Databassystem är avgörande komponenter i cykeln för alla framgångsrika applikationer. Varje organisation som involverar dem har därför mandatet att säkerställa smidig prestanda för dessa DBM:er genom konsekvent övervakning och hantering av mindre bakslag innan de eskalerar till enorma komplikationer som kan resultera i programstopp eller långsam prestanda.
Du kanske frågar hur kan du avgöra om databasen verkligen kommer att få problem medan den fungerar normalt? Tja, det är vad vi ska diskutera i den här artikeln och vi kallar det benchmarking. Benchmarking är i princip att köra en uppsättning frågor med vissa testdata tillsammans med en viss resursförsörjning för att avgöra om dessa parametrar uppfyller den förväntade prestandanivån.
MongoDB har ingen standard benchmarking-metodik och därför måste vi lösa i testfrågor på egen hårdvara. Så mycket som du också kan få imponerande siffror från benchmarkprocessen, måste du vara försiktig eftersom detta kan vara ett annat fall när du kör din databas med riktiga frågor.
Tanken bakom benchmarking är att få en allmän uppfattning om hur olika konfigurationsalternativ påverkar prestanda, hur du kan justera några av dessa konfigurationer för att få maximal prestanda och uppskatta kostnaden för att förbättra denna implementering. Dessutom växer applikationer med tiden i termer av användare och förmodligen behöver mängden data som ska serveras göra en viss kapacitetsplanering innan denna tidpunkt. Efter att ha insett en stigande datatrend måste du göra några benchmarking om hur du kommer att möta kraven för denna enormt växande data.
Överväganden vid benchmarking MongoDB
- Välj arbetsbelastningar som är en typisk representation av dagens moderna applikationer. Moderna applikationer blir mer komplexa för varje dag som går och detta överförs ner till datastrukturerna. Det vill säga, datapresentationen har också förändrats med tiden, till exempel lagring av enkla fält till objekt och arrayer. Det är inte helt lätt att arbeta med dessa data med standard- eller snarare undermåliga databaskonfigurationer eftersom det kan eskalera till problem som dålig latens och dålig genomströmningsoperationer som involverar komplexa data. När du kör ett benchmark bör du därför använda data som är en tydlig presentation av din applikation.
- Dubbelkolla på skrivningar. Se alltid till att all dataskrivning gjordes på ett sätt som inte tillät någon dataförlust. Detta för att förbättra dataintegriteten genom att säkerställa att data är konsekventa och är mest tillämpliga, särskilt i produktionsmiljön.
- Använd datavolymer som är en representation av "big data"-datauppsättningar som säkerligen kommer att överskrida RAM-kapaciteten för en enskild nod. När testarbetsbelastningen är stor, kommer det att hjälpa dig att förutsäga framtida förväntningar på din databasprestanda och därför påbörja en viss kapacitetsplanering tidigt nog.
Metodik
Vårt benchmarktest kommer att involvera en del stor platsdata som kan laddas ner härifrån och vi kommer att använda Robo3t-mjukvaran för att manipulera vår data och samla in den information vi behöver. Filen har mer än 500 dokument vilket är tillräckligt för vårt test. Vi använder MongoDB version 4.0 på en Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore 3.4GHz dedikerad server med 32GB RAM, Western Digital WD Caviar RE4 1TB snurrande disk och Smart XceedIOPS 256GB SSD. Vi infogade de första 500 dokumenten.
Vi körde infogningskommandona nedan
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Skriv oro
Skrivproblem beskriver bekräftelsenivå som begärs från MongoDB för skrivoperationer i detta fall till en fristående MongoDB. För en operation med hög genomströmning, om detta värde är satt till lågt, kommer skrivanropen att vara så snabba och därmed minska fördröjningen av begäran. Å andra sidan, om värdet ställs in högt, är skrivanropen långsamma och ökar följaktligen på frågefördröjningen. En enkel förklaring till detta är att när värdet är lågt så är du inte orolig för möjligheten att förlora några skrivningar i händelse av mongod-krasch, nätverksfel eller anonymt systemfel. En begränsning i det här fallet kommer att vara att du inte är säker på om dessa skrivningar lyckades. Å andra sidan, om skrivproblemet är högt, finns det en felhanteringsuppmaning och därmed kommer skrivningarna att kvitteras. En bekräftelse är helt enkelt ett kvitto på att servern accepterade skrivningen att bearbeta.
 När skrivproblemet är högt
När skrivproblemet är högt  När skrivproblemet är lågt
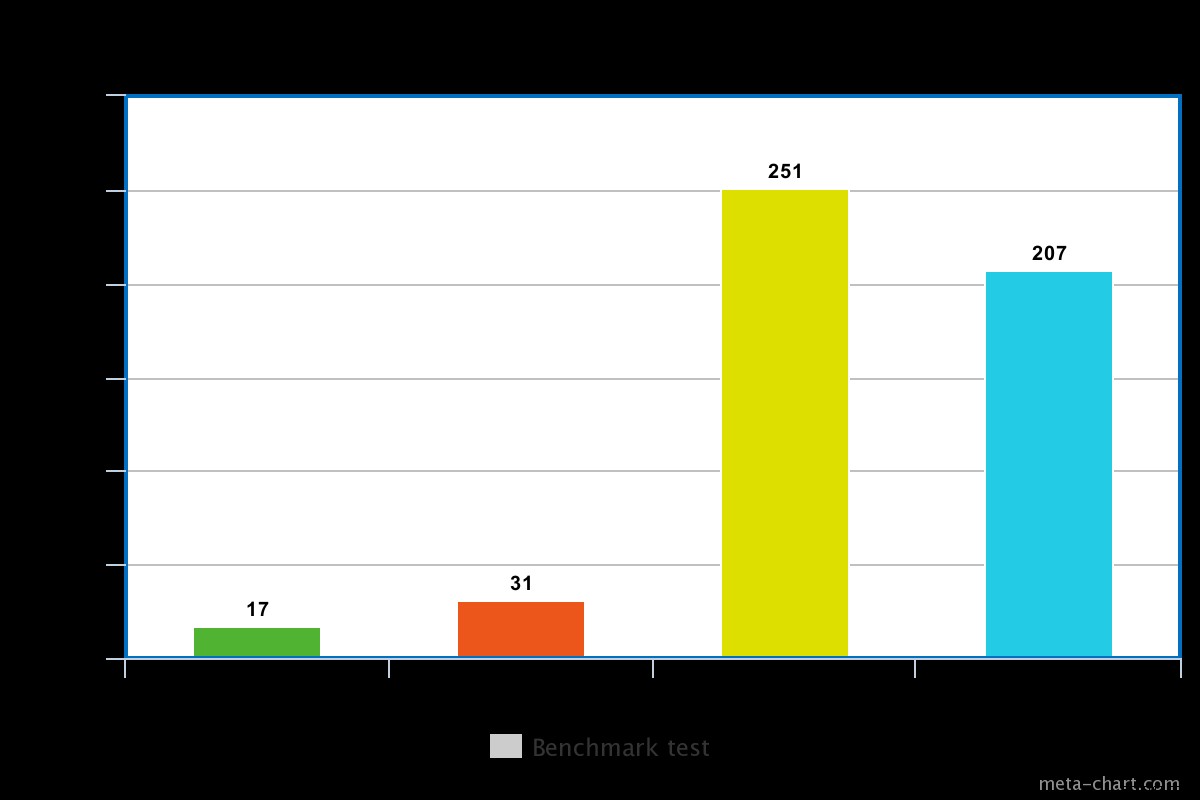
När skrivproblemet är lågt I vårt test resulterade skrivproblemet inställt på lågt till att frågan kördes i min på 0,013ms och max på 0,017ms. I det här fallet är den grundläggande skrivbekräftelsen inaktiverad men man kan fortfarande få information om socket-undantag och eventuella nätverksfel som kan ha utlösts.
När skrivproblemet är högt tar det nästan dubbelt så lång tid att återvända med exekveringstiden på 0,027 ms min och 0,031 ms max. Bekräftelsen i detta fall är garanterad men inte 100 % har den nått diskjournal. I det här fallet är risken för skrivförlust alltså 50 % på grund av 100ms-fönstret där journalen kanske inte spolas till disken.
Journalist
Detta är en teknik för att säkerställa ingen dataförlust genom att tillhandahålla hållbarhet i händelse av fel. Detta uppnås genom en skriv-förut-loggning till journalfiler på disken. Det är mest effektivt när skrivproblemet är högt inställt.
För en snurrande skiva är exekveringstiden med journalföring aktiverad lite hög, till exempel i vårt test var det cirka 0,251ms för samma operation ovan.

Exekveringstiden för en SSD är dock lite lägre för samma kommando. I vårt test var det cirka 0,207 ms, men beroende på vilken typ av data som helst kan detta ibland vara 3 gånger snabbare än en snurrande skiva.

När journalföring är aktiverat bekräftar det att skrivningar har gjorts till journalen och säkerställer därmed datahållbarhet. Följaktligen kommer skrivoperationen att överleva en mongod avstängning och säkerställer att skrivoperationen är hållbar.
För en operation med hög genomströmning kan du halva frågetider genom att ställa in w=0. Annars, om du behöver vara säker på att data har registrerats eller snarare kommer att vara i händelse av ett återupplivande efter fel, måste du ställa in w=1.
 Severalnines Bli en MongoDB DBA - Bringing MongoDB to ProductionLär dig om vad du behöver veta för att distribuera, övervaka, hantera och skala MongoDBLadda ner gratis
Severalnines Bli en MongoDB DBA - Bringing MongoDB to ProductionLär dig om vad du behöver veta för att distribuera, övervaka, hantera och skala MongoDBLadda ner gratis Replikering
Bekräftelse av ett skrivproblem kan aktiveras för mer än en nod som är den primära och en sekundär inom en replikuppsättning. Detta kommer att kännetecknas av vilket heltal som värderas till skrivparametern. Till exempel, om w =3, måste Mongod säkerställa att frågan får en bekräftelse från huvudnoden och 2 slavar. Om du försöker ställa in ett värde som är större än ett och noden ännu inte är replikerad, kommer det att ge ett felmeddelande om att värden måste replikeras.
Replikering kommer med en fördröjning så att exekveringstiden kommer att öka. För den enkla frågan ovan, om w=3, ökar den genomsnittliga exekveringstiden till 270ms. En drivande faktor för detta är intervallet i svarstid mellan noder som påverkas av nätverkslatens, kommunikationsoverhead mellan de tre noderna och överbelastning. Dessutom väntar alla tre noderna på att varandra ska slutföra innan resultatet returneras. I en produktionsinstallation behöver du därför inte involvera så många noder om du vill förbättra prestandan. MongoDB ansvarar för att välja vilka noder som ska kvitteras om det inte finns en specifikation i konfigurationsfilen med hjälp av taggar.
Snurrande disk vs Solid State-disk
Som nämnts ovan är SSD-disk ganska snabb än snurrande disk beroende på vilken data som är involverad. Ibland kan det vara 3 gånger snabbare och därför värt att betala för om det skulle behövas. Det kommer dock att bli dyrare att använda en SSD, särskilt när man hanterar stora data. MongoDB har förtjänsten att den stöder lagring av databaser i kataloger som kan monteras och därmed en chans att använda en SSD. Att använda en SSD och aktivera journalföring är en stor optimering.
Slutsats
Experimentet var säkert att inaktiverade skrivproblem resulterade i minskad exekveringstid för en fråga på bekostnad av risken för dataförlust. Å andra sidan, när skrivproblemet är aktiverat, är exekveringstiden nästan 2 gånger när den är inaktiverad men det finns en garanti för att data inte kommer att gå förlorade. Dessutom kan vi motivera att SSD är snabbare än en snurrande disk. Men för att säkerställa datahållbarhet i händelse av ett systemfel, är det lämpligt att aktivera skrivproblemet. När du aktiverar skrivproblemet för en replikuppsättning, ställ inte in numret för stort så att det kan leda till en viss försämrad prestanda från applikationsänden.