I del 1 av den här serien använde du Flask och Connexion för att skapa ett REST API som tillhandahåller CRUD-operationer till en enkel struktur i minnet som kallas PEOPLE . Det fungerade för att visa hur Connexion-modulen hjälper dig att bygga ett snyggt REST API tillsammans med interaktiv dokumentation.
Som några noterade i kommentarerna till del 1, PEOPLE strukturen återinitieras varje gång programmet startas om. I den här artikeln får du lära dig hur du lagrar PEOPLE struktur, och de åtgärder som API tillhandahåller, till en databas som använder SQLAlchemy och Marshmallow.
SQLAlchemy tillhandahåller en Object Relational Model (ORM), som lagrar Python-objekt till en databasrepresentation av objektets data. Det kan hjälpa dig att fortsätta tänka på ett pytoniskt sätt och inte bry dig om hur objektdata kommer att representeras i en databas.
Marshmallow tillhandahåller funktionalitet för att serialisera och deserialisera Python-objekt när de flödar ut ur och in i vårt JSON-baserade REST API. Marshmallow konverterar Python-klassinstanser till objekt som kan konverteras till JSON.
Du kan hitta Python-koden för den här artikeln här.
Gratis bonus: Klicka här för att ladda ner en kopia av guiden "REST API Exempel" och få en praktisk introduktion till Python + REST API-principerna med praktiska exempel.
Vem den här artikeln är till för
Om du gillade del 1 av den här serien, utökar den här artikeln ditt verktygsbälte ytterligare. Du kommer att använda SQLAlchemy för att komma åt en databas på ett mer pytoniskt sätt än rak SQL. Du kommer också att använda Marshmallow för att serialisera och deserialisera data som hanteras av REST API. För att göra detta kommer du att använda dig av grundläggande objektorienterade programmeringsfunktioner som finns tillgängliga i Python.
Du kommer också att använda SQLAlchemy för att skapa en databas samt interagera med den. Detta är nödvändigt för att få igång REST API med PEOPLE data som används i del 1.
Webbapplikationen som presenteras i del 1 kommer att få sina HTML- och JavaScript-filer modifierade på mindre sätt för att stödja ändringarna också. Du kan granska den slutliga versionen av koden från del 1 här.
Ytterligare beroenden
Innan du börjar bygga den här nya funktionen måste du uppdatera den virtualenv du skapade för att kunna köra del 1-koden, eller skapa en ny för det här projektet. Det enklaste sättet att göra det efter att du har aktiverat din virtualenv är att köra detta kommando:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Detta lägger till mer funktionalitet till din virtuella miljö:
-
Flask-SQLAlchemylägger till SQLAlchemy, tillsammans med några kopplingar till Flask, vilket ger program åtkomst till databaser. -
flask-marshmallowlägger till Flask-delarna av Marshmallow, som låter program konvertera Python-objekt till och från serialiserbara strukturer. -
marshmallow-sqlalchemylägger till några Marshmallow-krokar i SQLAlchemy för att tillåta program att serialisera och deserialisera Python-objekt som genereras av SQLAlchemy. -
marshmallowlägger till huvuddelen av Marshmallow-funktionaliteten.
Persondata
Som nämnts ovan, PEOPLE datastrukturen i föregående artikel är en Python-ordbok i minnet. I den ordboken använde du personens efternamn som uppslagsnyckel. Datastrukturen såg ut så här i koden:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Ändringarna du gör i programmet kommer att flytta all data till en databastabell. Detta innebär att data kommer att sparas på din disk och kommer att finnas mellan körningar av server.py program.
Eftersom efternamnet var ordboksnyckeln begränsade koden att ändra en persons efternamn:endast förnamnet kunde ändras. Om du flyttar till en databas kan du dessutom ändra efternamnet eftersom det inte längre kommer att användas som söknyckel för en person.
Begreppsmässigt kan en databastabell ses som en tvådimensionell array där raderna är poster och kolumnerna är fält i dessa poster.
Databastabeller har vanligtvis ett automatiskt ökande heltalsvärde som uppslagsnyckel till rader. Detta kallas primärnyckeln. Varje post i tabellen kommer att ha en primärnyckel vars värde är unikt över hela tabellen. Om du har en primärnyckel oberoende av data som lagras i tabellen kan du ändra alla andra fält i raden.
Obs!
Den auto-inkrementerande primärnyckeln innebär att databasen tar hand om:
- Öka det största befintliga primära nyckelfältet varje gång en ny post infogas i tabellen
- Använda det värdet som primärnyckel för nyinfogad data
Detta garanterar en unik primärnyckel när tabellen växer.
Du kommer att följa en databaskonvention att namnge tabellen som singular, så tabellen kommer att kallas person . Översätter våra PEOPLE struktur ovan till en databastabell med namnet person ger dig detta:
| person_id | lname | fname | tidsstämpel |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Påsk | Kanin | 2018-08-08 21:16:01.886834 |
Varje kolumn i tabellen har ett fältnamn enligt följande:
person_id: primärnyckelfält för varje personlname: efternamn på personenfname: personens förnamntimestamp: tidsstämpel kopplad till infogning/uppdateringsåtgärder
Databasinteraktion
Du kommer att använda SQLite som databasmotor för att lagra PEOPLE data. SQLite är den mest spridda databasen i världen, och den kommer med Python gratis. Den är snabb, utför allt sitt arbete med hjälp av filer och lämpar sig för många projekt. Det är ett komplett RDBMS (Relational Database Management System) som inkluderar SQL, språket i många databassystem.
För tillfället, föreställ dig person Tabellen finns redan i en SQLite-databas. Om du har haft någon erfarenhet av RDBMS är du förmodligen medveten om SQL, det strukturerade frågespråk som de flesta RDBMS använder för att interagera med databasen.
Till skillnad från programmeringsspråk som Python, definierar inte SQL hur för att få data:den beskriver vad data önskas, vilket lämnar hur upp till databasmotorn.
En SQL-fråga som hämtar all data i vår person Tabell, sorterad efter efternamn, skulle se ut så här:
SELECT * FROM person ORDER BY 'lname';
Den här frågan talar om för databasmotorn att hämta alla fält från persontabellen och sortera dem i stigande standardordning med lname fält.
Om du skulle köra den här frågan mot en SQLite-databas som innehåller person tabell, skulle resultaten vara en uppsättning poster som innehåller alla rader i tabellen, där varje rad innehåller data från alla fält som utgör en rad. Nedan är ett exempel som använder kommandoradsverktyget SQLite som kör ovanstående fråga mot person databastabell:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Utdata ovan är en lista över alla rader i person databastabell med rörtecken ('|') som separerar fälten i raden, vilket görs för visningsändamål av SQLite.
Python är helt kapabel att samverka med många databasmotorer och köra SQL-frågan ovan. Resultaten skulle med största sannolikhet bli en lista med tupler. Den yttre listan innehåller alla poster i person tabell. Varje enskild inre tupel skulle innehålla all data som representerar varje fält som definierats för en tabellrad.
Att få data på det här sättet är inte särskilt pytoniskt. Listan över poster är okej, men varje enskild post är bara en tuppel av data. Det är upp till programmet att känna till indexet för varje fält för att kunna hämta ett visst fält. Följande Python-kod använder SQLite för att demonstrera hur man kör ovanstående fråga och visar data:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Programmet ovan gör följande:
-
Rad 1 importerar
sqlite3modul. -
Rad 3 skapar en anslutning till databasfilen.
-
Rad 4 skapar en markör från anslutningen.
-
Rad 5 använder markören för att köra en
SQLfråga uttryckt som en sträng. -
Rad 6 får alla poster som returneras av
SQLfråga och tilldelar dem tillpeoplevariabel. -
Rad 7 och 8 iterera över
peoplelista variabel och skriv ut för- och efternamn på varje person.
people variabel från rad 6 ovan skulle se ut så här i Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Utdata från programmet ovan ser ut så här:
Kent Brockman
Bunny Easter
Doug Farrell
I programmet ovan måste du veta att en persons förnamn finns i index 2 , och en persons efternamn finns i index 1 . Ännu värre, den interna strukturen för person måste också vara känd när du skickar iterationsvariabeln person som en parameter till en funktion eller metod.
Det skulle vara mycket bättre om det du fick tillbaka för person var ett Python-objekt, där vart och ett av fälten är ett attribut för objektet. Detta är en av sakerna SQLAlchemy gör.
Lilla Bobby-bord
I programmet ovan är SQL-satsen en enkel sträng som skickas direkt till databasen för att köras. I det här fallet är det inte ett problem eftersom SQL är en bokstavlig sträng helt under kontroll av programmet. Användningsfallet för ditt REST API kommer dock att ta användarinput från webbapplikationen och använda det för att skapa SQL-frågor. Detta kan öppna din applikation för attack.
Du kommer ihåg från del 1 att REST API för att få en enda person från PEOPLE data såg ut så här:
GET /api/people/{lname}
Det betyder att ditt API förväntar sig en variabel, lname , i URL-slutpunktssökvägen, som den använder för att hitta en enda person . Att modifiera Python SQLite-koden från ovan för att göra detta skulle se ut ungefär så här:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Ovanstående kodavsnitt gör följande:
-
Rad 1 ställer in
lnamevariabel till'Farrell'. Detta kommer från REST API URL-slutpunktssökvägen. -
Rad 2 använder Python-strängformatering för att skapa en SQL-sträng och exekvera den.
För att göra saker enkelt ställer ovanstående kod in lname variabel till en konstant, men egentligen skulle den komma från API URL-slutpunktssökvägen och kan vara vad som helst som tillhandahålls av användaren. SQL som genereras av strängformateringen ser ut så här:
SELECT * FROM person WHERE lname = 'Farrell'
När denna SQL körs av databasen söker den efter person tabell för en post där efternamnet är lika med 'Farrell' . Detta är vad som är avsett, men alla program som accepterar användarinmatning är också öppna för illvilliga användare. I programmet ovan, där lname variabeln ställs in av användarens indata, detta öppnar ditt program för vad som kallas en SQL-injektionsattack. Det här är vad som kärleksfullt kallas Little Bobby Tables:
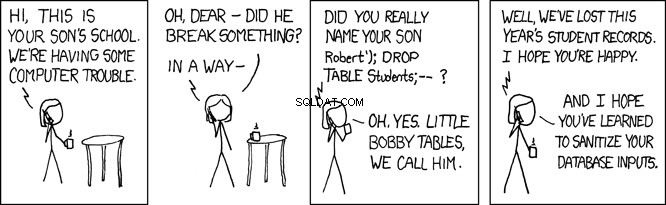
Föreställ dig till exempel en illvillig användare som heter ditt REST API på det här sättet:
GET /api/people/Farrell');DROP TABLE person;
REST API-begäran ovan anger lname variabel till 'Farrell');DROP TABLE person;' , som i koden ovan skulle generera denna SQL-sats:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Ovanstående SQL-sats är giltig, och när den körs av databasen hittar den en post där lname matchar 'Farrell' . Sedan hittar den SQL-satsens avgränsare ; och kommer att gå direkt och släppa hela bordet. Detta skulle i huvudsak förstöra din ansökan.
Du kan skydda ditt program genom att rensa all data du får från användare av din applikation. Att sanera data i det här sammanhanget innebär att ditt program undersöker den data som användaren tillhandahåller och att den inte innehåller något som är farligt för programmet. Detta kan vara svårt att göra rätt och skulle behöva göras överallt där användardata interagerar med databasen.
Det finns ett annat sätt som är mycket enklare:använd SQLAlchemy. Det kommer att rensa användardata åt dig innan du skapar SQL-satser. Det är en annan stor fördel och anledning att använda SQLAlchemy när man arbetar med databaser.
Modellera data med SQLAlchemy
SQLAlchemy är ett stort projekt och ger mycket funktionalitet för att arbeta med databaser med Python. En av sakerna som den tillhandahåller är en ORM, eller Object Relational Mapper, och det här är vad du ska använda för att skapa och arbeta med person databastabell. Detta låter dig mappa en rad med fält från databastabellen till ett Python-objekt.
Objektorienterad programmering låter dig koppla data tillsammans med beteende, funktionerna som verkar på dessa data. Genom att skapa SQLAlchemy-klasser kan du koppla fälten från databastabellsraderna till beteende, så att du kan interagera med data. Här är SQLAlchemy-klassdefinitionen för data i person databastabell:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Klassen Person ärver från db.Model , som du kommer till när du börjar bygga programkoden. För närvarande betyder det att du ärver från en basklass som heter Model , tillhandahåller attribut och funktionalitet som är gemensamma för alla klasser som härrör från den.
Resten av definitionerna är klassnivåattribut som definieras enligt följande:
-
__tablename__ = 'person'kopplar klassdefinitionen tillpersondatabastabell. -
person_id = db.Column(db.Integer, primary_key=True)skapar en databaskolumn som innehåller ett heltal som fungerar som den primära nyckeln för tabellen. Detta talar också om för databasen attperson_idkommer att vara ett automatiskt ökande heltalsvärde. -
lname = db.Column(db.String)skapar efternamnsfältet, en databaskolumn som innehåller ett strängvärde. -
fname = db.Column(db.String)skapar förnamnsfältet, en databaskolumn som innehåller ett strängvärde. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)skapar ett tidsstämpelfält, en databaskolumn som innehåller ett datum/tidsvärde.default=datetime.utcnowparametern förinställer tidsstämpelvärdet till den nuvarandeutcnowvärde när en post skapas.onupdate=datetime.utcnowparametern uppdaterar tidsstämpeln med den aktuellautcnowvärde när posten uppdateras.
Obs! UTC-tidsstämplar
Du kanske undrar varför tidsstämpeln i ovanstående klass är standard till och uppdateras av datetime.utcnow() metod, som returnerar en UTC eller Coordinated Universal Time. Det här är ett sätt att standardisera källan för din tidsstämpel.
Källan, eller nolltid, är en linje som går norr och söder från jordens nord- till sydpol genom Storbritannien. Detta är nolltidszonen från vilken alla andra tidszoner är förskjutna. Genom att använda detta som nolltidskälla förskjuts dina tidsstämplar från denna standardreferenspunkt.
Om din applikation nås från olika tidszoner har du ett sätt att utföra datum-/tidsberäkningar. Allt du behöver är en UTC-tidsstämpel och destinationens tidszon.
Om du skulle använda lokala tidszoner som din tidsstämpelkälla, kunde du inte utföra datum-/tidsberäkningar utan information om de lokala tidszonerna som är förskjutna från nolltid. Utan källinformationen för tidsstämpeln skulle du inte kunna göra några datum/tid-jämförelser eller matematik alls.
Att arbeta med tidsstämplar baserade på UTC är en bra standard att följa. Här är en verktygslåda att arbeta med och bättre förstå dem.
Vart är du på väg med denna Person klass definition? Slutmålet är att kunna köra en fråga med SQLAlchemy och få tillbaka en lista över instanser av Person klass. Som ett exempel, låt oss titta på den tidigare SQL-satsen:
SELECT * FROM people ORDER BY lname;
Visa samma lilla exempelprogram från ovan, men nu med SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Om du ignorerar rad 1 för tillfället, är det du vill ha all person poster sorterade i stigande ordning efter lname fält. Vad du får tillbaka från SQLAlchemy-satserna Person.query.order_by(Person.lname).all() är en lista över Person objekt för alla poster i person databastabell i den ordningen. I ovanstående program, people variabeln innehåller listan över Person objekt.
Programmet itererar över people variabel, med varje person i sin tur och skriva ut för- och efternamn på personen från databasen. Observera att programmet inte behöver använda index för att få fname eller lname värden:den använder attributen som definieras på Person objekt.
Genom att använda SQLAlchemy kan du tänka i termer av objekt med beteende snarare än rå SQL . Detta blir ännu mer fördelaktigt när dina databastabeller blir större och interaktionerna mer komplexa.
Serialisering/avserialisering av modellerade data
Att arbeta med SQLAlchemy-modellerad data i dina program är mycket bekvämt. Det är särskilt praktiskt i program som manipulerar data, kanske gör beräkningar eller använder den för att skapa presentationer på skärmen. Din applikation är ett REST API som i huvudsak tillhandahåller CRUD-operationer på data, och som sådan utför den inte mycket datamanipulation.
REST API fungerar med JSON-data, och här kan du stöta på ett problem med SQLAlchemy-modellen. Eftersom data som returneras av SQLAlchemy är Python-klassinstanser, kan Connexion inte serialisera dessa klassinstanser till JSON-formaterade data. Kom ihåg från del 1 att Connexion är verktyget du använde för att designa och konfigurera REST API med en YAML-fil och koppla Python-metoder till den.
I detta sammanhang innebär serialisering att konvertera Python-objekt, som kan innehålla andra Python-objekt och komplexa datatyper, till enklare datastrukturer som kan tolkas till JSON-datatyper, som listas här:
string: en strängtypnumber: tal som stöds av Python (heltal, flytande, långa)object: ett JSON-objekt, vilket ungefär motsvarar en Python-ordbokarray: ungefär lika med en Python-listaboolean: representeras i JSON somtrueellerfalse, men i Python somTrueellerFalsenull: i huvudsak enNonei Python
Som ett exempel, din Person klass innehåller en tidsstämpel, som är en Python DateTime . Det finns ingen definition av datum/tid i JSON, så tidsstämpeln måste konverteras till en sträng för att existera i en JSON-struktur.
Din Person klass är tillräckligt enkelt så att få dataattribut från den och skapa en ordbok manuellt för att återvända från våra REST URL-slutpunkter skulle inte vara särskilt svårt. I en mer komplex applikation med många större SQLAlchemy-modeller skulle detta inte vara fallet. En bättre lösning är att använda en modul som heter Marshmallow för att göra jobbet åt dig.
Marshmallow hjälper dig att skapa ett PersonSchema klass, som är som SQLAlchemy Person klass vi skapade. Här, istället för att mappa databastabeller och fältnamn till klassen och dess attribut, används PersonSchema klass definierar hur attributen för en klass kommer att konverteras till JSON-vänliga format. Här är Marshmallow-klassdefinitionen för data i vår person tabell:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Klassen PersonSchema ärver från ma.ModelSchema , som du kommer till när du börjar bygga programkoden. För närvarande betyder detta PersonSchema ärver från en Marshmallow-basklass som heter ModelSchema , tillhandahåller attribut och funktionalitet som är gemensamma för alla klasser som härrör från den.
Resten av definitionen är som följer:
-
class Metadefinierar en klass som heterMetainom din klass.ModelSchemaklass somPersonSchemaklass ärver från sökningar efter denna internaMetaklass och använder den för att hitta SQLAlchemy-modellenPersonochdb.session. Så här hittar Marshmallow attribut iPersonklass och typen av dessa attribut så att den vet hur man serialiserar/avserialiserar dem. -
modeltalar om för klassen vilken SQLAlchemy-modell som ska användas för att serialisera/deserialisera data till och från. -
db.sessiontalar om för klassen vilken databassession som ska användas för att introspektera och bestämma attributdatatyper.
Vart är du på väg med denna klassdefinition? Du vill kunna serialisera en instans av en Person klass till JSON-data och för att deserialisera JSON-data och skapa en Person klassinstanser från den.
Skapa den initierade databasen
SQLAlchemy hanterar många av de interaktioner som är specifika för specifika databaser och låter dig fokusera på datamodellerna och hur du använder dem.
Nu när du faktiskt ska skapa en databas, som nämnts tidigare, kommer du att använda SQLite. Du gör detta av ett par anledningar. Den kommer med Python och behöver inte installeras som en separat modul. Den sparar all databasinformation i en enda fil och är därför lätt att ställa in och använda.
Att installera en separat databasserver som MySQL eller PostgreSQL skulle fungera bra men skulle kräva installation av dessa system och få igång dem, vilket ligger utanför ramen för denna artikel.
Eftersom SQLAlchemy hanterar databasen spelar det på många sätt ingen roll vad den underliggande databasen är.
Du kommer att skapa ett nytt verktygsprogram som heter build_database.py för att skapa och initiera SQLite people.db databasfil som innehåller din person databastabell. Längs vägen kommer du att skapa två Python-moduler, config.py och models.py , som kommer att användas av build_database.py och den modifierade server.py från del 1.
Här kan du hitta källkoden för de moduler du ska skapa, som presenteras här:
-
config.pyfår de nödvändiga modulerna importerade till programmet och konfigurerade. Detta inkluderar Flask, Connexion, SQLAlchemy och Marshmallow. Eftersom det kommer att användas av bådebuild_database.pyochserver.py, kommer vissa delar av konfigurationen endast att gälla förserver.pyansökan. -
models.pyär modulen där du skaparPersonSQLAlchemy ochPersonSchemaMarshmallow klassdefinitioner som beskrivs ovan. Denna modul är beroende avconfig.pyför några av de objekt som skapats och konfigurerats där.
Konfigurationsmodul
config.py modulen, som namnet antyder, är där all konfigurationsinformation skapas och initieras. Vi kommer att använda den här modulen för både vår build_database.py programfilen och den snart uppdaterade server.py fil från artikeln i del 1. Det betyder att vi kommer att konfigurera Flask, Connexion, SQLAlchemy och Marshmallow här.
Även om build_database.py Programmet använder inte Flask, Connexion eller Marshmallow, det använder SQLAlchemy för att skapa vår anslutning till SQLite-databasen. Här är koden för config.py modul:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Så här gör koden ovan:
-
Rad 2 – 4 importera Connexion som du gjorde i
server.pyprogram från del 1. Det importerar ocksåSQLAlchemyfrånflask_sqlalchemymodul. Detta ger din programdatabas åtkomst. Slutligen importerar denMarshmallowfrånflask_marshamllowmodul. -
Rad 6 skapar variabeln
basedirpekar på katalogen som programmet körs i. -
Rad 9 använder
basedirvariabel för att skapa Connexion-appinstansen och ge den sökvägen tillswagger.ymlfil. -
Rad 12 skapar en variabel
app, vilket är Flask-instansen som initierats av Connexion. -
Rader 15 använder
appvariabel för att konfigurera värden som används av SQLAlchemy. Först ställer den inSQLALCHEMY_ECHOtillTrue. Detta får SQLAlchemy att eka SQL-satser som den kör till konsolen. Detta är mycket användbart för att felsöka problem när du bygger databasprogram. Ställ in detta påFalseför produktionsmiljöer. -
Rad 16 ställer in
SQLALCHEMY_DATABASE_URItillsqlite:////' + os.path.join(basedir, 'people.db'). Detta säger åt SQLAlchemy att använda SQLite som databas och en fil med namnetpeople.dbi den aktuella katalogen som databasfil. Olika databasmotorer, som MySQL och PostgreSQL, kommer att ha olikaSQLALCHEMY_DATABASE_URIsträngar för att konfigurera dem. -
Rad 17 ställer in
SQLALCHEMY_TRACK_MODIFICATIONStillFalse, stänga av händelsesystemet SQLAlchemy, som är på som standard. Händelsesystemet genererar händelser som är användbara i händelsedrivna program men lägger till betydande omkostnader. Eftersom du inte skapar ett händelsestyrt program, stäng av den här funktionen. -
Rad 19 skapar
dbvariabel genom att anropaSQLAlchemy(app). Detta initierar SQLAlchemy genom att skickaappkonfigurationsinformation just inställd.dbvariabeln är det som importeras tillbuild_database.pyprogram för att ge den åtkomst till SQLAlchemy och databasen. Det kommer att tjäna samma syfte iserver.pyprogram ochpeople.pymodul. -
Rad 23 skapar
mavariabel genom att anropaMarshmallow(app). Detta initierar Marshmallow och låter den introspektera SQLAlchemy-komponenterna som är kopplade till appen. Det är därför Marshmallow initieras efter SQLAlchemy.
Modulmodul
models.py modulen skapas för att tillhandahålla Person och PersonSchema klasser exakt som beskrivs i avsnitten ovan om modellering och serialisering av data. Här är koden för den modulen:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Så här gör koden ovan:
-
Rad 1 importerar
datetimeobjekt fråndatetimemodul som följer med Python. Detta ger dig ett sätt att skapa en tidsstämpel iPersonklass. -
Rad 2 importerar
dbochmainstansvariabler definierade iconfig.pymodul. Detta ger modulen tillgång till SQLAlchemy-attribut och metoder kopplade tilldbvariabel och Marshmallow-attributen och metoderna som är kopplade tillmavariabel. -
Rad 4 – 9 definiera
Personklass som diskuteras i avsnittet om datamodellering ovan, men nu vet du vardb.Modelsom klassen ärver från härstammar. Detta gerPersonklass SQLAlchemy-funktioner, som en anslutning till databasen och åtkomst till dess tabeller. -
Rad 11 – 14 definiera
PersonSchemaklass som diskuterades i avsnittet om dataserialisering ovan. Den här klassen ärver frånma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodul. -
Line 3 imports the
Personclass definition from themodels.pymodul. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodul. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclass. After it is instantiated, you call thedb.session.add(p)fungera. This uses the database connection instancedbto access thesessionobjekt. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobjekt. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Obs! At Line 22, no data has been added to the database. Everything is being saved within the session objekt. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py fil. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Beskrivning |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people tabell. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml fil.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodul. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelista. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Obs! The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person databas. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()exempel. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objekt. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
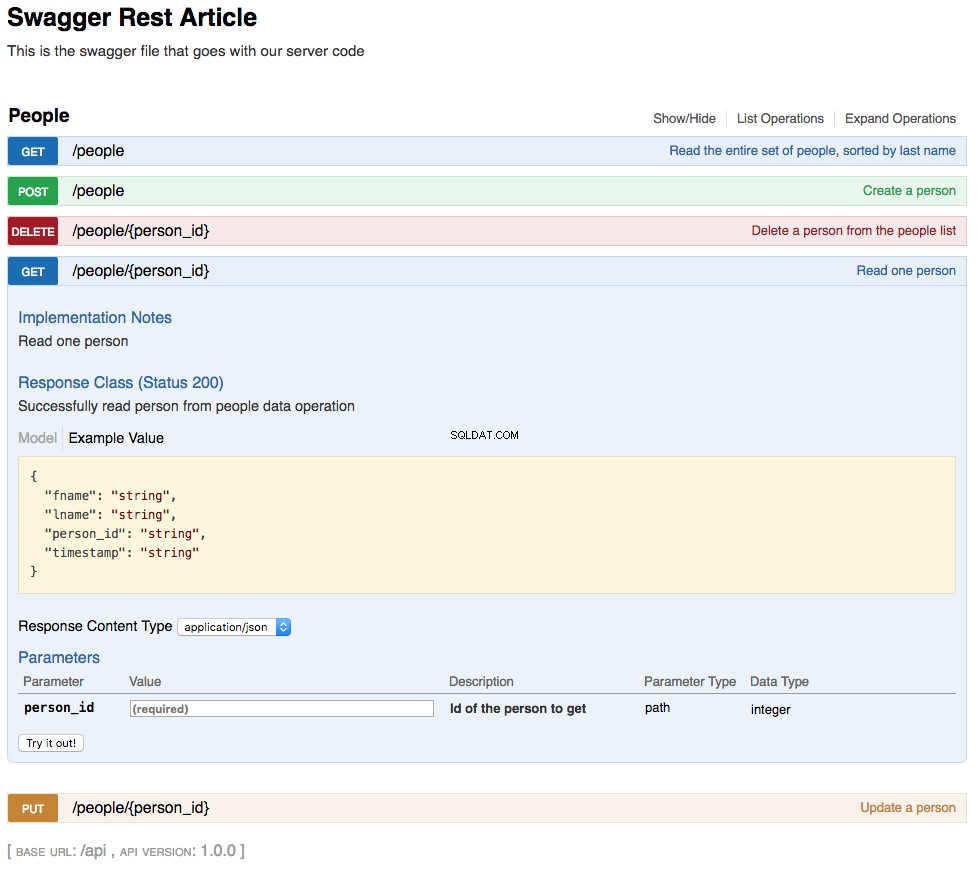
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Slutsats
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.