I den här Hadoop självstudien , kommer vi att ge dig en komplett introduktion till MapReduce Key Value Pair.
Först och främst kommer vi att diskutera vad som är ett nyckelvärdespar i Hadoop, hur nyckelvärdespar genereras i MapReduce. Till sist kommer vi att förklara MapReduce generering av nyckelvärdespar med exempel.
Vad är Key Value Pair i Hadoop?
Nyckel-värdepar i MapReduce är postentiteten som Hadoop MapReduce accepterar för exekvering.
Vi använder Hadoop främst för dataanalys. Det handlar om strukturerad, ostrukturerad och semistrukturerad data. Med Hadoop, om schemat är statiskt, kan vi direkt arbeta på kolumnen istället för nyckelvärdet. Men om schemat inte är statiskt kommer vi att arbeta på ett nyckelvärde.
Nyckelvärde är inte datas inneboende egenskaper. Men de väljs genom att användaren analyserar data.
MapReduce är kärnkomponenten i Hadoop, som tillhandahåller databehandling. Den utför bearbetning genom att dela upp jobbet i två faser:Kartfas och Reducera fas . Varje fas har nyckel-värde som input och output.
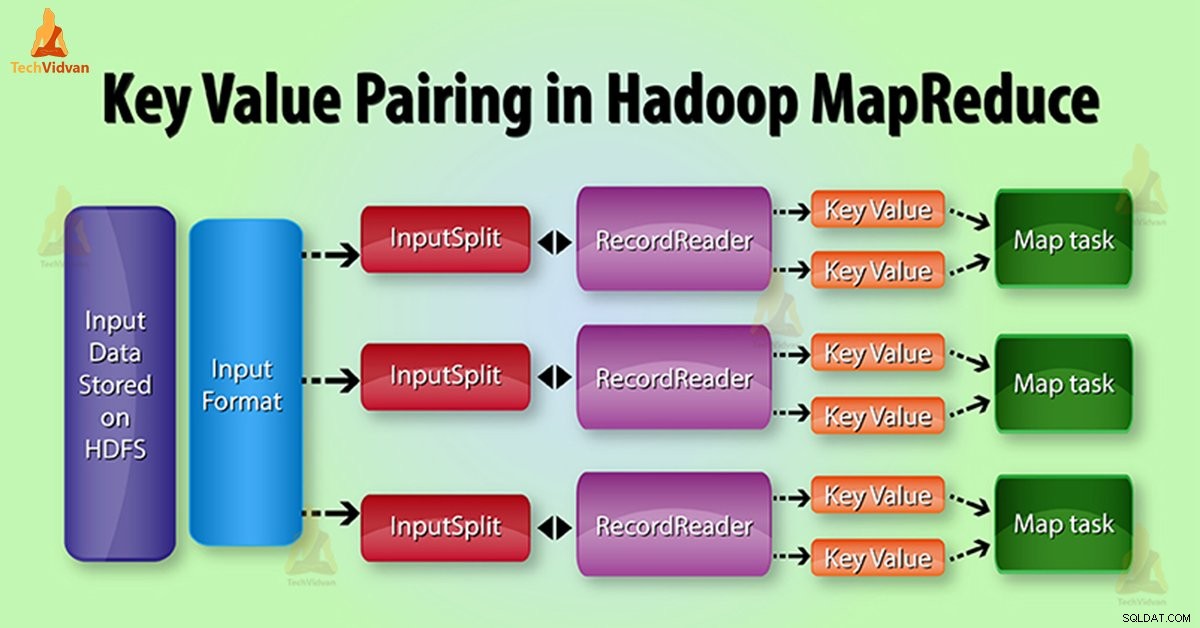
MapReduce Generering av nyckelvärdespar i Hadoop
I MapReduce jobbkörning, innan du skickar data till kartläggningen , konvertera det först till nyckel-värdepar. Eftersom mappar endast nyckel-värde par av data.
Nyckel-värdepar i MapReduce genereras enligt följande:
InputSplit – Det är den logiska representationen av data som InputFormat genererar. I programmet MapReduce beskriver det en arbetsenhet som innehåller en enda kartuppgift.
RecordReader – Den kommunicerar med InputSplit. Efter det konverterar den data till nyckelvärdespar som är lämpliga för läsning av Mapper. RecordReader använder som standard TextInputFormat för att konvertera data till nyckelvärdespar.
I MapReduce-jobbkörning bearbetar kartfunktionen ett visst nyckel-värdepar. Avger sedan ett visst antal nyckel-värde-par. Funktionen Reducera bearbetar värdena grupperade med samma nyckel.
Sänder sedan ut ytterligare en uppsättning nyckel-värdepar som utdata. Kartutdatatyperna bör matcha indatatyperna för Reducera enligt nedan:
- Karta: (K1, V1) -> lista (K2, V2)
- Minska: {(K2, lista (V2}) -> lista (K3, V3)
På vilken grund genereras ett nyckel-värdepar i Hadoop?
MapReduce Generering av nyckel-värdepar beror helt på datamängden. Beror också på önskad utgång. Framework specificerar nyckel-värdepar på fyra platser:Kartinmatning/utdata, Minska input/utdata.
1. Kartinmatning
Kartinmatning som standard tar linjeförskjutningen som nyckel. Innehållet i raden är värde som text. Vi kan modifiera dem; genom att använda det anpassade inmatningsformatet.
2. Kartutgång
Kartan ansvarar för att filtrera data. Det tillhandahåller också miljön för att gruppera data på basis av nyckel.
- Nyckel– Det är fält/text/objekt som data grupperar och aggregerar på reduceraren .
- Värde – Det är fältet/texten/objektet som varje individ reducerar metodhandtag.
3. Minska indata
Kartutdata matas in för att minska. Så det är samma som Map-Output.
4. Minska uteffekten
Det beror helt på vilken utmatning som krävs.
Exempel på MapReduce nyckel-värdepar
Till exempel innehållet i filen som HDFS butiker är Chandler är Joey Mark är John . Så, nu genom att använda InputFormat, kommer vi att definiera hur den här filen ska delas och läsas. Som standard använder RecordReader TextInputFormat för att konvertera den här filen till ett nyckel-värdepar.
- Nyckel – Den är förskjuten från början av raden i filen.
- Värde – Det är innehållet i raden, exklusive linjeavslutare.
Här,knapp är 0 och Värde är Chandler är Joey Mark är John.
Slutsats
Sammanfattningsvis kan vi säga att nyckel-värde bara är en rekordenhet som MapReduce accepterar för exekvering. InputSplit och RecordReader genererar nyckel-värdepar. Därför är nyckeln byte offset och värdet är innehållet i raden.
Hoppas ni gillade den här bloggen. Om du har några förslag eller frågor relaterade till MapReduce nyckelvärdespar så vänligen lämna en kommentar i ett avsnitt nedan.