Detta är den trettonde och sista delen i en serie om tabelluttryck. Den här månaden fortsätter jag diskussionen jag startade förra månaden om inline-tabellvärderade funktioner (iTVF).
Förra månaden förklarade jag att när SQL Server infogar iTVFs som efterfrågas med konstanter som indata, tillämpar den parameterinbäddningsoptimering som standard. Parameterinbäddning innebär att SQL Server ersätter parameterreferenser i frågan med de bokstavliga konstantvärdena från den aktuella exekveringen, och sedan optimeras koden med konstanterna. Denna process möjliggör förenklingar som kan resultera i mer optimala frågeplaner. Den här månaden utvecklar jag ämnet och täcker specifika fall för sådana förenklingar som konstant vikning och dynamisk filtrering och beställning. Om du behöver en uppdatering om optimering av parameterinbäddning, gå igenom förra månadens artikel samt Paul Whites utmärkta artikel Parameter Sniffing, Embedding och RECOMPILE Options.
I mina exempel kommer jag att använda en exempeldatabas som heter TSQLV5. Du kan hitta skriptet som skapar och fyller det här och dess ER-diagram här.
Konstant vikning
Under tidiga skeden av frågebehandlingen utvärderar SQL Server vissa uttryck som involverar konstanter och viker dessa till resultatkonstanterna. Till exempel kan uttrycket 40 + 2 vikas till konstanten 42. Du hittar reglerna för vikbara och icke-vikbara uttryck här under "Konstant vikning och utvärdering av uttryck."
Vad som är intressant med avseende på iTVFs är att tack vare parameterinbäddningsoptimering kan frågor som involverar iTVFs där du skickar konstanter som indata, under rätt omständigheter, dra nytta av konstant vikning. Att känna till reglerna för vikbara och icke-vikbara uttryck kan påverka hur du implementerar dina iTVFs. I vissa fall, genom att tillämpa mycket subtila ändringar på dina uttryck, kan du aktivera mer optimala planer med bättre utnyttjande av indexering.
Som ett exempel, överväg följande implementering av en iTVF som heter Sales.MyOrders:
ANVÄND TSQLV5;GO SKAPA ELLER ÄNDRA FUNKTION Sales.MyOrders ( @add AS INT, @subtract AS INT )RETURNER TABLEASRETURN SELECT orderid + @add - @subtract AS myorderid, orderdate, custid, empid FROM Sales.Orders;GO
Utfärda följande fråga som involverar iTVF (jag kallar detta fråga 1):
SELECT myorderid, orderdate, custid, empidFROM Sales.MyOrders(1, 10248)ORDER BY myorderid;
Planen för fråga 1 visas i figur 1.
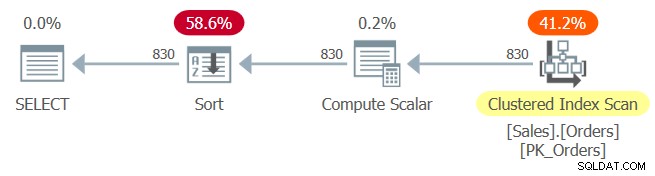 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Det klustrade indexet PK_Orders definieras med orderid som nyckel. Hade konstant vikning skett här efter parameterinbäddning, skulle beställningsuttrycket orderid + 1 – 10248 ha vikts till orderid – 10247. Detta uttryck skulle ha betraktats som ett orderbevarande uttryck med avseende på orderid, och som sådant skulle ha möjliggjort optimizer för att lita på indexordning. Tyvärr är det inte fallet, vilket framgår av den explicita sorteringsoperatören i planen. Så vad hände?
Konstanta vikregler är petiga. Uttrycket kolumn1 + konstant1 – konstant2 utvärderas från vänster till höger för konstant vikning. Den första delen, kolumn1 + konstant1 är inte vikt. Låt oss kalla detta uttryck1. Nästa del som utvärderas behandlas som expression1 – konstant2, som inte heller är vikt. Utan vikning anses ett uttryck i formen kolumn1 + konstant1 – konstant2 inte vara ordningsbevarande med avseende på kolumn1, och kan därför inte förlita sig på indexordning även om du har ett stödjande index på kolumn1. På liknande sätt är uttrycket konstant1 + kolumn1 – konstant2 inte konstantvikbart. Uttrycket konstant1 – konstant2 + kolumn1 är dock vikbart. Mer specifikt viks den första delen konstant1 – konstant2 till en enda konstant (låt oss kalla den konstant3), vilket resulterar i uttrycket konstant3 + kolumn1. Detta uttryck anses vara ett ordningsbevarande uttryck med avseende på kolumn1. Så så länge du ser till att skriva ditt uttryck med det sista formuläret, kan du aktivera optimeraren att förlita sig på indexordning.
Tänk på följande frågor (jag kallar dem Fråga 2, Fråga 3 och Fråga 4), och innan du tittar på frågeplanerna, se om du kan se vilka som kommer att innebära explicit sortering i planen och vilka som inte gör det:
-- Fråga 2SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empidFROM Sales.OrdersORDER BY myorderid; -- Fråga 3SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empidFROM Sales.OrdersORDER BY myorderid; -- Fråga 4SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empidFROM Sales.OrdersORDER BY myorderid;
Undersök nu planerna för dessa frågor som visas i figur 2.
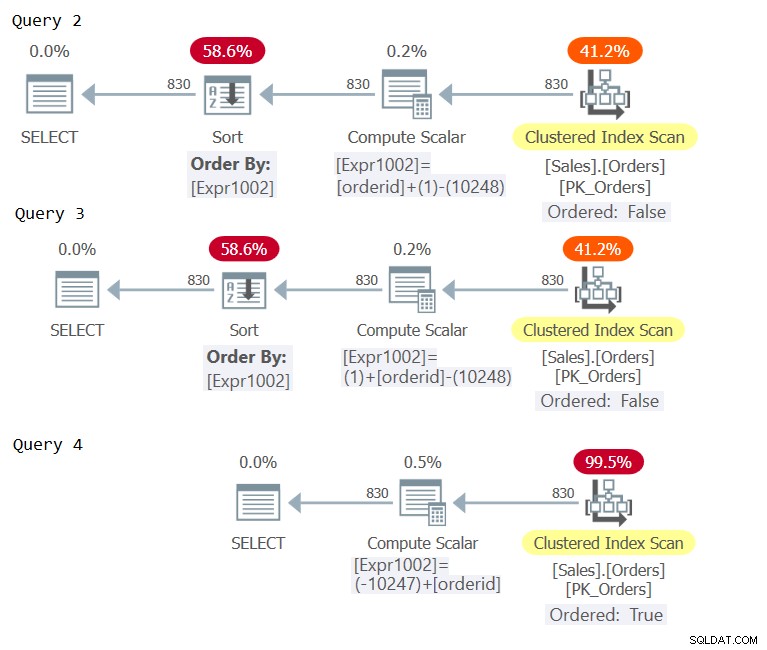 Figur 2:Planer för fråga 2, fråga 3 och fråga 4
Figur 2:Planer för fråga 2, fråga 3 och fråga 4
Undersök Compute Scalar-operatörerna i de tre planerna. Endast planen för fråga 4 ådrog sig konstant vikning, vilket resulterade i ett ordnande uttryck som anses vara ordningsbevarande med avseende på orderid, vilket undviker explicit sortering.
För att förstå denna aspekt av konstant vikning kan du enkelt fixa iTVF genom att ändra uttrycket orderid + @add – @subtract till @add – @subtract + orderid, så här:
SKAPA ELLER ÄNDRA FUNKTION Sales.MyOrders ( @add AS INT, @subtract AS INT )RETURNER TABLEASRETURN SELECT @add - @subtract + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders;GO
Fråga funktionen igen (jag kallar detta fråga 5):
SELECT myorderid, orderdate, custid, empidFROM Sales.MyOrders(1, 10248)ORDER BY myorderid;
Planen för denna fråga visas i figur 3.
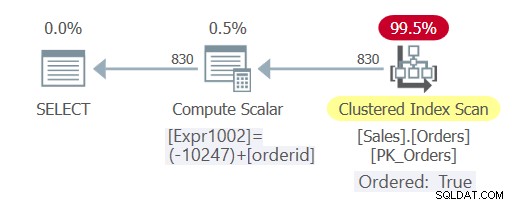 Figur 3:Plan för fråga 5
Figur 3:Plan för fråga 5
Som du kan se upplevde frågan den här gången konstant vikning och optimeraren kunde förlita sig på indexordning och undviker explicit sortering.
Jag använde ett enkelt exempel för att demonstrera denna optimeringsteknik, och som sådan kan den verka lite konstruerad. Du kan hitta en praktisk tillämpning av denna teknik i artikeln Number series generator challenge solutions – Part 1.
Dynamisk filtrering/ordning
Förra månaden tog jag upp skillnaden mellan hur SQL Server optimerar en fråga i en iTVF jämfört med samma fråga i en lagrad procedur. SQL Server kommer vanligtvis att tillämpa parameterinbäddningsoptimering som standard för en fråga som involverar en iTVF med konstanter som indata, men optimerar den parametriserade formen av en fråga i en lagrad procedur. Men om du lägger till OPTION(RECOMPILE) till frågan i den lagrade proceduren, kommer SQL Server vanligtvis att tillämpa parameterinbäddningsoptimering även i detta fall. Fördelarna i iTVF-fallet inkluderar det faktum att du kan involvera det i en fråga, och så länge du klarar upprepade konstanta inmatningar, finns det potential att återanvända en tidigare cachad plan. Med en lagrad procedur kan du inte involvera den i en fråga, och om du lägger till OPTION(RECOMPILE) för att få parameterinbäddningsoptimering finns det ingen möjlighet att återanvända planen. Den lagrade proceduren ger mycket mer flexibilitet när det gäller kodelementen du kan använda.
Låt oss se hur allt detta utspelar sig i en klassisk parameterinbäddnings- och beställningsuppgift. Följande är en förenklad lagrad procedur som tillämpar dynamisk filtrering och sortering liknande den som Paul använde i sin artikel:
SKAPA ELLER ÄNDRA PROCEDUR HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINTASSET NOCOUNT ON; VÄLJ empid, förnamn, efternamn FRÅN HR.Anställda WHERE efternamn SOM @efternamnsmönster ELLER @efternamnsmönster ÄR NULLORDER BY CASE NÄR @sort =1 DÅ empid END, CASE WHEN @sort =2 THEN firstname END, CASE NÄR @NGO-efternamn =END;
Observera att den nuvarande implementeringen av den lagrade proceduren inte inkluderar OPTION(RECOMPILE) i frågan.
Överväg följande exekvering av den lagrade proceduren:
EXEC HR.GetEmpsP @lastnamepattern =N'D%', @sort =3;
Planen för detta utförande visas i figur 4.
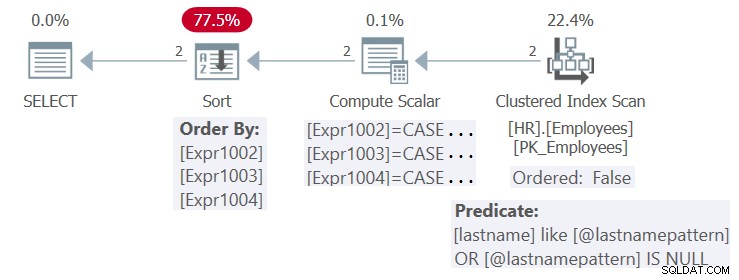 Figur 4:Plan för procedur HR.GetEmpsP
Figur 4:Plan för procedur HR.GetEmpsP
Det finns ett index definierat i kolumnen efternamn. Teoretiskt sett kan indexet med de nuvarande ingångarna vara fördelaktigt både för filtreringsbehoven (med en sökning) och ordningsbehoven (med en beställd:sann intervallskanning) för frågan. Men eftersom SQL Server som standard optimerar den parametriserade formen av frågan och inte tillämpar parameterinbäddning, tillämpar den inte de förenklingar som krävs för att kunna dra nytta av indexet för både filtrerings- och beställningssyften. Så planen är återanvändbar, men den är inte optimal.
För att se hur saker och ting förändras med parameterinbäddningsoptimering, ändra den lagrade procedurfrågan genom att lägga till OPTION(RECOMPILE), så här:
SKAPA ELLER ÄNDRA PROCEDUR HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINTASSET NOCOUNT ON; VÄLJ empid, förnamn, efternamn FRÅN HR.Anställda WHERE efternamn SOM @efternamnsmönster ELLER @efternamnsmönster ÄR NULLORDER BY CASE WHEN @sort =1 DÅ empid END, CASE WHEN @sort =2 THEN firstname END, CASE WHEN THENRECOMLE );GO
Utför den lagrade proceduren igen med samma ingångar som du använde tidigare:
EXEC HR.GetEmpsP @lastnamepattern =N'D%', @sort =3;
Planen för detta utförande visas i figur 5.
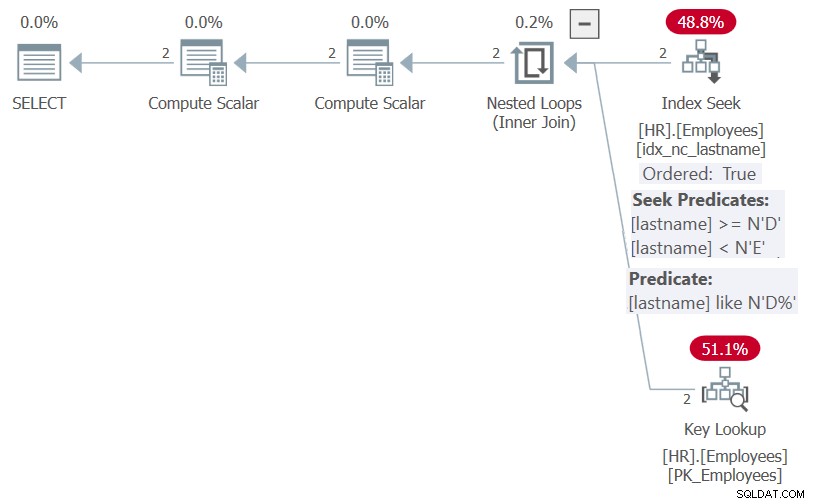 Figur 5:Plan för procedur HR.GetEmpsP med OPTION(RECOMPILE)
Figur 5:Plan för procedur HR.GetEmpsP med OPTION(RECOMPILE)
Som du kan se, tack vare parameterinbäddningsoptimering, kunde SQL Server förenkla filterpredikatet till det sargbara predikatet efternamn LIKE N'D%', och ordningslistan till NULL, NULL, efternamn. Båda elementen kan dra nytta av indexet på efternamn, och därför visar planen en sökning i indexet och ingen explicit sortering.
Teoretiskt sett förväntar du dig att kunna få liknande förenkling om du implementerar frågan i en iTVF, och därmed liknande optimeringsfördelar, men med möjligheten att återanvända cachade planer när samma ingångsvärden återanvänds. Så låt oss försöka...
Här är ett försök att implementera samma fråga i en iTVF (kör inte den här koden ännu):
SKAPA ELLER ÄNDRA FUNKTION HR.GetEmpsF( @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT)RETURNER TABLEASRETURN SELECT empid, firstname, efternamn FRÅN HR.Employees WHERE efternamn SOM @efternamnsmönster ELLER ÄR BYN efternamn WLL @sort =1 THEN empid END, CASE WHEN @sort =2 THEN firstname END, CASE WHEN @sort =3 THEN efternamn END;GO
Innan du försöker köra den här koden, kan du se ett problem med den här implementeringen? Kom ihåg att jag tidigt i den här serien förklarade att ett tabelluttryck är en tabell. En tabells kropp är en uppsättning (eller flera uppsättningar) rader och har som sådan ingen ordning. Därför kan normalt en fråga som används som ett tabelluttryck inte ha en ORDER BY-sats. Om du försöker köra den här koden får du faktiskt följande felmeddelande:
Msg 1033, Level 15, State 1, Procedure GetEmps, Line 16 [Batch Start Line 128]ORDER BY-satsen är ogiltig i vyer, inline-funktioner, härledda tabeller, underfrågor och vanliga tabelluttryck, såvida inte TOP, OFFSET eller FOR XML anges också.
Visst, som felet säger, kommer SQL Server att göra ett undantag om du använder ett filtreringselement som TOP eller OFFSET-FETCH, som förlitar sig på ORDER BY-satsen för att definiera ordningsaspekten för filtret. Men även om du inkluderar en ORDER BY-sats i den inre frågan tack vare detta undantag, får du fortfarande ingen garanti för ordningen på resultatet i en yttre fråga mot tabelluttrycket, om den inte har en egen ORDER BY-sats .
Om du fortfarande vill implementera frågan i en iTVF kan du låta den inre frågan hantera den dynamiska filtreringsdelen, men inte den dynamiska ordningen, som så:
SKAPA ELLER ÄNDRA FUNKTION HR.GetEmpsF( @lastnamepattern AS NVARCHAR(50))RETURNER TABLEASRETURN VÄLJ empid, förnamn, efternamn FRÅN HR.Anställda VAR efternamn SOM @lastnamepattern ELLER @lastnamepattern ÄR NULL;Naturligtvis kan du låta den yttre frågan hantera alla specifika beställningsbehov, som i följande kod (jag kallar detta fråga 6):
VÄLJ empid, förnamn, efternamnFROM HR.GetEmpsF(N'D%')ORDER BY efternamn;Planen för denna fråga visas i figur 6.
Figur 6:Plan för fråga 6
Tack vare inlining och parameterinbäddning liknar planen den som visades tidigare för den lagrade procedurfrågan i figur 5. Planen förlitar sig effektivt på indexet för både filtrerings- och beställningssyften. Du får dock inte den flexibilitet i den dynamiska beställningsinmatningen som du hade med den lagrade proceduren. Du måste vara tydlig med ordningen i ORDER BY-satsen i frågan mot funktionen.
Följande exempel har en fråga mot funktionen utan filtrering och inga beställningskrav (jag kallar detta fråga 7):
VÄLJ empid, förnamn, efternamnFROM HR.GetEmpsF(NULL);Planen för denna fråga visas i figur 7.
Figur 7:Plan för fråga 7
Efter inlining och parameterinbäddning förenklas frågan så att den inte har något filterpredikat och ingen ordning, och den optimeras med en fullständig oordnad genomsökning av det klustrade indexet.
Fråga slutligen funktionen med N'D%' som inmatat efternamnsfiltreringsmönster och ordna resultatet efter förnamnskolumnen (jag hänvisar till detta som fråga 8):
VÄLJ empid, förnamn, efternamnFROM HR.GetEmpsF(N'D%')ORDER BY firstname;Planen för denna fråga visas i figur 8.
Figur 8:Plan för fråga 8
Efter förenkling involverar frågan endast filtreringspredikatet efternamn LIKE N'D%' och beställningselementet förnamn. Den här gången valde optimeraren att tillämpa en oordnad skanning av det klustrade indexet, med det kvarvarande predikatets efternamn LIKE N'D%', följt av explicit sortering. Den valde att inte använda en sökning i indexet på efternamn eftersom indexet inte är ett täckande sådant, tabellen är så liten och indexordningen är inte fördelaktig för de aktuella sökorderbehoven. Dessutom finns det inget index definierat i kolumnen för förnamn, så en explicit sortering måste tillämpas ändå.
Slutsats
Standardparameterinbäddningsoptimeringen av iTVFs kan också resultera i konstant vikning, vilket möjliggör mer optimala planer. Du måste dock vara uppmärksam på ständiga vikregler för att avgöra hur du bäst formulerar dina uttryck.
Att implementera logik i en iTVF har fördelar och nackdelar jämfört med att implementera logik i en lagrad procedur. Om du inte är intresserad av parameterinbäddningsoptimering, kan standardparameteriserad frågeoptimering av lagrade procedurer resultera i mer optimal plancachning och återanvändningsbeteende. I de fall du är intresserad av parameterinbäddningsoptimering får du det vanligtvis som standard med iTVFs. För att få denna optimering med lagrade procedurer måste du lägga till frågealternativet REKOMPIERA, men då får du inte återanvändning av planen. Åtminstone med iTVF kan du få planåteranvändning förutsatt att samma parametervärden upprepas. Återigen har du mindre flexibilitet med frågeelementen du kan använda i en iTVF; till exempel, du får inte ha en presentation ORDER BY-klausul.
Tillbaka till hela serien om tabelluttryck, jag tycker att ämnet är superviktigt för databasutövare. Den mer kompletta serien inkluderar underserien på nummerseriegeneratorn, som är implementerad som en iTVF. Totalt innehåller serien följande 19 delar:
- Grundläggande för tabelluttryck, del 1
- Grundläggande av tabelluttryck, del 2 – Härledda tabeller, logiska överväganden
- Grundläggande av tabelluttryck, del 3 – Härledda tabeller, optimeringsöverväganden
- Grundläggande av tabelluttryck, del 4 – Härledda tabeller, optimeringsöverväganden, fortsättning
- Grundläggande tabelluttryck, del 5 – CTE:er, logiska överväganden
- Grundläggande för tabelluttryck, del 6 – Rekursiva CTE:er
- Grundläggande för tabelluttryck, del 7 – CTE:er, optimeringsöverväganden
- Grundläggande tabelluttryck, del 8 – CTE:er, optimeringsöverväganden fortsatte
- Grundläggande av tabelluttryck, del 9 – Visningar, jämfört med härledda tabeller och CTE:er
- Grundläggande för tabelluttryck, del 10 – vyer, SELECT * och DDL-ändringar
- Grundläggande av tabelluttryck, del 11 – Synpunkter, överväganden om modifiering
- Grundläggande av tabelluttryck, del 12 – Inline tabellvärderade funktioner
- Grundläggande av tabelluttryck, del 13 – Inline tabellvärderade funktioner, fortsättning
- Utmaningen är igång! Samhällsuppmaning för att skapa den snabbaste nummerseriegeneratorn
- Utmaningslösningar för nummerseriegeneratorer – del 1
- Utmaningslösningar för nummerseriegeneratorer – del 2
- Utmaningslösningar för nummerseriegeneratorer – del 3
- Utmaningslösningar för nummerseriegeneratorer – del 4
- Utmaningslösningar för nummerseriegenerator – del 5