Om du vill veta allt om Hadoop MapReduce har du landat på rätt plats. Denna MapReduce-handledning ger dig den kompletta guiden om allt i Hadoop MapReduce.
I denna MapReduce-introduktion kommer du att utforska vad Hadoop MapReduce är, hur MapReduce-ramverket fungerar. Artikeln täcker också MapReduce DataFlow, olika faser i MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sortering, Data Locality och många fler.
Vi har också utnyttjat fördelarna med MapReduce-ramverket.
Låt oss först utforska varför vi behöver Hadoop MapReduce.
Varför MapReduce?
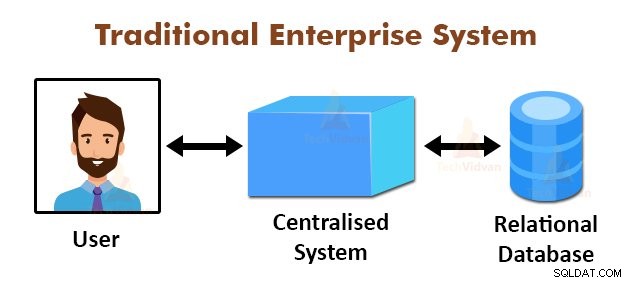
Ovanstående figur visar en schematisk bild av de traditionella företagssystemen. De traditionella systemen har normalt en centraliserad server för lagring och bearbetning av data. Denna modell är inte lämplig för att bearbeta stora mängder skalbar data.
Denna modell kunde inte heller hanteras av standarddatabasservrarna. Dessutom skapar det centraliserade systemet för mycket flaskhals när flera filer behandlas samtidigt.
Genom att använda MapReduce-algoritmen löste Google detta flaskhalsproblem. MapReduce-ramverket delar upp uppgiften i små delar och tilldelar uppgifter till många datorer.
Senare samlas resultaten på en vanlig plats och integreras sedan för att bilda resultatdataset.
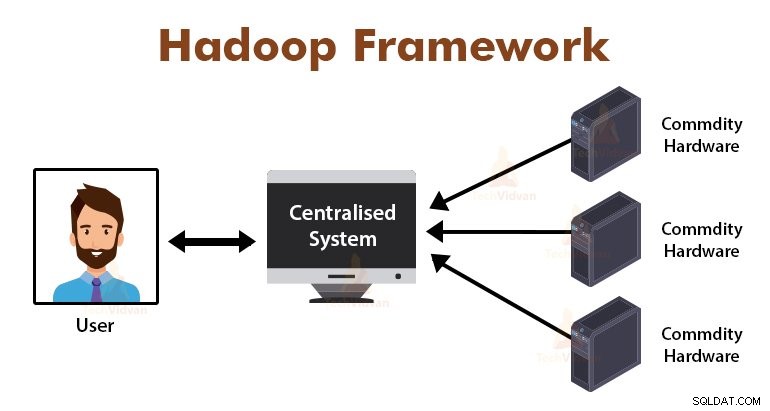
Introduktion till MapReduce Framework
MapReduce är bearbetningsskiktet i Hadoop. Det är ett mjukvaruramverk utformat för att parallellt bearbeta enorma mängder data genom att dela upp uppgiften i en uppsättning oberoende uppgifter.
Vi behöver bara lägga in affärslogiken i hur MapReduce fungerar, och ramverket kommer att ta hand om resten. MapReduce-ramverket fungerar genom att dela upp jobbet i små uppgifter och tilldelar dessa uppgifter till slavarna.
MapReduce-programmen är skrivna i en speciell stil som påverkas av de funktionella programmeringskonstruktionerna, specifika idiom för bearbetning av listor med data.
I MapReduce är ingångarna i form av en lista och utdata från ramverket är också i form av en lista. MapReduce är hjärtat i Hadoop. Effektiviteten och kraftfullheten hos Hadoop beror på MapReduce-ramverket parallell bearbetning.
Låt oss nu utforska hur Hadoop MapReduce fungerar.
Hur fungerar Hadoop MapReduce?
Hadoop MapReduce-ramverket fungerar genom att dela upp ett jobb i oberoende uppgifter och utföra dessa uppgifter på slavmaskiner. MapReduce-jobbet utförs i två steg som är kartfas och reduceringsfas.
Ingången till och utmatningen från båda faserna är nyckel- och värdepar. MapReduce-ramverket är baserat på datalokalitetsprincipen (diskuteras senare) vilket innebär att det skickar beräkningen till noderna där data finns.
- Kartfas − I kartfasen bearbetar den användardefinierade kartfunktionen indata. I kartfunktionen lägger användaren in affärslogiken. Utdata från kartfasen är mellanutgångarna och lagras på den lokala disken.
- Reducera fas – Denna fas är kombinationen av shuffle-fasen och reduceringsfasen. I Reducer-fasen skickas utdata från kartsteget till Reducer där de aggregeras. Utsignalen från reduceringsfasen är den slutliga utsignalen. I Reduce-fasen bearbetar den användardefinierade reduceringsfunktionen Mappers-utdata och genererar de slutliga resultaten.
Under MapReduce-jobbet skickar Hadoop-ramverket kartuppgifterna och reduceringsuppgifterna till lämpliga maskiner i klustret.
Ramverket självt hanterar alla detaljer för dataöverföringen, såsom att utfärda uppgifter, verifiera uppgiftens slutförande och kopiera data mellan noderna runt klustret. Arbetsuppgifterna sker på de noder där data finns för att minska nätverkstrafiken.
MapReduce Data Flow
Ni kanske alla vill veta hur dessa nyckelvärdespar genereras och hur MapReduce bearbetar indata. Det här avsnittet svarar på alla dessa frågor.
Låt oss se hur data måste flöda från olika faser i Hadoop MapReduce för att hantera kommande data på ett parallellt och distribuerat sätt.
1. Indatafiler
Indatadataset, som ska bearbetas av MapReduce-programmet, lagras i InputFile. Inmatningsfilen lagras i Hadoops distribuerade filsystem.
2. InputSplit
Posten i InputFiles är uppdelad i den logiska modellen. Den delade storleken är i allmänhet lika med HDFS-blockstorleken. Varje uppdelning bearbetas av den individuella kartläggaren.
3. InputFormat
InputFormat anger filinmatningsspecifikationen. Den definierar vägen till RecordReader där posten från InputFile konverteras till nyckel-värdeparen.
4. RecordReader
RecordReader läser data från InputSplit och konverterar poster till nyckel, värdepar och presenterar dem för Mappers.
5. Kartläggare
Kartläggare tar nyckel-, värdepar som input från RecordReader och bearbetar dem genom att implementera användardefinierad kartfunktion. I varje Mapper, åt gången, bearbetas en enda delning.
Utvecklaren lade in affärslogiken i kartfunktionen. Utdata från alla mappare är den mellanliggande utdata, som också är i form av en nyckel, värdepar.
6. Blanda och sortera
Den mellanliggande utdata som genereras av Mappers sorteras innan den skickas till Reducer för att minska nätverksstockning. De sorterade mellanutgångarna blandas sedan till Reducer över nätverket.
7. Reducerare
Reducer-processen och aggregerar Mapper-utdata genom att implementera användardefinierad reduceringsfunktion. Reducers utdata är den slutliga utdata och lagras i Hadoop Distributed File System (HDFS).
Låt oss nu studera några terminologier och avancerade koncept för Hadoop MapReduce-ramverket.
Nyckel-Value-par i MapReduce
MapReduce-ramverket fungerar på nyckel-värdeparen eftersom det handlar om det icke-statiska schemat. Det tar data i form av nyckel, värdepar, och genererad utdata är också i form av en nyckel, värdepar.
MapReduce-nyckelvärdeparet är en postenhet som tas emot av MapReduce-jobbet för exekveringen. I ett nyckel-värdepar:
- Nyckel är linjeförskjutningen från början av raden i filen.
- Värde är radens innehåll, exklusive linjeavslutningarna.
MapReduce Partitioner
Hadoop MapReduce Partitioner partitionerar tangentutrymmet. Partitionering av nyckelutrymme i MapReduce anger att alla värden för varje nyckel grupperades tillsammans, och det säkerställer att alla värden för den enstaka nyckeln måste gå till samma Reducer.
Denna partitionering tillåter jämn fördelning av mapparens utdata över Reducer genom att säkerställa att rätt nyckel går till rätt Reducer.
MapReducers standardpartitionerare är Hash Partitioner, som partitionerar nyckelrymden på basis av hashvärdet.
MapReduce Combiner
MapReduce Combiner är också känd som "Semi-Reducer". Det spelar en viktig roll för att minska överbelastningen på nätet. MapReduce-ramverket tillhandahåller funktionen för att definiera Combiner, som kombinerar den mellanliggande utdata från Mappers innan de skickas till Reducer.
Aggregeringen av Mapper-utdata innan den överförs till Reducer hjälper ramverket att blanda små mängder data, vilket leder till låg nätverksstockning.
Combinerns huvudfunktion är att sammanfatta utdata från Mappers med samma nyckel och skicka den till Reducer. Combiner-klassen används mellan Mapper-klassen och Reducer-klassen.
Datalokalitet i MapReduce
Datalokalitet hänvisar till "Flytta beräkning närmare data snarare än att flytta data till beräkningen." Det är mycket mer effektivt om beräkningen som begärs av applikationen exekveras på maskinen där den begärda informationen finns.
Detta är mycket sant i de fall där datastorleken är enorm. Det beror på att det minimerar nätverksstockningen och ökar systemets totala genomströmning.
Det enda antagandet bakom detta är att det är bättre att flytta beräkningen närmare maskinen där data finns i stället för att flytta data till maskinen där programmet körs.
Apache Hadoop arbetar på en enorm mängd data, så det är inte effektivt att flytta så enorma data över nätverket. Därför kom ramverket fram till den mest innovativa principen som är datalokalitet, som flyttar beräkningslogik till data istället för att flytta data till beräkningsalgoritmer. Detta kallas datalokalitet.
Fördelar med MapReduce
1. Skalbarhet: MapReduce-ramverket är mycket skalbart. Det gör det möjligt för organisationer att köra applikationer från stora uppsättningar maskiner, vilket kan involvera användningen av tusentals terabyte data.
2. Flexibilitet: MapReduce-ramverket ger organisationen flexibilitet att bearbeta data av alla storlekar och format, antingen strukturerad, semistrukturerad eller ostrukturerad.
3. Säkerhet och autentisering: MapReduce programmeringsmodell ger hög säkerhet. Det skyddar all obehörig åtkomst till data och förbättrar klustersäkerheten.
4. Kostnadseffektivt: Ramverket bearbetar data över klustret av råvaruhårdvara, som är billiga maskiner. Det är alltså mycket kostnadseffektivt.
5. Snabbt: MapReduce bearbetar data parallellt, vilket gör det mycket snabbt. Det tar bara några minuter att bearbeta terabyte med data.
6. En enkel modell för programmering: MapReduce-programmen kan skrivas på vilket språk som helst som Java, Python, Perl, R, etc. Så vem som helst kan enkelt lära sig och skriva MapReduce-program och möta deras behov av databehandling.
Användning av MapReduce
1. Logganalys: MapReduce används huvudsakligen för att analysera loggfiler. Ramverket delar upp de stora loggfilerna i splittringen och en kartläggningssökning efter de olika webbsidorna som öppnades.
Varje gång när en webbsida hittas i loggen skickas ett nyckel-värdepar till reduceraren där nyckeln är webbsidan och värdet är "1". Efter att ha sänt ett nyckel-värdepar till Reducer, aggregerar Reducerarna antalet för vissa webbsidor.
Det slutliga resultatet blir det totala antalet träffar för varje webbsida.
2. Fulltextindexering: MapReduce används också för att utföra fulltextindexering. Kartläggaren i MapReduce kommer att mappa varje fras eller ord i ett dokument till dokumentet. Reduceraren kommer att skriva dessa mappningar till ett index.
3. Google använder MapReduce för att beräkna deras Pagerank.
4. Omvänd webblänksgraf: MapReduce används också i Reverse Web-Link GRAph. Kartfunktionen matar ut URL-målet och källan, med input från webbsidan (källa).
Reduceringsfunktionen sammanfogar sedan listan över alla källadresser som är associerade med den givna måladressen och den returnerar målet och listan med källor.
5. Antal ord i ett dokument: MapReduce-ramverket kan användas för att räkna antalet gånger ordet förekommer i ett dokument.
Sammanfattning
Det här handlar om Hadoop MapReduce Tutorial. Ramverket bearbetar enorma mängder data parallellt över klustret av råvaruhårdvara. Den delar upp jobbet i oberoende uppgifter och utför dem parallellt på olika noder i klustret.
MapReduce övervinner flaskhalsen i det traditionella företagssystemet. Ramverket fungerar på nyckeln, värdepar. Användaren definierar de två funktionerna som är kartfunktion och reduceringsfunktion.
Affärslogiken läggs in i kartfunktionen. Artikeln hade förklarat olika avancerade koncept för MapReduce-ramverket.