Vi gör alla misstag, och vi kan alla lära oss av andras misstag. I det här inlägget kommer vi att ta en titt på många onlineresurser för att undvika dålig databasdesign som kan leda till många problem och kosta både tid och pengar. Och i en kommande artikel berättar vi var du kan hitta tips och bästa praxis.
Databasdesignfel och misstag att undvika
Det finns många onlineresurser som hjälper databasdesigners att undvika vanliga fel och misstag. Uppenbarligen är den här artikeln inte en uttömmande lista över varje artikel där ute. Istället har vi granskat och kommenterat en mängd olika källor så att du kan hitta den som passar dig bäst.
Vår rekommendation
Om det bara finns en artikel bland dessa resurser som du ska läsa, bör det vara 'Hur får du databasdesign fruktansvärt fel' från Robert Sheldon
Låt oss börja med DATAVERSITY-bloggen som tillhandahåller en bred uppsättning ganska bra resurser:
Primära nyckel- och främmande nyckelfel att undvika
av Michael Blaha | DATAVERSITY blogg | 2 september 2015
Fler databasdesignfel – förvirring med många-till-många-relationer
av Michael Blaha | DATAVERSITY blogg | 30 september 2015
Övriga databasdesignfel
av Michael Blaha | DATAVERSITY blogg | 26 oktober 2015
Michael Blaha har bidragit med en trevlig uppsättning av tre artiklar. Varje artikel tar upp olika fallgropar med databasmodellering och fysisk design; ämnen inkluderar nycklar, relationer och allmänna fel. Dessutom pågår diskussioner med Michael angående några av punkterna. Om du letar efter fallgropar kring nycklar och relationer skulle det här vara ett bra ställe att börja.
Blaha säger att "omkring 20 % av databaserna bryter mot reglerna för primärnyckeln". Wow! Det betyder att cirka 20 % av databasutvecklarna inte skapade primärnycklar korrekt. Om denna statistik är sann visar den verkligen vikten av datamodelleringsverktyg som starkt "uppmuntrar" eller till och med kräver att modellerare definierar primärnycklar.
Mr. Blaha delar också heuristiken att "omkring 50 % av databaserna" har problem med främmande nyckel (enligt hans erfarenhet av äldre databaser som han har studerat). Han påminner oss om att undvika informell länkning mellan tabeller genom att bädda in värdet från en tabell i en annan istället för att använda en främmande nyckel.
Jag har sett detta problem många gånger. Jag medger att informell koppling kan krävas av funktionaliteten som ska implementeras, men oftare uppstår det på grund av enkel lathet. Vi kanske till exempel vill visa användar-id för någon som modifierat något, så vi lagrar användar-id direkt i tabellen. Men vad händer om den användaren ändrar sitt användar-ID? Då bryts denna informella länk. Detta beror ofta på dålig design och modellering.
Designa din databas:Topp 5 misstag att undvika
av Henrique Netzka | DATAVERSITY blogg | 2 november 2015
Jag blev lite besviken över den här artikeln, eftersom den hade ett par ganska specifika objekt (lagring av protokoll i en CLOB) och några mycket allmänna (tänk på lokalisering). Sammantaget är artikeln bra, men är dessa verkligen de fem bästa misstagen som ska undvikas? Enligt min åsikt finns det flera andra vanliga misstag som borde komma med på listan.
Men positivt, detta är en av få artiklar som nämner globalisering och lokalisering på något meningsfullt sätt. Jag arbetar i en mycket flerspråkig miljö och har sett flera hemska implementeringar av lokalisering, så jag var glad över att finna detta problem nämnt. Språkkolumner och tidszonskolumner kan verka självklara, men de förekommer mycket sällan i databasmodeller.
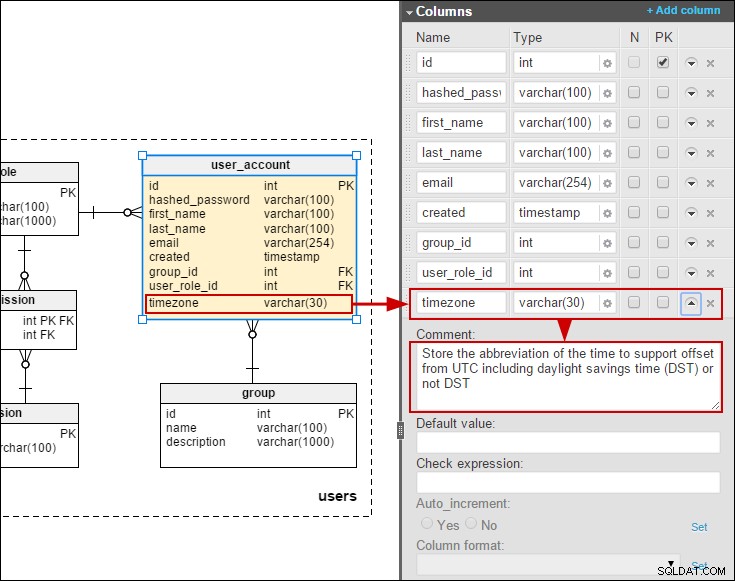
Med det sagt tyckte jag att det skulle vara intressant att skapa en modell som inkluderar översättningar som kan ändras av slutanvändare (i motsats till att använda resurspaket). För en tid sedan skrev jag om en modell för en onlineundersökningsdatabas. Här har jag modellerat en förenklad översättning av frågor och svarsval:
Om vi antar att vi måste tillåta slutanvändare att underhålla översättningarna, skulle den föredragna metoden vara att lägga till översättningstabeller för frågor och svar:
Jag har också lagt till en tidszon i user_account tabell så att vi kan lagra datum/tider i användarnas lokala tid:
7 vanliga databasdesignfel
av Grzegorz Kaczor | Vertabelo blogg | 17 juli 2015
Jag kommer att göra lite självreklam här. Vi strävar efter att regelbundet publicera intressanta och engagerande artiklar här.
Denna speciella artikel pekar ut flera viktiga områden av oro, som namngivning, indexering, volymöverväganden och revisionsspår. Artikeln går till och med in på frågor relaterade till specifika DBM-system, som Oracle-begränsningar för tabellnamn. Jag gillar verkligen fina tydliga exempel, även om de illustrerar hur designers gör misstag och fel.
Uppenbarligen är det inte möjligt att lista alla designfel, och de listade kanske inte är din vanligaste felen. När vi skriver om vanliga misstag är det de vi har gjort eller har hittat i andras arbete som vi bygger på. En fullständig lista över fel, rangordnad efter frekvens, skulle vara omöjlig för en enskild person att sammanställa. Ändå tror jag att den här artikeln ger flera användbara insikter om potentiella fallgropar. Det är en bra solid resurs överlag.
Medan Kaczor gör flera intressanta punkter i sin artikel, fann jag hans kommentarer om att "inte ta hänsyn till möjlig volym eller trafik" ganska intressanta. I synnerhet är rekommendationen att skilja ofta använda data från historiska data särskilt relevant. Detta är en lösning som vi använder ofta i våra meddelandeapplikationer; vi måste ha en sökbar historik över alla meddelanden, men de meddelanden som mest sannolikt kommer att nås är de som har postats under de senaste dagarna. Så att dela upp "aktiva" eller nyare data som är åtkomliga ofta (en mycket mindre mängd data) från långsiktiga historiska data (den stora mängden data) är generellt sett en mycket bra teknik.
Vanliga misstag i databasdesign
av Troy Blake | Senior DBA blogg | 11 juli 2015
Troy Blakes artikel är en annan bra resurs, även om jag kanske har bytt namn på den här artikeln till "Vanliga SQL Server-designmisstag".
Vi har till exempel kommentaren:"lagrade procedurer är din bästa vän när det gäller att använda SQL Server effektivt". Det är bra, men är detta ett vanligt allmänt misstag, eller är det mer specifikt för SQL Server? Jag skulle behöva välja att detta skulle vara lite SQL Server-specifikt, eftersom det finns nackdelar med att använda lagrade procedurer, som att sluta med leverantörsspecifika lagrade procedurer och därmed leverantörslåsning. Så jag är inte ett fan av att ta med "Not Using Stored Procedures" på den här listan.
Men på den positiva sidan tror jag att författaren identifierade några mycket vanliga misstag, som dålig planering, dålig systemdesign, begränsad dokumentation, svaga namnstandarder och brist på testning.
Så jag skulle klassificera detta som en mycket användbar referens för SQL Server-utövare och en användbar referens för andra.
Sju datamodelleringsmisstag
av Kurt Cagle | LinkedIn | 12 juni 2015
Jag gillade verkligen att läsa Mr. Cagles lista över databasmodelleringsmisstag. Dessa är från en databasarkitekts syn på saker och ting; han identifierar tydligt modelleringsmisstag på högre nivå som bör undvikas. Med denna större bildvy kan du avbryta en potentiell modellröra.
Några av de typer som nämns i artikeln kan hittas på andra ställen, men några av dessa är unika:att bli abstrakt för tidigt eller blanda konceptuella, logiska och fysiska modeller. Dessa nämns inte ofta av andra författare, förmodligen för att de fokuserar på datamodelleringsprocessen snarare än den större systemvyn.
Speciellt beskriver exemplet "Getting Too Abstract Too Early" en intressant tankeprocess för att skapa några exempel på "berättelser" och testa vilka relationer som är viktiga inom denna domän. Detta fokuserar tänkandet på relationerna mellan objekten som modelleras. Det resulterar i frågor som vilka är de viktiga relationerna på den här domänen ?
Baserat på denna förståelse skapar vi modellen kring relationer snarare än att börja på enskilda domänobjekt och bygga relationerna ovanpå dem. Även om många av oss kanske använder detta tillvägagångssätt, bland dessa resurser kommenterade ingen annan författare det. Jag tyckte att den här beskrivningen och exemplen var ganska intressanta.
Hur får man databasdesign fruktansvärt fel
av Robert Sheldon | Enkelt samtal | 6 mars 2015
Om det bara finns en artikel bland dessa resurser som du ska läsa, bör det vara den här från Robert Sheldon
Det jag verkligen gillar med den här artikeln är att det för vart och ett av de nämnda misstagen finns tips om hur man gör det rätt. De flesta av dessa fokuserar på att undvika felet snarare än att rätta till det, men jag tror ändå att de är väldigt användbara. Det finns väldigt lite teori här; mestadels raka svar om att undvika misstag vid datamodellering. Det finns några specifika SQL Server-punkter, men oftast används SQL Server för att ge exempel på hur man undviker fel eller sätter ut fel.
Omfattningen av artikeln är också ganska bred:den täcker att försumma att planera, inte bry sig om dokumentation, använda usla namnkonventioner, ha problem med normalisering (för mycket eller för lite), misslyckas med nycklar och begränsningar, inte korrekt indexera och utföra otillräcklig testning.
Jag gillade särskilt de praktiska råden angående dataintegritet – när man ska använda kontrollbegränsningar och när man ska definiera främmande nycklar. Dessutom beskriver Mr. Sheldon också situationen när team skjuter upp ansökan för att upprätthålla integritet. Han är rakt på sak när han säger att en databas kan nås på flera sätt och av många applikationer. Hans drar slutsatsen att "data bör skyddas där de finns:i databasen". Detta är så sant att det kan upprepas för utvecklingsteam och chefer för att förklara vikten av att implementera integritetskontroller i datamodellen.
Det här är min typ av artikel, och du kan säga att andra håller med baserat på de många kommentarerna som stöder den. Så, toppbetyg här; det är en mycket värdefull resurs.
Tio vanliga misstag i databasdesign
av Louis Davidson | Enkelt samtal | 26 februari 2007
Jag tyckte att den här artikeln var ganska bra, eftersom den täckte många vanliga designmisstag. Det fanns meningsfulla analogier, exempel, modeller och till och med några klassiska citat från William Shakespeare och J.R.R. Tolkien.
Ett par av misstagen förklarades mer detaljerat än andra, med långa exempel och SQL-utdrag som jag tyckte var lite krångliga. Men det är en smaksak.
Återigen, vi har några ämnen som är specifika för SQL Server. Till exempel är poängen med att inte använda lagrade procedurer för att komma åt data bra för SQL, men SP:er är inte alltid en bra idé när målet är stöd på flera DBMS:er. Dessutom varnas vi för att försöka koda generiska T-SQL-objekt. Eftersom jag sällan arbetar med SQL Server eller Sybase, fann jag inte detta tips relevant.
Listan är ganska lik Robert Sheldons, men om du i första hand arbetar på SQL Server, kommer du att hitta ytterligare några mängder information.
Fem enkla databasdesignfel du bör undvika
av Anith Sen Larson | Enkelt samtal | 16 oktober 2009
Den här artikeln ger några meningsfulla exempel för vart och ett av de enkla designfelen som den täcker. Å andra sidan är det snarare fokuserat på liknande typer av fel:vanliga uppslagstabeller, entitetsattribut-värdetabeller och attributdelning.
Observationerna är bra, och artikeln har till och med referenser, som tenderar att vara sällsynta. Ändå skulle jag vilja se mer allmänna databasdesignfel. Dessa fel verkade ganska specifika, men, som jag redan har skrivit, är de misstag vi skriver om i allmänhet de som vi har personlig erfarenhet av.
En sak som jag gillade var en specifik tumregel för att bestämma när en kontrollrestriktion ska användas kontra en separat tabell med en främmande nyckelrestriktion. Flera författare ger liknande rekommendationer, men Larson delar upp dem i "måste", "överväga" och "starkt argument" - med erkännandet att "design är en blandning av konst och vetenskap och därför innebär kompromisser". Jag tycker att detta är mycket sant.
Topp tio vanligaste misstag i fysisk databasdesign
av Craig Mullins | Data och teknik idag | 5 augusti 2013
Som namnet antyder, är "Top Ten Most Common Physical Database Design Mistakes" något mer orienterad mot fysisk design snarare än logisk och konceptuell design. Inget av misstagen som författaren Craig Mullins nämner sticker ut eller är unikt, så jag skulle rekommendera den här informationen till folk som arbetar på den fysiska DBA-sidan.
Dessutom är beskrivningarna lite korta, så det är ibland svårt att se varför ett visst misstag kommer att orsaka problem. Det är inget fel med korta beskrivningar, men de ger dig inte så mycket att tänka på. Och inga exempel presenteras.
Det finns en intressant punkt som har tagits upp angående misslyckandet med att dela data. Denna punkt nämns ibland i andra artiklar, men inte som ett designfel. Men jag ser det här problemet ganska ofta med databaser som "återskapas" baserat på mycket liknande krav, men av ett nytt team eller för en ny produkt
.Det händer ofta att produktteamet senare inser att de skulle ha velat använda data som redan fanns i "fadern" till deras nuvarande databas. I själva verket borde de dock ha förbättrat föräldern snarare än att skapa en ny avkomma. Applikationer är avsedda att dela data; bra design kan göra att en databas kan återanvändas oftare.
Gör du dessa 5 databasdesignmisstag?
av Thomas Larock | Thomas Larocks blogg | 2 januari 2012
Du kanske hittar några intressanta punkter när du svarar på Thomas Larocks fråga:Gör du dessa 5 databasdesignmisstag?
Den här artikeln är något tungt viktad till nycklar (främmande nycklar, surrogatnycklar och genererade nycklar). Ändå har det en viktig poäng:man bör inte anta att DBMS-funktionerna är desamma i alla system. Jag tycker att detta är en mycket bra poäng. Det är också en som inte finns i de flesta andra artiklar, kanske för att många författare fokuserar på och arbetar övervägande med ett enda DBMS.
Designa en databas:7 saker du inte vill göra
av Thomas Larock | Thomas Larocks blogg | 16 januari 2013
Mr. Larock återvann ett par av sina "5 databasdesignmisstag" när han skrev "7 Things You Don't Want To Do", men det finns andra bra poäng här.
Intressant nog finns några av de poänger som Mr Larock gör inte i många andra källor. Du får ett par ganska unika observationer, som "att inte ha några prestationsförväntningar". Detta är ett allvarligt misstag och ett som, baserat på min erfarenhet, händer ganska ofta. Även när man utvecklar applikationskoden är det ofta efter att datamodellen, databasen och själva applikationen har skapats som folk börjar tänka på de icke-funktionella kraven (när icke-funktionella test måste skapas) och börjar definiera prestandaförväntningar .
Omvänt finns det några punkter som jag inte skulle ta med i min egen topp tio-lista, som att "gå stort, för säkerhets skull". Jag ser poängen, men det är inte så högt på min lista när jag skapar en datamodell. Det finns ingen specificitet för ett visst DBM-system, så det är en bonus.
Sammanfattningsvis kan många av dessa punkter vara inkapslade under punkten:"förstår inte kraven", som verkligen finns på min topp 10-fellista.
Hur man undviker 8 vanliga misstag i databasutveckling
av Base36 | 6 december 2012
Jag var ganska intresserad av att läsa den här artikeln. Dock blev jag lite besviken. Det finns inte mycket diskussion om undvikande, och poängen med artikeln verkar verkligen vara "detta är vanliga databasmisstag" och "varför de är misstag"; beskrivningar av hur man undviker misstaget är mindre framträdande.
Dessutom är några av artikelns topp 8-fel faktiskt omtvistade. Missbruk av primärnyckeln är ett exempel. Base36 säger att de måste genereras av systemet och inte baseras på applikationsdata i raden. Även om jag håller med om detta till viss del, är jag inte övertygad om att alla PK ska alltid genereras; det är lite för kategoriskt.
Å andra sidan är misstaget med "Hårda raderingar" intressant och nämns inte ofta någon annanstans. Mjuka borttagningar orsakar andra problem, men det är sant att helt enkelt markera en rad som inaktiv har sina fördelar när du försöker ta reda på var den informationen tog vägen som fanns i systemet igår. Att söka igenom transaktionsloggar är inte min idé om ett trevligt sätt att spendera en dag.
Sju dödssynder av databasdesign
av Jason Tiret | Enterprise Systems Journal | 16 februari 2010
Jag var ganska hoppfull när jag började läsa Jason Tirets artikel, "Seven Deadly Sins of Database Design". Så jag var glad över att finna att det inte bara återvinner misstag som finns i många andra artiklar. Tvärtom erbjöd det en "synd" som jag inte hade hittat i andra listor:att försöka utföra all databasdesign "up front" och inte uppdatera modellen efter att databasen är i produktion, när ändringar görs i databasen. (Eller, som Jason uttrycker det, "att inte behandla datamodellen som en levande, andande organism").
Jag har sett detta misstag många gånger. De flesta inser sitt fel först när de måste göra uppdateringar av en modell som inte längre matchar den faktiska databasen. Naturligtvis är resultatet en värdelös modell. Som artikeln säger, "förändringarna måste hitta tillbaka till modellen."
Å andra sidan är majoriteten av Jasons listobjekt ganska välkända. Beskrivningarna är bra, men det finns inte särskilt många exempel. Fler exempel och detaljer skulle vara användbara.
De vanligaste misstagen i databasdesign
av Brian Prince | eWeek.com | 19 mars 2008

Artikeln "De vanligaste misstagen i databasdesign" är faktiskt en serie bilder från en presentation. Det finns några intressanta tankar, men några av de unika föremålen är kanske lite esoteriska. Jag tänker på saker som "Lär känna RAID" och involvering av intressenter.
I allmänhet skulle jag inte lägga detta på din läslista om du inte är fokuserad på allmänna frågor (planering, namngivning, normalisering, index) och fysiska detaljer.
10 vanliga designfel
av davidm | SQL Server-bloggar – SQLTeam.com | 12 september 2005
Några av punkterna i "Tio vanliga designmisstag" är intressanta och relativt nya. Vissa av dessa misstag är dock ganska kontroversiella, som att "använda NULLs" och avnormalisera.
Jag håller med om att det är ett misstag att skapa alla kolumner som nullbara, men att definiera en kolumn som nullbar kan krävas för en viss affärsfunktion. Kan det därför betraktas som ett generiskt misstag? Jag tror inte.
En annan punkt som jag har problem med är avnormalisering. Detta är inte alltid ett designfel. Till exempel kan denormalisering krävas av prestandaskäl.
Denna artikel saknar också till stor del detaljer och exempel. Samtalen mellan DBA och programmerare eller chef är roliga, men jag hade föredragit mer konkreta exempel och detaljerade motiveringar för dessa vanliga misstag.
OTLT och EAV:de två stora designmisstagen alla nybörjare gör
av Tony Andrews | Tony Andrews om Oracle och databaser | 21 oktober 2004
Mr. Andrews artikel påminner oss om "One True Lookup Table" (OTLT) och Entity-Attribute-Value (EAV) misstag som nämns i andra artiklar. En bra poäng med denna presentation är att den fokuserar på dessa två misstag, så beskrivningar och exempel är exakta. Dessutom ges en möjlig förklaring till varför vissa designers implementerar OTLT och EAV.
För att påminna dig, ser OTLT-tabellen vanligtvis ut ungefär så här, med poster från flera domäner in i samma tabell:
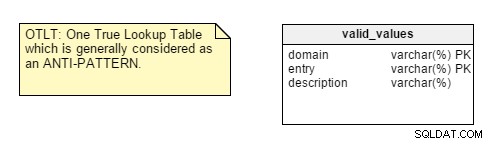
Som vanligt diskuteras det om OTLT är en fungerande lösning och ett bra designmönster. Jag måste säga att jag ställer mig på anti-OTLT-gruppen; dessa tabeller introducerar många problem. Vi kan använda analogin med att använda en enda uppräkning för att representera alla möjliga värden på alla möjliga konstanter. Jag har aldrig sett det hittills.
Vanliga databasmisstag
av John Paul Ashenfelter | Dr. Dobbs | 1 januari 2002
Mr. Ashenfelters artikel listar en hel del 15 vanliga databasmisstag. Det finns till och med ett par misstag som inte nämns ofta i andra artiklar. Tyvärr är beskrivningarna relativt korta och det finns inga exempel. Den här artikelns förtjänst är att listan täcker mycket mark och kan användas som en "checklista" över misstag att undvika. Även om jag kanske inte klassificerar dessa som de viktigaste databasmisstagen, är de säkert bland de vanligaste.
Positivt är att detta är en av få artiklar som nämner behovet av att hantera internationalisering av format för data som datum, valuta och adress. Ett exempel vore bra här. Det kan vara så enkelt som "var säker på att staten är en nullbar kolumn; i många länder finns ingen stat kopplad till en adress”.
Tidigare i den här artikeln nämnde jag andra problem och några metoder för att förbereda för globaliseringen av din databas, som tidszoner och översättningar (lokalisering). Det faktum att ingen annan artikel nämner oron för valuta- och datumformat är oroande. Är våra databaser förberedda för den globala användningen av våra applikationer?
Hedrande omnämnanden
Självklart finns det andra artiklar som beskriver vanliga misstag och fel i databasdesign, men vi ville ge dig en bred genomgång av olika resurser. Du kan hitta ytterligare information i artiklar som:
10 vanliga misstag i databasdesign | MIS klassblogg | 29 januari 2012
10 vanliga misstag i databasdesign | IDG.se | 24 juni 2010
Onlineresurser:Var ska man börja? Vart ska man gå?
Som tidigare nämnts är den här listan definitivt inte avsedd att vara en uttömmande granskning av varje onlineartikel som beskriver databasdesignfel och fel. Snarare har vi identifierat flera källor som är särskilt användbara eller har ett specifikt fokus som du kan ha nytta av.
Rekommendera gärna ytterligare artiklar.