Denna Hadoop-handledning handlar om MapReduce Shuffling och Sortering. Här kommer vi att ge dig en detaljerad beskrivning av Hadoop-blandnings- och sorteringsfasen.
Först kommer vi att diskutera vad som är MapReduce Shuffling, därefter med MapReduce Sorting, sedan kommer vi att täcka MapReduces sekundära sorteringsfas i detalj.
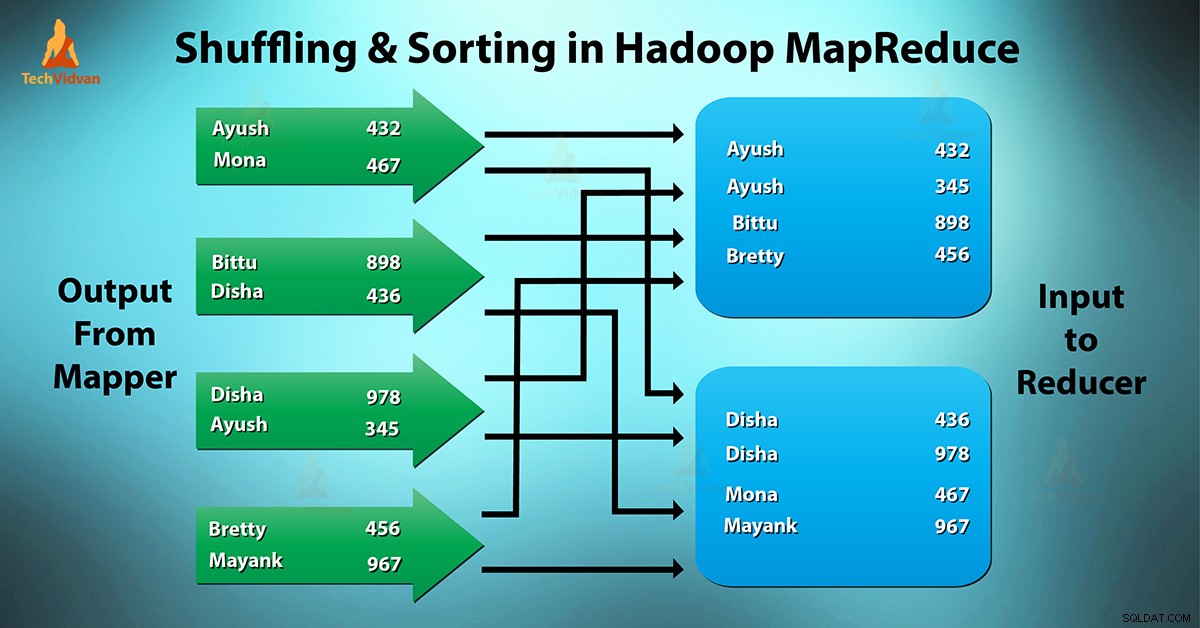
Vad är MapReduce blandning och sortering?
Blandar är den process genom vilken den överför mappers mellanutgång till reduceraren. Reducer får 1 eller flera nycklar och tillhörande värden på basis av reducerare.
Den mellanliggande nyckeln – värde som genereras av mapparen sorteras automatiskt efter nyckel. I Sortering sker fas sammanslagning och sortering av kartutdata.
Blandning och sortering i Hadoop sker samtidigt.
Blandar i MapReduce
Processen att överföra data från kartläggarna till reducerarna blandas. Det är också den process genom vilken systemet utför sorteringen. Sedan överför den kartutmatningen till reduceraren som ingång. Detta är anledningen till att blandningsfasen är nödvändig för reducerarna.
Annars skulle de inte ha någon input (eller input från varje mappare). Eftersom blandning kan starta redan innan kartfasen har avslutats. Så detta sparar lite tid och slutför uppgifterna på kortare tid.
Sortering i MapReduce
MapReduce Framework sorterar automatiskt nycklarna som genereras av mapparen. Alltså, innan du startar reduceraren, sorteras alla mellanliggande nyckel-värdepar efter nyckel och inte efter värde. Den sorterar inte värden som skickas till varje reducering. De kan vara i vilken ordning som helst.
Sortering i ett MapReduce-jobb hjälper reduceraren att enkelt särskilja när en ny reduceringsuppgift ska starta.
Detta sparar tid för reduceraren. Reducer i MapReduce startar en ny reduceringsuppgift när nästa nyckel i den sorterade indatan är annorlunda än den föregående. Varje reduceringsuppgift tar nyckelvärdepar som indata och genererar nyckel-värdepar som utdata.
Det viktiga att notera är att blandning och sortering i Hadoop MapReduce inte kommer att ske alls om du anger nollreducerare (setNumReduceTasks(0)).
Om reduceraren är noll, stannar MapReduce-jobbet vid kartfasen. Och kartfasen inkluderar inte någon form av sortering (även kartfasen är snabbare).
Sekundär sortering i MapReduce
Om vi vill sortera reduceringsvärden använder vi en sekundär sorteringsteknik. Denna teknik gör det möjligt för oss att sortera värdena (i stigande eller fallande ordning) som skickas till varje reducering.
Slutsats
Sammanfattningsvis sker MapReduce Shuffling och Sortering samtidigt för att sammanfatta Mappers mellanliggande utdata. Hadoop Shuffling-Sorting kommer inte att ske om du anger nollreducerare (setNumReduceTasks (0)).
Framework sorterar alla mellanliggande nyckel-värdepar efter nyckel, inte efter värde. Den använder sekundär sortering för att sortera efter värde. Om du har några förslag eller frågor relaterade till MapReduce Shuffling and Sorteringsfas, så lämna gärna en kommentar i en kommentarsruta.
Vi löser dem gärna.