I dennaHadoop-handledning , kommer vi att ge dig en komplett introduktion av HDFS Federation. I den här handledningen kommer vi att diskutera HDFS-arkitektur, begränsningar för den nuvarande arkitekturen för HDFS.
Sedan kommer vi att täcka HDFS Federation-arkitekturen i detalj tillsammans med deras fördelar i Hadoop-ramverket.
Vad är HDFS Federation?
Federation förbättrar en befintlig Hadoop HDFS arkitektur. Tidigare HDFS-arkitektur tillåter ett enda namnutrymme för hela klustret. I den arkitekturen hanterar en enda NameNode namnutrymmet.
Om NameNode misslyckas, kommer hela klustret att vara ur drift. Och klustret kommer att vara otillgängligt tills NameNode startar om eller tas med på en separat dator.
HDFS Federation introducerades för att övervinna denna begränsning. Det övervinner detta genom att lägga till stöd för många NameNode/Namespaces till HDFS.
Aktuell HDFS-arkitektur
HDFS har två huvudlager som anges nedan:
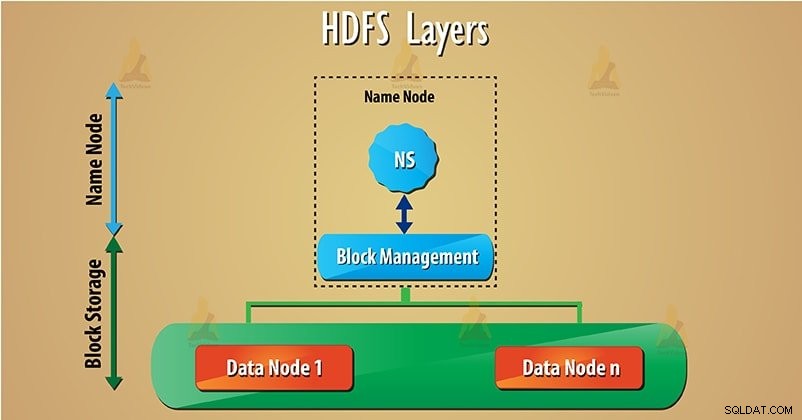
a) Namnutrymme – Det här lagret hanterar filer, kataloger och block . Det här lagret stöder grundläggande filsystemfunktioner som att skapa, radera filer.
b) Blockera lagring – Den har två delar-
- Blockhantering – Det stöder blockrelaterad operation såsom skapande, radering av blocken. Den hanterar datanoder i klustret och tar hand om replikeringshantering.
- Fysisk lagring – Detta lagrar blocken på det lokala filsystemet och ger tillgång till läs- eller skrivoperationer. Följ den här länken för att lära dig hur HDFS-data läser och skriver.
Denna nuvarande HDFS fungerar bra för mindre inställningar. Men för stora organisationer där vi behöver ta hand om den enorma mängden data har en viss begränsning. Hadoop federation hanterar dessa begränsningar.
Begränsning av nuvarande HDFS-arkitektur
Begränsning av nuvarande HDFS-arkitektur anges nedan:
1. Tätt kopplat blocklagring och namnutrymme
Namnområdeslager och lagringslager är tätt sammankopplade. Det gör alternativ implementering av namnnoden svår. Och det begränsar andra tjänster att använda blocklagring.
2. Skalbarhet för namnutrymme
Namnutrymmet är inte skalbart som datanode. Skalning i HDFS-kluster sker horisontellt genom att lägga till datanoder. Men vi kan inte lägga till mer namnutrymme till ett befintligt kluster. Vi kan skala namnutrymmet vertikalt på en enda namnnod.
3. Prestanda
Hadoops hela prestanda beror på genomströmningen av namnnoden. En operation av nuvarande filsystem beror på genomströmningen av en enda namnnod. NameNode stöder för närvarande 60 000 samtidiga uppgifter.
Kommande MapReduce kommer att ha stöd för mer än 1 00 000 samtidiga uppgifter. Och detta kommer att behöva mer namnnod.
4. Isolering
Det finns ingen separation av namnområdet. Så det finns ingen isolering bland hyresgästorganisationer som använder klustret.
HDFS Federation Architecture
Federation använder många oberoende Namenode/namnutrymmen för att skala namntjänsten horisontellt. I HDFS Federation Architecture, längst ner, finns datanoder. Och datanoder används som en gemensam lagring för block av alla namnnoder.
Varje datanod registreras med alla namnnoder i klustret. Dessa datanoder skickar periodiska hjärtslag, blockerar, rapporterar och hanterar kommandon från namnnoderna.
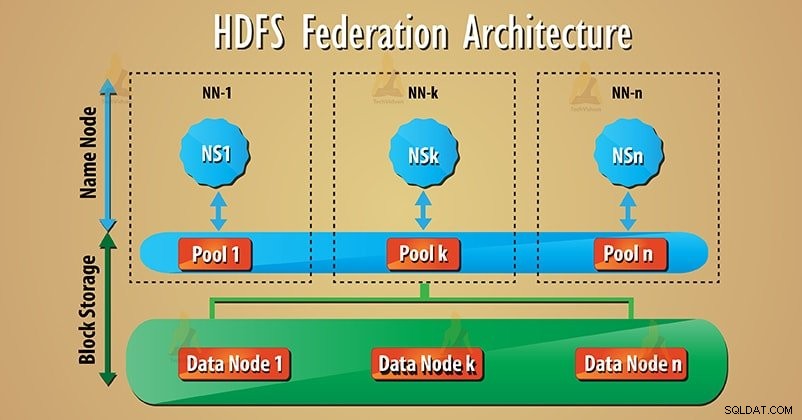
Många namnnoder (NN1, NN2…, NNn) hanterar många namnområden (NS1, NS2…, NSn) respektive. Varje namnområde har sin egen blockpool (NS1 har pool 1 och så vidare). Block från pool 1 lagras på datanod 1 och så vidare.
1. Blockera pool
Uppsättningen block är Blockpool som tillhör ett enda namnområde. Det finns en samling pooler i HDFS federationsarkitektur. Och varje block hanteras från det andra.
Detta gör att ett namnområde kan skapa ett block-ID för nya block utan samordning med ett annat namnområde. Alla datanoder lagrar datablock som finns i alla blockpooler.
2. Namnutrymmesvolym
Namnutrymmet tillsammans med dess blockpool är Namnutrymmesvolym . Många namnutrymmesvolymer finns i HDFS-federationen. Därför fungerar varje namnområdesvolym oberoende. När vi tar bort namnnod eller namnområde, kommer motsvarande blockpool som finns på datanoderna också att tas bort.
Fördelar med HDFS Federation
HDFS Federation övervinner begränsningarna hos tidigare HDFS-arkitektur. Därför ger den:
- Isolering – Det finns ingen isolering i en enda namnnod i en miljö med flera användare. I HDFS-federation kan olika kategorier av applikationer och användare isoleras till olika namnområden genom att använda många namnnoder.
- Skalbarhet för namnutrymme – I federation skalar många namnnoder upp horisontellt i filsystemets namnutrymme.
- Prestanda – Vi kan förbättra genomströmningen av läs/skrivdrift genom att lägga till fler namnnoder.
Slutsats
Sammanfattningsvis till HDFS Federation kan vi säga att den övervinner begränsningen av HDFS-arkitektur för en nod. I tidigare HDFS-arkitektur för ett helt kluster tillåter endast ett enda namnutrymme. Medan Federation använder många oberoende Namenode/namnutrymmen för att skala namntjänsten horisontellt.
Det separerar också namnutrymmeslagret och lagringen lager. Ger därför isolering, skalbarhet och enkel design.
Om du har några frågor eller förslag relaterade till förbundet i Hadoop HDFS, så låt oss veta det genom att lämna en kommentar.