Alla mina inlägg i år har handlat om knästötsreaktioner på väntestatistik, men i det här inlägget avviker jag från det temat för att prata om en speciell buggbjörn av mig:sidans räknare för förväntad livslängd (som jag kommer att kalla PLE) ).
Vad betyder PLE?
Det finns alla möjliga felaktiga påståenden om förväntad livslängd på sidan på Internet, och de mest allvarliga är de som anger att värdet 300 är tröskeln för var du bör vara orolig.
För att förstå varför detta påstående är så missvisande måste du förstå vad PLE faktiskt är.
Definitionen av PLE är den förväntade tiden, i sekunder, som en datafilsida som läses in i buffertpoolen (cachen i minnet för datafilsidor) kommer att finnas kvar i minnet innan den skjuts ut ur minnet för att ge plats åt annan data filsida. Ett annat sätt att tänka på PLE är ett omedelbart mått på trycket på buffertpoolen för att göra ledigt utrymme för sidor som läses från disken. För båda dessa definitioner är ett högre antal bättre.
Vad är en bra PLE-tröskel?
En PLE på 300 betyder att hela din buffertpool spolas effektivt och läses om var femte minut. När tröskelvägledningen för PLE på 300 först gavs av Microsoft, runt 2005/2006, kan den siffran ha varit mer vettig eftersom den genomsnittliga mängden minne på en server var mycket lägre.
Nuförtiden, där servrar rutinmässigt har 64 GB, 128 GB och högre mängder minne, skulle det troligen vara orsaken till ett förödande prestandaproblem att ha ungefär så mycket data som läses från disken var femte minut.
I verkligheten, när PLE svävar på eller under 300, är din server redan i svåra svårigheter. Du skulle börja bli orolig långt innan PLE är så låg.
Så vad är tröskeln att använda för när du borde vara orolig?
Tja, det är bara poängen. Jag kan inte ge dig en tröskel, eftersom den siffran kommer att variera för alla. Om du verkligen, verkligen vill ha ett nummer att använda, kom min kollega Jonathan Kehayias på en formel:
( Buffertpoolminne i GB / 4 ) x 300Även den siffran är något godtycklig och din körsträcka kommer att variera.
Jag gillar inte att rekommendera några siffror. Mitt råd är att du mäter din PLE när prestandan är på önskad nivå – det är tröskeln som du använder.
Så börjar du oroa dig så fort PLE faller under den tröskeln? Nej. Du börjar bli orolig när PLE sjunker under det tröskelvärdet och stannar under det tröskeln, eller om det faller hastigt och du inte vet varför.
Detta beror på att det finns vissa operationer som kommer att orsaka ett PLE-fall (t.ex. att köra DBCC CHECKDB eller ombyggnader av index kan göra det ibland) och är inte anledning till oro. Men om du ser ett stort PLE-fall och du inte vet vad som orsakar det, är det då du bör oroa dig.
Du kanske undrar hur DBCC CHECKDB kan orsaka ett PLE-fall när det missgynnar och försöker undvika att spola buffertpoolen med data den använder (se det här blogginlägget för en förklaring). Det beror på att frågekörningsminnet beviljar DBCC CHECKDB är felberäknad av frågeoptimeraren och kan orsaka en stor minskning av storleken på buffertpoolen (minnet för bidraget stjäls från buffertpoolen) och en åtföljande minskning av PLE.
Hur övervakar du PLE?
Det här är det knepiga. De flesta människor går direkt till Buffer Manager prestandaobjekt i PerfMon och övervaka Page life expectancy disken. Är detta rätt tillvägagångssätt? Troligtvis inte.
Jag skulle säga att en stor majoritet av servrarna där ute idag använder NUMA-arkitektur, och detta har en djupgående effekt på hur du övervakar PLE.
När NUMA är inblandat delas buffertpoolen upp i buffertnoder, med en buffertnod per NUMA-nod som SQL Server kan "se". Varje buffertnod spårar PLE separat och Buffer Manager:Page life expectancy räknaren är medelvärdet av buffertnodens PLE:er. Om du bara övervakar den övergripande buffertpoolen PLE, kan trycket på en av buffertnoderna maskeras av medelvärdet (jag diskuterar detta i ett blogginlägg här).
Så om din server använder NUMA måste du övervaka den individuella Buffer Node:Page life expectancy räknare (det kommer att finnas ett buffertnodsprestandaobjekt för varje NUMA-nod), annars övervakar du Buffer Manager:Page life expectancy räknare.
Ännu bättre är att använda ett övervakningsverktyg som SQL Sentry Performance Advisor, som visar denna räknare som en del av instrumentpanelen, med hänsyn till NUMA-noderna på servern, och låter dig enkelt konfigurera varningar.
Exempel på hur du använder Performance Advisor
Nedan är ett exempel på en skärmdump från Performance Advisor för ett system med en enda NUMA-nod:
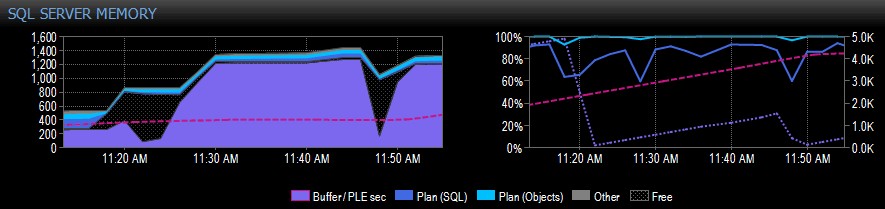
På höger sida av fångsten är den rosa streckade linjen PLE mellan 10.30 och cirka 11.20 – den klättrar stadigt upp till 5 000 eller så, ett riktigt hälsosamt antal. Strax före 11.20 är det ett stort fall, och sedan börjar det klättra igen till 11.45, där det faller igen.
Detta är vanligtvis vad du skulle se om buffertpoolen är full, med alla sidor som används, och sedan körs en fråga som gör att en enorm mängd olika data läses från disken, vilket förskjuter mycket av det som redan finns i minnet och orsakar en kraftig nedgång i PLE. Om du inte visste vad som orsakade något sådant här, skulle du vilja undersöka det, som jag beskriver längre ner.
Som ett andra exempel är skärmdumpen nedan från en av våra Remote DBA-klienter där servern har två NUMA-noder (du kan se att det finns två lila PLE-linjer), och där vi använder Performance Advisor flitigt:

På den här klientens server, varje morgon runt 05:00, startar ett jobb för indexunderhåll och konsistenskontroll som får PLE att sjunka i båda buffertnoderna. Detta är förväntat beteende så det finns inget behov av att undersöka det så länge PLE stiger upp igen under dagen.
Vad kan du göra åt att tappa PLE?
Om orsaken till PLE-fallet inte är känd kan du göra ett antal saker:
- Om problemet uppstår nu, undersök vilka frågor som orsakar läsningar genom att använda
sys.dm_os_waiting_tasksDMV för att se vilka trådar som väntar på att sidor ska läsas från disken (dvs de som väntar påPAGEIOLATCH_SH), och fixa sedan dessa frågor. - Om problemet inträffade tidigare, leta i sys.dm_exec_query_stats DMV efter frågor med stort antal fysiska läsningar, eller använd ett övervakningsverktyg som kan ge dig den informationen (t.ex. Top SQL-vyn i Performance Advisor), och fixa sedan dessa frågor.
- Korrelera PLE-minskningen med schemalagda agentjobb som utför databasunderhåll.
- Leta efter frågor med mycket stora minnesminnen för frågekörning med hjälp av
sys.dm_exec_query_memory_grantsDMV och fixa sedan dessa frågor.
Mitt tidigare inlägg här förklarar mer om #1 och #2, och ett skript för att undersöka väntan som inträffar på en server och länka till deras frågeplan finns här.
"Lösa de här frågorna" ligger utanför ramen för detta inlägg, så jag lämnar det till en annan gång eller som en övning för läsaren ☺
Sammanfattning
Gå inte i fällan att tro på någon rekommenderad PLE-tröskel som du kan läsa online. Det bästa sättet att reagera på PLE-ändringar är när PLE sjunker under vad som än är din komfortnivån är och förblir där – det är indikationen på ett prestandaproblem som du bör undersöka.
I nästa artikel i serien kommer jag att diskutera en annan vanlig orsak till knee-jerk prestandajustering. Tills dess, glad felsökning!