Funktionerna RANK, DENSE_RANK och ROW_NUMBER används för att hämta ett ökande heltalsvärde. De börjar med ett värde baserat på villkoret i ORDER BY-satsen. Alla dessa funktioner kräver ORDER BY-satsen för att fungera korrekt. Vid partitionerade data återställs heltalsräknaren till 1 för varje partition.
I den här artikeln kommer vi att studera funktionerna RANK, DENSE_RANK och ROW_NUMBER i detalj, men innan dess, låt oss skapa dummydata som dessa funktioner kan användas på om inte din databas är helt säkerhetskopierad.
Förbereder dummydata
Kör följande skript för att skapa en databas som heter ShowRoom och som innehåller en tabell som heter Bilar (som innehåller 15 slumpmässiga poster av bilar):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
RANK-funktion
RANK-funktionen används för att hämta rangordnade rader baserat på villkoret för ORDER BY-satsen. Om du till exempel vill hitta namnet på bilen med tredje högsta effekt kan du använda RANK-funktionen.
Låt oss se RANK-funktionen i aktion:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Skriptet ovan hittar och rangordnar alla poster i tabellen Bilar och ordnar dem i ordning efter fallande kraft. Utdatan ser ut så här:
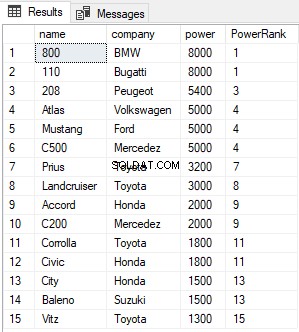
PowerRank-kolumnen i ovanstående tabell innehåller RANK för bilarna ordnade efter fallande ordning efter deras effekt. En intressant sak med RANK-funktionen är att om det finns en koppling mellan N tidigare poster för värdet i ORDER BY-kolumnen, hoppar RANK-funktionerna över nästa N-1-positioner innan räknaren ökar. Till exempel, i resultatet ovan, finns det en oavgjordhet för värdena i potenskolumnen mellan 1:a och 2:a raden, därför hoppar RANK-funktionen över nästa (2-1 =1) en post och hoppar direkt till 3:e raden.
RANK-funktionen kan användas i kombination med PARTITION BY-satsen. I så fall kommer rangordningen att återställas för varje ny partition. Ta en titt på följande skript:
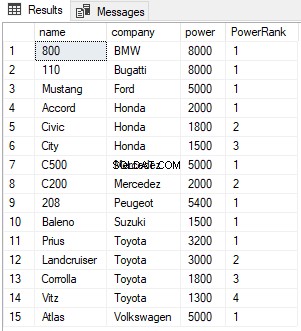
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
I skriptet ovan delar vi upp resultaten efter företagskolumn. Nu för varje företag kommer RANK att återställas till 1 som visas nedan:
DENSE_RANK-funktion
Funktionen DENSE_RANK liknar funktionen RANK men funktionen DENSE_RANK hoppar inte över några rankningar om det är oavgjort mellan rankningarna i de föregående posterna. Ta en titt på följande manus.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
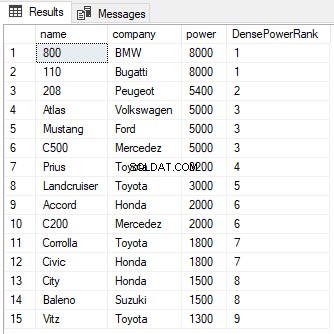
Du kan se från utgången att trots att det är oavgjort mellan de två första radernas rankning, så hoppas inte nästa rank över och har tilldelats värdet 2 istället för 3. Precis som med RANK-funktionen kan PARTITION BY-satsen även användas med DENSE_RANK-funktionen som visas nedan:
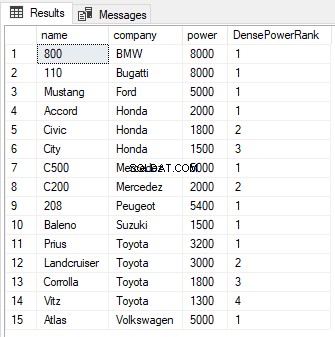
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
ROW_NUMBER-funktion
Till skillnad från funktionerna RANK och DENSE_RANK returnerar funktionen ROW_NUMBER helt enkelt radnumret för de sorterade posterna som börjar med 1. Till exempel, om funktionerna RANK och DENSE_RANK för de två första posterna i ORDER BY kolumnen är lika, tilldelas båda 1 som deras RANK och DENSE_RANK. Funktionen ROW_NUMBER kommer dock att tilldela värdena 1 och 2 till dessa rader utan att ta det faktum att de är lika med i beräkningen. Kör följande skript för att se ROW_NUMBER-funktionen i funktion.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
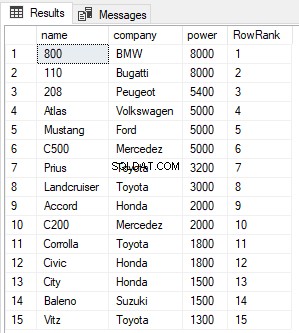
Från utgången kan du se att ROW_NUMBER-funktionen helt enkelt tilldelar ett nytt radnummer till varje post, oavsett dess värde.
PARTITION BY-satsen kan också användas med ROW_NUMBER-funktionen enligt nedan:
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
Utdatan ser ut så här:
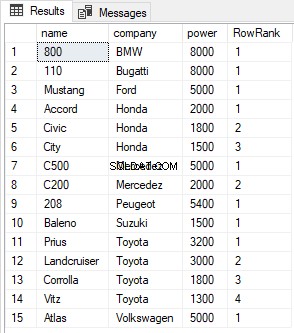
Likheter mellan funktionerna RANK, DENSE_RANK och ROW_NUMBER
Funktionerna RANK, DENSE_RANK och ROW_NUMBER har följande likheter:
1- Alla kräver en ordning efter sats.
2- Alla returnerar ett ökande heltal med basvärdet 1.
3- När de kombineras med en PARTITION BY-sats, återställer alla dessa funktioner det returnerade heltalsvärdet till 1 som vi har sett.
4- Om det inte finns några dubblerade värden i kolumnen som används av ORDER BY-satsen, funktioner returnerar samma utdata.
För att illustrera den sista punkten, låt oss skapa en ny tabell Car1 i ShowRoom-databasen utan dubbletter av värden i potenskolumnen. Kör följande skript:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
Utdatan ser ut så här:
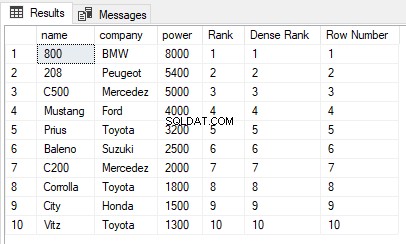
Du kan se att det inte finns några dubbletter av värden i potenskolumnen som används i ORDER BY-satsen, därför är utdata från funktionerna RANK, DENSE_RANK och ROW_NUMBER desamma.
Skillnad mellan RANK, DENSE_RANK och ROW_NUMBER funktioner
Den enda skillnaden mellan funktionen RANK, DENSE_RANK och ROW_NUMBER är när det finns dubbla värden i kolumnen som används i ORDER BY-klausulen.
Om du går tillbaka till tabellen Bilar i ShowRoom-databasen kan du se att den innehåller massor av dubbletter av värden. Låt oss försöka hitta RANK, DENSE_RANK och ROW_NUMBER i Cars1-tabellen sorterade efter makt. Kör följande skript:
SELECT name,company, power,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
Utdatan ser ut så här:
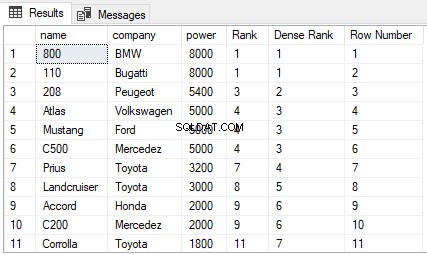
Från utgången kan du se att RANK-funktionen hoppar över nästa N-1 rankningar om det är oavgjort mellan N tidigare rankningar. Å andra sidan, DENSE_RANK-funktionen hoppar inte över rangordnar om det är oavgjort mellan rangerna. Slutligen har funktionen ROW_NUMBER inget problem med rangordning. Den returnerar helt enkelt radnumret för de sorterade posterna. Även om det finns dubbletter av poster i kolumnen som används i ORDER BY-satsen, kommer funktionen ROW_NUMBER inte att returnera dubbla värden. Istället kommer den att fortsätta att öka oavsett dubblettvärdena.
Användbara länkar:
För att lära dig mer om funktionerna ROW_NUMBER(), RANK() och DENSE_RANK() läs den fantastiska artikeln av Ahmad Yaseen:
Metoder för att rangordna rader i SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() och NTILE()