I den här artikeln kommer jag att förklara hur man flyttar en tabell från den primära filgruppen till den sekundära filgruppen. Låt oss först förstå vad som är datafil, filgrupp och typ av filgrupper.
Databasfiler och filgrupper
När SQL Server är installerad på vilken server som helst, skapar den en primär datafil och loggfil för att lagra data. Den primära datafilen lagrar data och databasobjekt som tabeller, index, lagrade procedurer, etc. Loggfiler lagrar information som krävs för att återställa transaktioner. Datafiler kan klubbas ihop i filgrupper.
SQL Server har tre typer av filer
- Primär fil :Den skapas när SQL-servern installeras, och den innehåller databasens metadata och information. Användardata, objekt kan lagras på de primära datafilerna. Den primära filen har filtillägget .mdf.
- Sekundär fil :Sekundära filer är användardefinierade. De lagrar användardata, objekt skapade av en användare. De har tillägget .ndf.
- Transaktionsloggfil s:T-Logs-filerna loggar alla transaktioner som utförts för att återställa databasen. Loggfiltillägget i .ldf.
Som jag nämnde ovan kan datafiler grupperas i en filgrupp. Medan SQL Server installeras skapar den den primära filgruppen som har en primär datafil. Sekundära filgrupper är användardefinierade. De har sekundära datafiler. När vi skapar en ny databas kan vi skapa sekundära datafiler och filgrupper. Att lägga till sekundära datafiler hjälper till att förbättra prestandan. Den kan skapas på olika hårddiskar eller separata diskpartitioner som minskar IO-vänte- och läs-skrivfördröjningen.
Det rekommenderas att hålla tabeller och index i separata filgrupper. Att hålla stora tabeller i separata filer förbättrar dessutom prestandan.
Det finns tre typer av filgrupper:
- Radfilgrupp :Radfilgrupp, även känd som Primär filgrupp, innehåller en primär datafil. SQL-objekt, data, systemtabeller allokeras till den primära filgruppen.
- Minnesoptimerad filgrupp :Minnesoptimerad filgrupp innehåller minnesoptimerade tabeller och data. För att aktivera OLTP i minnet måste vi skapa en minnesoptimerad filgrupp.
- FileStream :Filströmsfilgruppen innehåller filströmsdata som bilder, dokument, körbara filer etc. Den primära filgruppen kan inte innehålla filströmsdata, vi måste skapa en FileStream-filgrupp. Den innehåller FileStream-data.
Demoinställningar
I den här demon skapade jag "DemoDatabase" på SQL Server 2017-instansen. Flikarna "Records" och "PatientData" skapades i databasen. Primärnyckeln "PK_CIDX_Records_ID" skapades i tabellen "Records" och det klustrade indexet "CIDX_PatientData_ID" skapades i tabellen "PatientData". I denna demo kommer jag att flytta tabellerna "Records" och "PatientData" från den primära filgruppen till den sekundära filgruppen.
För detta måste vi göra följande:
- Skapa en sekundär filgrupp.
- Lägg till datafiler i den sekundära filgruppen.
- Flytta tabellen till den sekundära filgruppen genom att flytta det klustrade indexet med den primära nyckelbegränsningen.
- Flytta tabellerna till den sekundära filgruppen genom att flytta det klustrade indexet utan primärnyckeln.
Skapa sekundär filgrupp
En sekundär filgrupp kan skapas med T-SQL ELLER med hjälp av guiden Lägg till fil från SQL Server Management Studio. För att lägga till en filgrupp med SSMS, öppna SSMS och välj en databas där en filgrupp måste skapas. Högerklicka på databasen och välj "Egenskaper ”>> välj ”Filgrupper " och klicka på "Lägg till filgrupp ” som visas i följande bild:
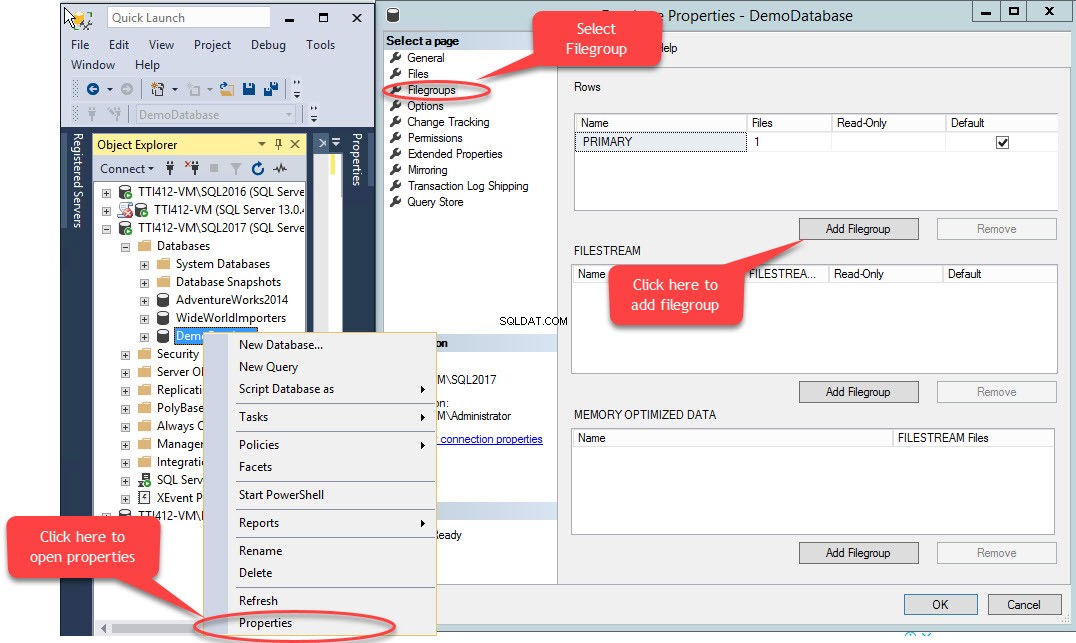
När vi klickar på "Lägg till filgrupp "-knappen kommer en rad att läggas till i "rader " rutnät. I "rader " rutnätet, ange lämpligt filgruppsnamn i "Namn " kolumn. Filgrupp är varken skrivskyddad eller standard; behåll därför Skrivskyddat och Standard kryssrutor avmarkerade för ny filgrupp. Se följande bild:
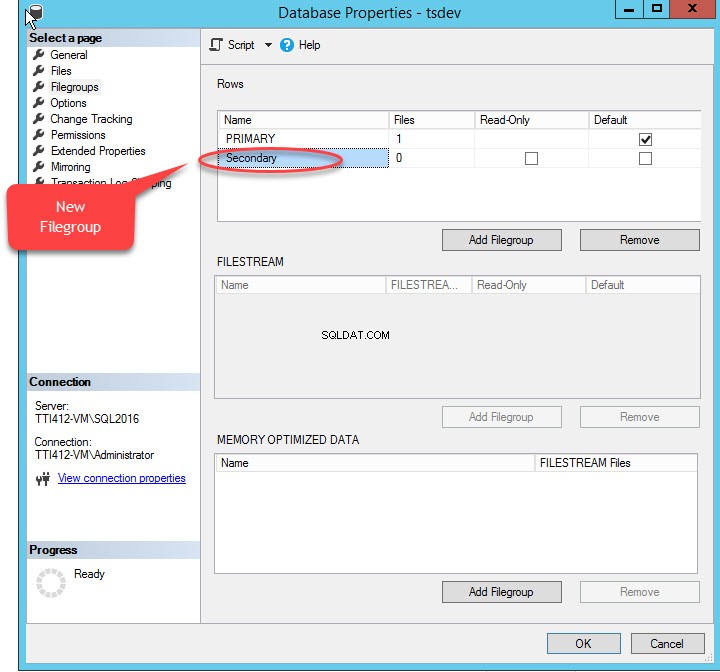
Klicka på OK för att stänga dialogrutan.
För att skapa en filgrupp med T-SQL-skript, kör följande skript.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Lägga till filer i filgruppen
För att lägga till filer i en filgrupp, öppna databasegenskaper, välj "filer" och klicka på "Lägg till". Som visas i följande bild:
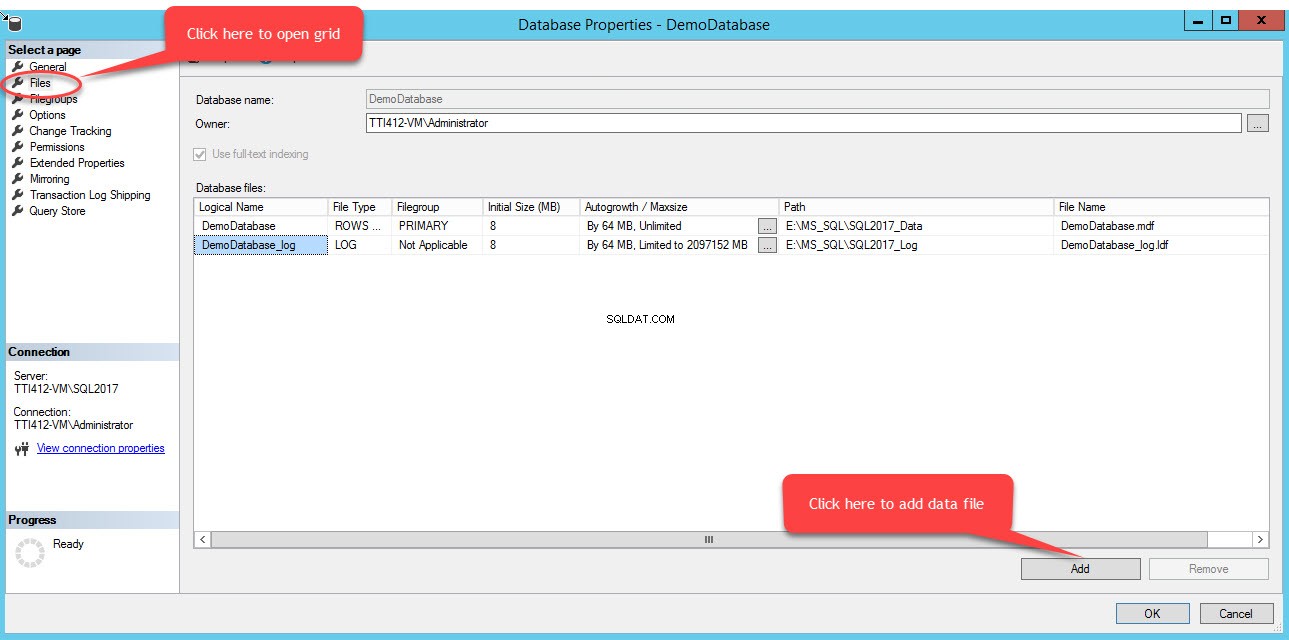
En tom rad kommer att läggas till i Databasfiler rutnätsvy. Ange lämpligt logiskt namn i Logiskt namn i rutnätsvyn kolumnen väljer du Raddata från Filtyp rullgardinsmenyn väljer du sekundär från filgruppen rullgardinsmenyn, ställ in initialstorleken på filen i Ursprunglig storlek kolumner, ställ in parametern för automatisk tillväxt och maxstorlek i Autotillväxt/Maxstorlek kolumnen, ange fysisk plats för den sekundära datafilen i sökvägen kolumnen och ange lämpligt filnamn i Filnamn kolumn. Se följande bild:
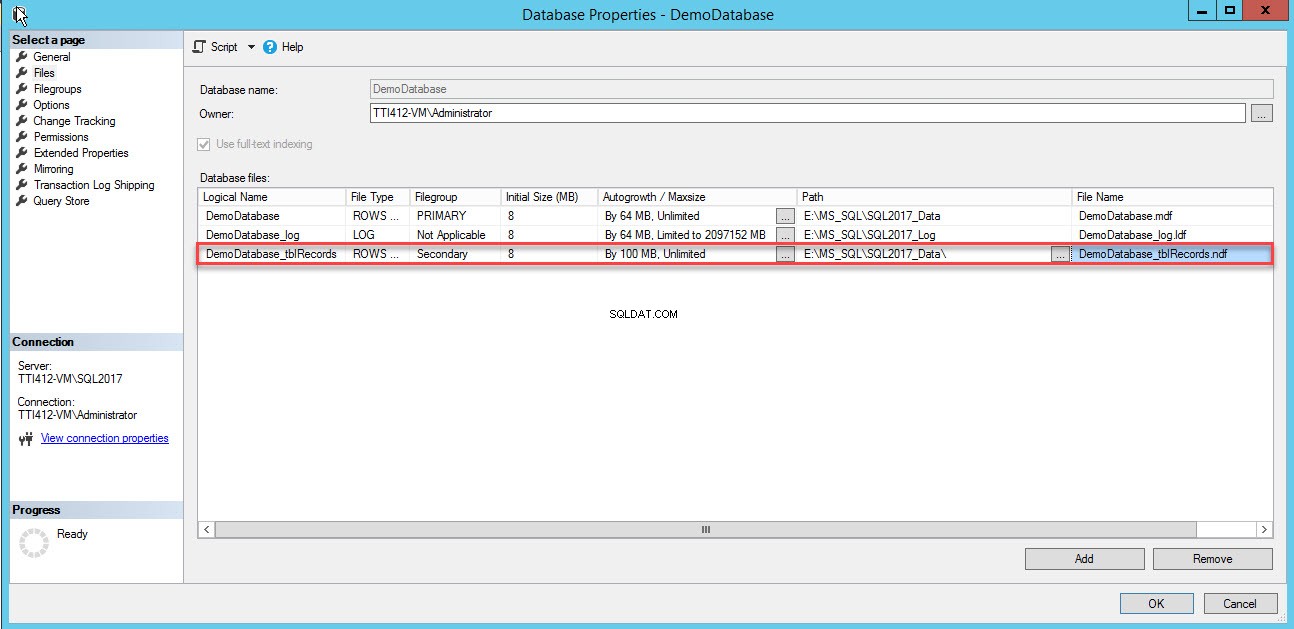
Använd följande T-SQL-skript för att skapa en sekundär datafil.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
Den sekundära datafilen har skapats. Se följande bild:
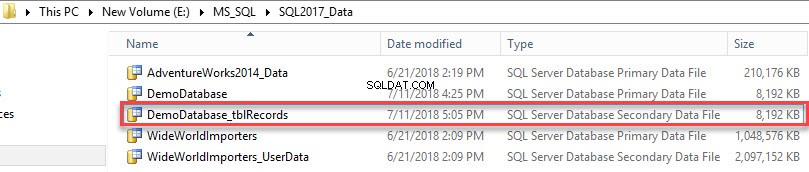
För att se en lista över filgrupper skapade i databasen, kör följande fråga.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Nedan är en utdata av frågan.

Överföra befintlig tabell från primär filgrupp till sekundär filgrupp
Vi kan flytta en befintlig tabell till en annan filgrupp genom att flytta det klustrade indexet till en annan filgrupp. Som vi vet har en lövnod i det klustrade indexet faktiska data; därför kan flytta klustrade index flytta hela tabellen till en annan filgrupp. Flytta index har en begränsning:om indexet är en primärnyckel eller unik begränsning kan du inte flytta index med SQL Server Management Studio. För att flytta dessa index måste vi använda skapa index och med DROP_Existing=ON alternativ.
Flytta klustrade index med primärnyckelbegränsning.
Primärnyckel tvingar fram unika värden och skapar därför det unika klustrade indexet. Nyckelkolumnen är PRN. För att skapa den i den sekundära filgruppen, ställ in DROP_EXISTING=ON alternativet och filgruppen ska vara sekundär. Kör följande skript.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
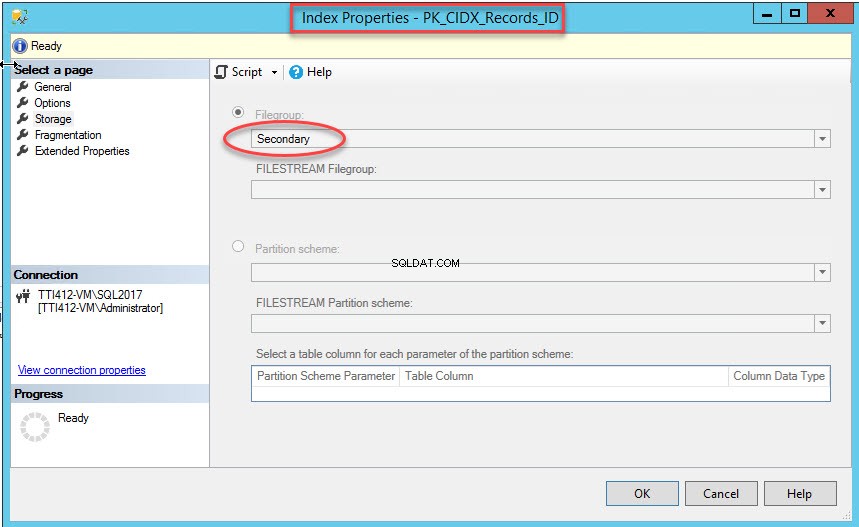
När kommandot har utförts framgångsrikt, kontrollera att index har skapats i den sekundära filgruppen. För detta högerklickar du på Lagring alternativet i Indexegenskaper dialog ruta. För att öppna indexegenskaper, expandera DemoDatabase databas>> expandera Tabell>> expandera Index . Högerklicka på PK_CIDX_Records_ID , som visas i följande bild:
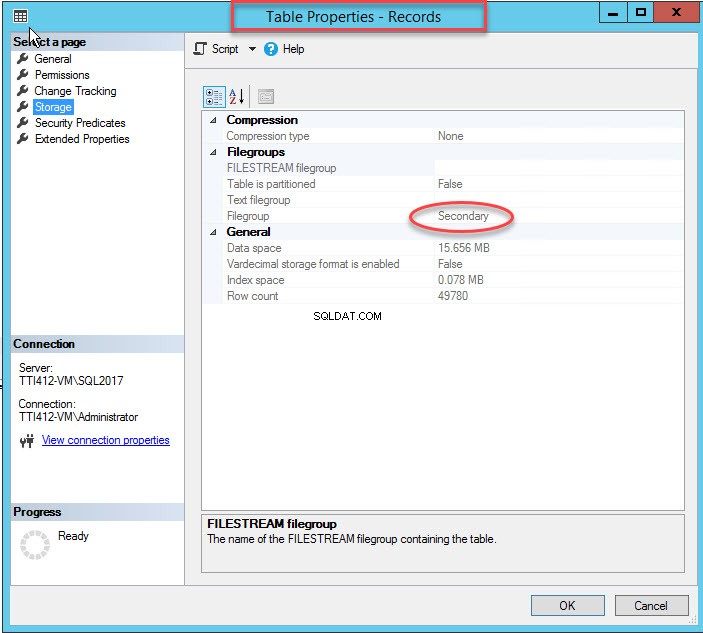
Som jag nämnde, när klustrade index flyttas till en sekundär filgrupp, kommer tabellen att flyttas till den sekundära filgruppen. För att verifiera det högerklickar du på Lagring alternativet i Tabellegenskaper dialog ruta. För att öppna indexegenskaper, expandera DemoDatabase databas>> expandera Tabell s>> högerklicka på Records, och välj lagring som visas i följande bild:
Flytta klustrade index utan primärnyckel
Vi kan flytta klustrade index utan primärnyckel med SQL Server Management Studio. För att göra det, expandera DemoDatabasen databas>> expandera Tabell>> expandera Index s>> högerklicka på CIDX_PatientData_ID indexera och välj Egenskaper, som visas i följande bild:
Indexegenskaper dialogrutan öppnas. Välj Lagring i dialogrutan och klicka på Filgrupp i fönstret Lagring rullgardinsmenyn väljer du Sekundär filgrupp och klicka på OK, som visas i följande bild:
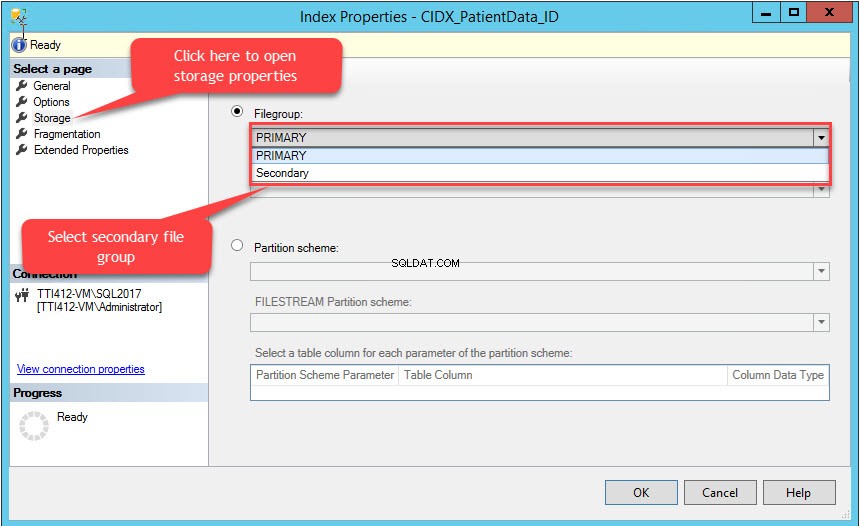
Ändring av indexfilgruppen kommer att återskapa hela indexet. När indexet har återskapats öppnar du Tabellegenskaper och välj en lagring.
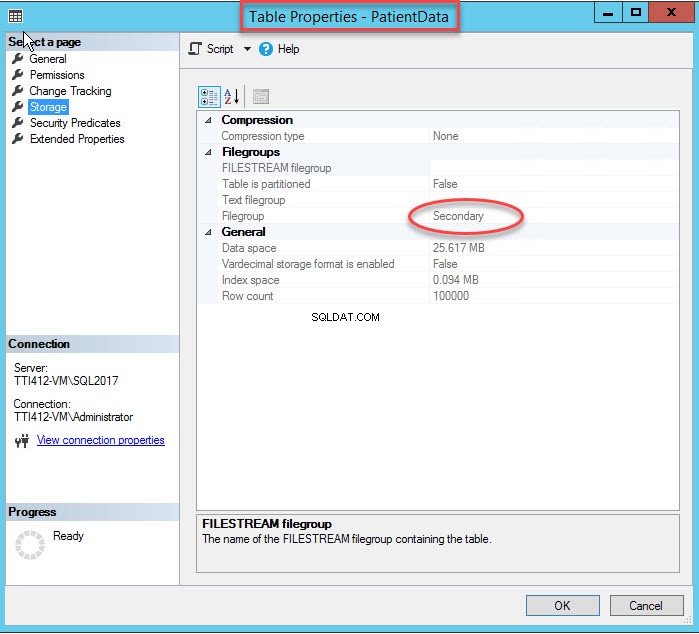
Som du kan se i bilden ovan, tillsammans med att flytta CIDX_PatientData_ID klustrade index till den sekundära filgruppen,PatientData tabellen flyttas också till Sekundär filgrupp.
Genom att utföra följande fråga kan du hitta listan över objekt som skapats till olika filgrupper:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Nedan är resultatet av frågan:
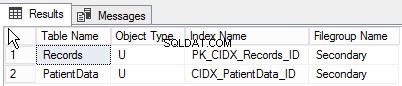
Sammanfattning
I den här artikeln har jag förklarat
-
- Grunderna för datafiler och filgrupper.
- Hur man skapar en sekundär filgrupp och lägger till en sekundär datafil i den.
- Flytta tabellen till sekundär filgrupp genom att flytta:
- Primär nyckel.
- Klustrat index.