylla, eftersom hela koden finns i den körbara modulen.
Bilden nedan visar ett exempel på en immobil design i motsats till den som inte har denna indikator. De är åtskilda av en strecklinje. Som du kan se tillåter allokeringen av koden på återanvändbara moduler (Logic), såväl som publiceringen av funktionaliteten på nivån för webbtjänster, att använda den i olika klientapplikationer (App), vilket är en otvivelaktig fördel.
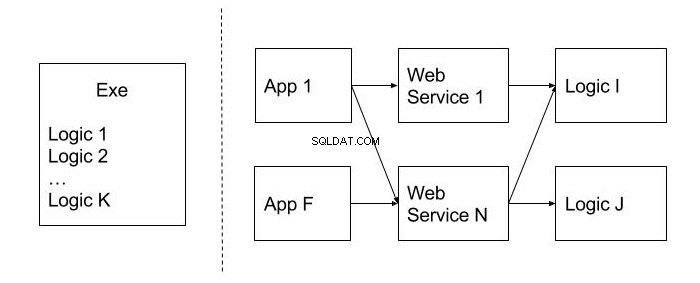
Orörlighet kan också kallas en monolitisk design. Det är svårt att dela upp det i mindre och användbara enheter av koden. Hur kan vi undvika denna fråga? På designstadiet är det bättre att tänka på hur troligt det är att använda den här eller den funktionen i andra system. Koden som förväntas återanvändas är bäst att placeras i separata moduler och klasser.
Viskositet
Det finns två typer:
- Utvecklingsviskositet
- Miljöviskositet
Vi kan se utvecklingsviskositet när vi försöker följa den valda applikationsdesignen. Detta kan hända när en programmerare måste uppfylla för många krav samtidigt som det finns ett enklare sätt att utveckla. Dessutom kan utvecklingsviskositeten ses när processen för montering, driftsättning och testning inte är effektiv.
Som ett enkelt exempel kan vi betrakta arbetet med konstanter som ska placeras (By Design) i en separat modul (Modul 1) för att användas av andra komponenter (Modul 2 och Modul 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Om monteringsprocessen av någon anledning tar mycket tid kommer det att vara svårt för utvecklare att vänta tills den är klar. Dessutom bör det noteras att konstantmodulen innehåller blandade enheter som tillhör olika delar av affärslogiken (ekonomi- och marknadsföringsmoduler). Så konstantmodulen kan ändras ganska ofta av skäl som är oberoende av varandra, vilket kan leda till ytterligare problem som synkronisering av ändringarna.
Allt detta saktar ner utvecklingsprocessen och kan stressa programmerare. Varianterna av den mindre trögflytande designen skulle vara att antingen skapa separata konstantmoduler – av en för motsvarande modul av affärslogik – eller att skicka konstanter till rätt plats utan att ta en separat modul för dem.
Ett exempel på miljöns viskositet kan vara utveckling och testning av applikationen på den virtuella fjärrklienten. Ibland blir det här arbetsflödet outhärdligt på grund av en långsam internetanslutning, så utvecklaren kan systematiskt ignorera integrationstestningen av den skrivna koden, vilket så småningom kan leda till buggar på klientsidan när den här funktionen används.
Onödig komplexitet
I det här fallet har designen faktiskt oanvänd funktionalitet. Detta faktum kan komplicera stödet och underhållet av programmet, samt öka utvecklings- och testtiden. Tänk till exempel på programmet som kräver att vissa data läses från databasen. För att göra detta skapades DataManager-komponenten, som används i en annan komponent.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Om utvecklaren lägger till en ny metod i DataManager för att skriva data till databasen (WriteData), som sannolikt inte kommer att användas i framtiden, kommer det också att vara en onödig komplexitet.
Ett annat exempel är ett gränssnitt för alla ändamål. Till exempel kommer vi att överväga ett gränssnitt med den enda processmetoden som accepterar ett objekt av strängtypen.
interface IProcessor
{
void Process(string message);
} Om uppgiften var att bearbeta en viss typ av meddelande med en väldefinierad struktur, skulle det vara lättare att skapa ett strikt maskinskrivet gränssnitt, snarare än att få utvecklare att deserialisera denna sträng till en viss meddelandetyp varje gång.
Att överanvända designmönster i fall där detta inte alls är nödvändigt kan också leda till viskositetsdesign.
Varför slösa din tid på att skriva en potentiellt oanvänd kod? Ibland ska QA testa den här koden, eftersom den faktiskt publiceras och är öppen för användning av tredjepartsklienter. Detta skjuter också upp releasetiden. Att inkludera en funktion för framtiden är bara värt om dess möjliga nytta överstiger kostnaderna för dess utveckling och testning.
Onödiga upprepningar
Kanske har de flesta utvecklare stött på eller kommer att stöta på den här funktionen, som består i att flera kopiera samma logik eller koden. Det största hotet är sårbarheten hos den här koden när du ändrar den – genom att fixa något på ett ställe kan du glömma att göra detta på ett annat. Dessutom tar det längre tid att göra ändringar i jämförelse med situationen när koden inte innehåller denna funktion.
Onödiga upprepningar kan bero på försumlighet från utvecklare, såväl som på grund av styvhet/bräcklighet i design när det är mycket svårare och mer riskabelt att inte upprepa koden snarare än att göra detta. Men i alla fall är repeterbarhet ingen bra idé, och det är nödvändigt att ständigt förbättra koden och skicka återanvändbara delar till vanliga metoder och klasser.
Dålig läsbarhet
Du kan övervaka den här funktionen när det är svårt att läsa en kod och förstå vad den är skapad för. Orsakerna till dålig läsbarhet kan vara bristande efterlevnad av kraven för kodexekveringen (syntax, variabler, klasser), en komplicerad implementeringslogik, etc.
Nedan hittar du exemplet på den svårlästa koden, som implementerar metoden med den booleska variabeln.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Här kan vi beskriva flera frågor. För det första överensstämmer inte namn på metoder och variabler med allmänt accepterade konventioner. För det andra är implementeringen av metoden inte den bästa.
Kanske är det värt att ta ett booleskt värde snarare än en sträng. Det är dock bättre att konvertera det till ett booleskt värde i början av metoden, snarare än att använda metoden för att bestämma längden på strängen.
För det tredje överensstämmer inte texten med undantaget med den officiella stilen. När man läser sådana texter kan det uppstå en känsla av att koden är skapad av en amatör (fortfarande kan det vara en fråga i frågan). Metoden kan skrivas om enligt följande om den tar ett booleskt värde:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Här är ett annat exempel på refactoring om du fortfarande behöver ta en sträng:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Det rekommenderas att utföra refaktorisering med den svårlästa koden, till exempel när dess underhåll och kloning leder till flera buggar.
Bräcklighet
Ett programs bräcklighet innebär att det lätt kan kraschas när det ändras. Det finns två typer av krascher:kompileringsfel och körtidsfel. De första kan vara en baksida av stelhet. De senare är de farligaste eftersom de förekommer på klientsidan. Så de är en indikator på bräckligheten.
Utan tvekan är indikatorn relativ. Någon fixar koden mycket noggrant och risken för att den kraschar är ganska liten, medan andra gör detta i en hast och slarvigt. Ändå kan en annan kod med samma användare orsaka en annan mängd fel. Förmodligen kan vi säga att ju svårare det är att förstå koden och förlita sig på programmets körtid snarare än på kompileringsstadiet, desto ömtåligare är koden.
Dessutom kraschar ofta den funktionalitet som inte kommer att modifieras. Det kan lida av den höga kopplingen av logiken hos olika komponenter.
Tänk på det specifika exemplet. Här finns logiken för användarbehörighet med en viss roll (definierad som den rullade parametern) för att komma åt en viss resurs (definierad som resourceUri) i den statiska metoden.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Som du kan se är logiken komplicerad. Det är uppenbart att lägga till nya roller och resurser lätt kommer att bryta det. Som ett resultat kan en viss roll få eller förlora tillgång till en resurs. Att skapa resursklassen som internt lagrar resursidentifieraren och listan över roller som stöds, som visas nedan, skulle minska bräckligheten.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} I det här fallet, för att lägga till nya resurser och roller, är det inte nödvändigt att modifiera behörighetslogikkoden alls, det vill säga det finns faktiskt inget att bryta.
Vad kan hjälpa till att fånga körtidsfel? Svaret är manuell, automatisk och enhetstestning. Ju bättre testprocessen är organiserad, desto mer sannolikt är det att den ömtåliga koden kommer att inträffa på klientsidan.
Ofta är bräcklighet en baksida av andra identifierare av dålig design som styvhet, dålig läsbarhet och onödiga upprepningar.
Slutsats
Vi har försökt att skissera och beskriva de viktigaste identifierarna för dålig design. Vissa av dem är beroende av varandra. Du måste förstå att frågan om designen inte alltid oundvikligen leder till svårigheter. Det pekar bara på att de kan inträffa. Ju mindre dessa identifierare övervakas, desto lägre är sannolikheten.