Eftersom vi ser i dagens värld att de flesta byter till MongoDB, finns det fortfarande många som föredrar att använda en traditionell relationsdatabas. Här kommer vi att diskutera varför MongoDB ska vi välja? Som varje mynt har två ansikten, har det sina fördelar och begränsningar.
Så, är du redo att utforska anledningarna till att lära dig MongoDB?
Varför MongoDB?
Eftersom det är en NoSQL-databas, det är därför den har många anledningar att lära sig MongoDB. Dessa skäl har lett grunden till MongoDBs världsomspännande popularitet.
Det här är några anledningar till varför MongoDB är populärt.
- Aggregationsram
- BSON-format
- Skärning
- Ad-hoc-fråga
- Begränsad samling
- Indexering
- Fillagring
- Replikering
- MongoDB Management Service (MMS)

De bästa skälen att lära sig MongoDB
i) Aggregationsram
Vi kan använda det på ett mycket effektivt sätt av MongoDB. MapReduce kan användas för batchbehandling av data och även för aggregeringsoperationer. MapReduce är inget annat än en process, där stora datamängder kommer att bearbeta och generera resultat med hjälp av parallella och distribuerade algoritmer på kluster.
Den består av två uppsättningar operationer i sig, de är:Map() och Reduce().
- Map(): Den utför operationer som att filtrera data och sedan utföra sortering på den datamängden.
- Reduce(): Den utför operationen att sammanfatta all data efter map()-operationen.
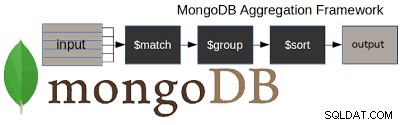
Aggregationsram
ii) BSON-format
Det är ett JSON-liknande lagringsformat. BSON står för Binary JSON . BSON är binärkodad serialisering av JSON som dokument och MongoDB använder det när man ska lagra dokument i samlingar. Vi kan lägga till datatyper som datum och binär (JSON stöder inte).
BSON-format använder _id som primärnyckel här. Som sagt att _id används som en primärnyckel så det har ett unikt värde kopplat till sig själv som kallas ObjectId, som antingen genereras av applikationsdrivrutinen eller MongoDB-tjänsten.
Nedan är ett exempel för att förstå BSON-formatet på ett bättre sätt:
Exempel-
{
"_id": ObjectId("12e6789f4b01d67d71da3211"),
"title": "Key features Of MongoDB",
"comments": [
...
]
} En annan fördel med att använda BSON-format är att det gör det möjligt att internt indexera och kartlägga dokumentegenskaper. Eftersom den är designad för att vara mer effektiv i storlek och hastighet, ökar den läs/skrivkapaciteten för MongoDB.
iii. Sharding
Det största problemet med alla webb-/mobilapplikationer är skalning. För att övervinna detta har MongoDB lagt till skärningsfunktion. Det är en metod där data distribueras över flera maskiner. Horisontell skalbarhet tillhandahålls med skärningen.
Det är en komplicerad process och görs med hjälp av flera skärvor. Varje skärva innehåller en del av data och fungerar som en separat databas . Att slå samman alla skärvor bildar en enda logisk databas. Åtgärder här borta utförs av frågeroutrar.
iv. Ad hoc-frågor
MongoDB stöder intervallfråga, reguljära uttryck och många fler typer av sökningar. Frågor inkluderar användardefinierade Javascript-funktioner och det kan också returnera specifika fält från dokumenten. MongoDB kan stödja ad hoc-frågor genom att använda ett unikt frågespråk eller genom att indexera BSON-dokument.
Låt oss se skillnaden mellan SQL SELECT-fråga och en liknande fråga:
T.ex. Hämtar alla poster i elevtabellen med elevnamn som ABC.
- SQL-uttalande – SELECT * FROM Students WHERE stud_name LIKE '%ABC%';
- MongoDB-fråga – db.Students.find({stud_name:/ABC/ });
v. Schema-Mindre
Eftersom det är en schemalös databas (skriven i C++), är den mycket mer flexibel än den traditionella databasen. På grund av detta kräver inte data mycket att ställa in för sig själv och minskad friktion med OOP. Om du vill spara ett objekt, serialisera det bara till JSON och skicka det till MongoDB.
vi. Begränsade samlingar
MongoDB stöder begränsad samling, eftersom den har fast storlek på samlingar i det. Den upprätthåller insättningsordningen. När gränsen är nådd börjar den bete sig som en cirkulär kö.
Exempel – Begränsning av vår begränsade samling till 2 MB
- db.createCollection('logs', {capped:true, size:2097152})
viii. Indexering
För att förbättra prestanda för sökningar skapas index . Vi kan indexera vilket fält som helst i MongoDB-dokument, antingen primärt eller sekundärt.
På grund av denna anledning kan databasmotorn effektivt lösa frågor.
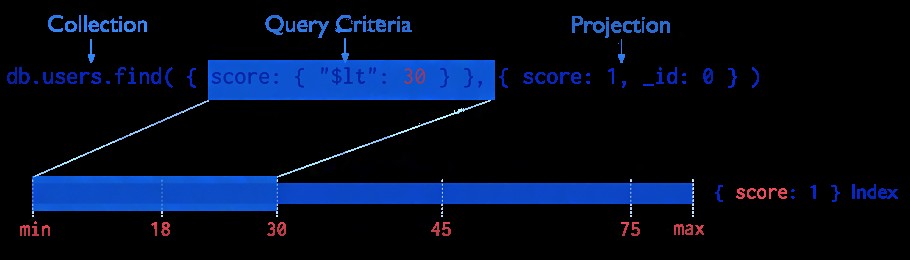
Indexering
viii. Fillagring
MongoDB kan också användas som ett fillagringssystem, vilket undviker belastningsobalans och även datareplikering. Denna funktion utförs med hjälp av Grid File System , den ingår i drivrutiner som lagrar filer.

Fillagring i MongoDB
ix. Replikering
Replikering tillhandahålls genom att data distribueras över olika maskiner. Den kan ha en primär nod och mer än en sekundär nod i sig (replika uppsättning).
Denna uppsättning fungerar som en mästare-slav. Här kan en master utföra läsning och skrivning och en slav kopierar data från en master som backup endast för en läsoperation.
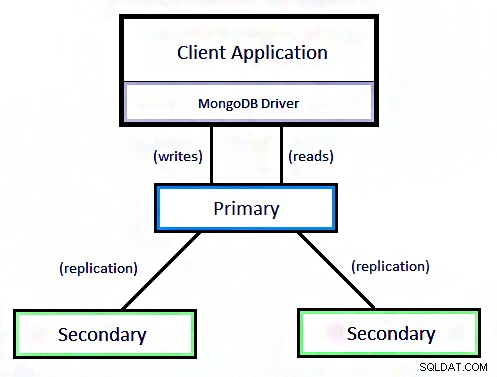
Replikering
x. MongoDB Management Service (MMS)
MongoDB har en mycket kraftfull funktion av MMS, på grund av vilken vi kan spåra våra databaser eller maskiner och vid behov kan säkerhetskopiera våra data. Den spårar också hårdvarumått för att hantera distributionen.
Det ger en funktion för anpassad varning, på grund av vilken vi kan upptäcka problem innan vår MongoDB-instans kommer att påverka.
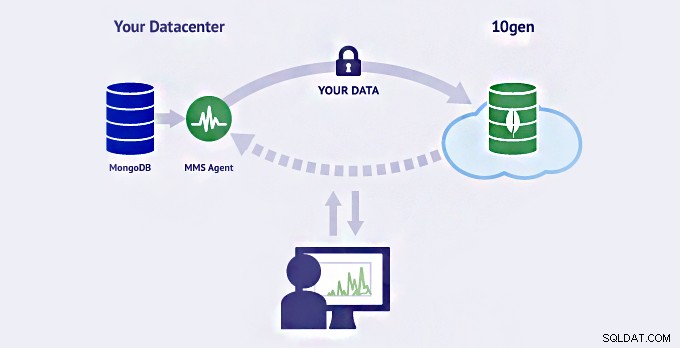
MongoDB Management Service (MMS)
Fördelar med MongoDB
Detta är denandra fasen av Why MongoDB, fördelar.
i. Lastbalansering
Om du har en stor uppsättning data som du behöver bearbeta kan du fördela trafiken mellan olika maskiner med hjälp av lastbalansering.
Det hjälper användaren på ett sätt så att du kan fortsätta ditt arbete även om någon av noderna/maskinerna har slutat fungera på grund av någon anledning. De andra noderna kommer att hålla arbetet i en fortsättning och din bearbetning kommer inte att sluta.
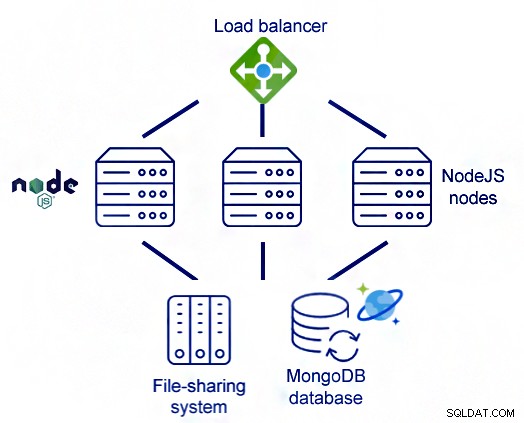
Lastbalansering
ii. Sharding
Med hjälp av skärning kan vi göra horisontell skalning. Vilket inte är möjligt med hjälp av en relationsdatabas. Genom att använda denna metod kan vi distribuera data över olika maskiner.
Vi gör skärvor av den data som vi har med oss själva och sedan försöker vi göra bearbetningsuppgiften lite lätt.
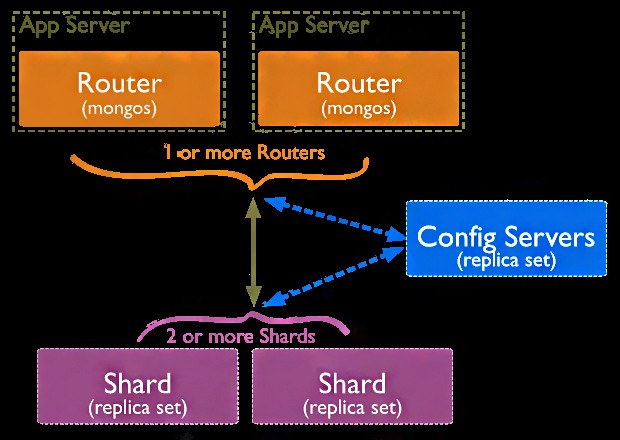
Sharding i MongoDB
iii. Flexibilitet
Det kräver inte datastrukturer som är enhetliga till sin natur över alla objekt som används. Detta gör det lättare att använda MongoDB. Med hjälp av dynamiskt schema är det väldigt enkelt att använda MongoDB.

Flexibilitet
iv. Hastighet
MongoDB kan snabbt och enkelt bearbeta data. Men detta är giltigt tills dina uppgifter är i dokumentformat. Vi kan säga att hastigheten automatiskt ökar eftersom den hanterar en stor mängd ostrukturerad data inom några sekunder, vilket känns som magi.
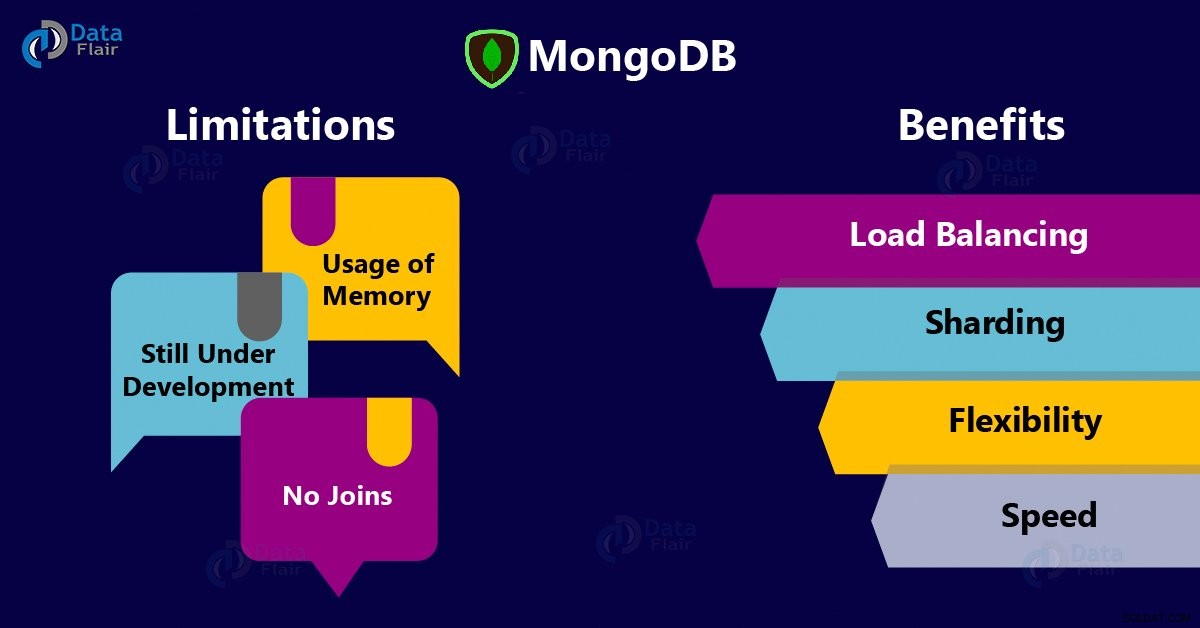
MongoDB Fördelar och nackdelar
Nackdelar/begränsningar med MongoDB
Detta är dentredje fasen av Why MongoDB , begränsningar.
i. Användning av minne
Eftersom vi vet att MongoDB lagrar nyckelnamnet tillsammans med varje dokument så är det uppenbart att det kommer att förbruka en stor mängd minne. Och eftersom joins inte heller är möjliga så blir det väldigt svårt att arbeta med dubbletter av data.
Användning av minne
ii. Inga anslutningar
Eftersom vi väldigt enkelt applicerar joins i relationsdatabasen väldigt enkelt går det inte att applicera joins i MongoDB. Så om du vill använda joins i det måste du skriva många komplexa frågor för att utföra joinoperationen här.
iii. Fortfarande under utveckling
SQL utvecklades på 1980-talet och MongoDB uppstod precis 2009. Så på grund av detta är MongoDB ännu inte helt dokumenterad eller testad och har inte totalt stöd från experterna på det.
Sammanfattning
Så efter att ha läst den kan du få en uppfattning om varför vi ska använda den, vilka är dess fördelar och nackdelar. Dessutom, om du har några frågor, fråga gärna i kommentarsfältet nedan, vi skulle gärna hjälpa dig.