Det har snart gått två månader sedan vi släppte SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM använder Prometheus som den underliggande metoden för att samla in tidsseriedata från exportörer som kör på databasinstanser och lastbalanserare. Den här bloggen visar dig hur du åtgärdar problem när Prometheus-exportörer inte körs, eller om diagrammen inte visar data eller visar "Inga datapunkter".
Vad är Prometheus?
Prometheus är ett övervakningssystem med öppen källkod med en dimensionell datamodell, flexibelt frågespråk, effektiv tidsseriedatabas och modernt varningssätt. Det är en övervakningsplattform som samlar in mätvärden från övervakade mål genom att skrapa mätvärden HTTP-slutpunkter på dessa mål. Den tillhandahåller dimensionsdata, kraftfulla frågor, fantastisk visualisering, effektiv lagring, enkel användning, exakta varningar, många klientbibliotek och många integrationer.
Prometheus i aktion för SCUMM Dashboards
Prometheus samlar in mätdata från exportörer, där varje exportör körs på en databas eller lastbalanseringsvärd. Diagrammet nedan visar hur dessa exportörer är länkade till servern som är värd för Prometheus-processen. Det visar att ClusterControl-noden har Prometheus igång där den också kör process_exporter och node_exporter.
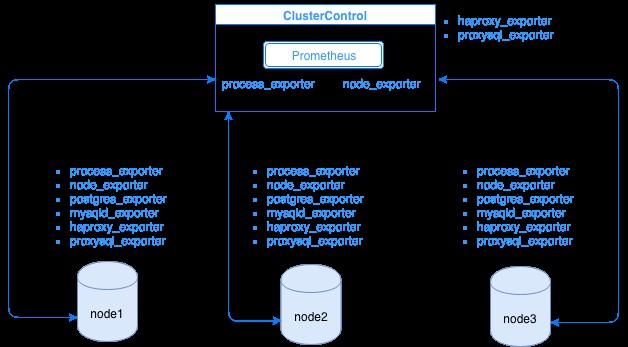
Diagrammet visar att Prometheus körs på ClusterControl-värden och exportörernas process_exporter och node_exporter körs också för att samla in mätvärden från sin egen nod. Alternativt kan du även göra din ClusterControl-värd som mål där du kan ställa in HAProxy eller ProxySQL.
För klusternoderna ovan (nod1, nod2 och nod3) kan den ha mysqld_exporter eller postgres_exporter igång som är de agenter som skrapar data internt i den noden och skickar den till Prometheus-servern och lagrar den i sin egen datalagring. Du kan hitta dess fysiska data via /var/lib/prometheus/data inom den värd där Prometheus är konfigurerad.
När du konfigurerar Prometheus, till exempel i ClusterControl-värden, bör den ha följande portar öppna. Se nedan:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusBaserat på utdata har jag även ProxySQL igång på värdtestccnoden där ClusterControl är värd.
Vanliga problem med SCUMM Dashboards som använder Prometheus
När Dashboards är aktiverade kommer ClusterControl att installera och distribuera binärfiler och exportörer som node_exporter, process_exporter, mysqld_exporter, postgres_exporter och daemon. Dessa är de vanliga uppsättningarna av paket till databasnoderna. När dessa är konfigurerade och installerade, startas följande demonkommandon och körs enligt nedan:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusFör en PostgreSQL-nod,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterDen har samma exportörer som för en MySQL-nod, men skiljer sig bara på postgres_exporter eftersom detta är en PostgreSQL-databasnod.
Men när en nod drabbas av ett strömavbrott, en systemkrasch eller en omstart av systemet, kommer dessa exportörer att sluta köra. Prometheus kommer att rapportera att en exportör är nere. ClusterControl tar prov på självaste Prometheus och frågar efter exportörstatus. Så den agerar på denna information och kommer att starta om exportören om den är nere.
Observera dock att för exportörer som inte har installerats via ClusterControl kommer de inte att startas om efter en krasch. Anledningen är att de inte övervakas av systemd eller en demon som fungerar som ett säkerhetsskript som skulle starta om en process vid krasch eller en onormal avstängning. Därför kommer skärmdumpen nedan att visa hur det ser ut när exportörerna inte är igång. Se nedan:
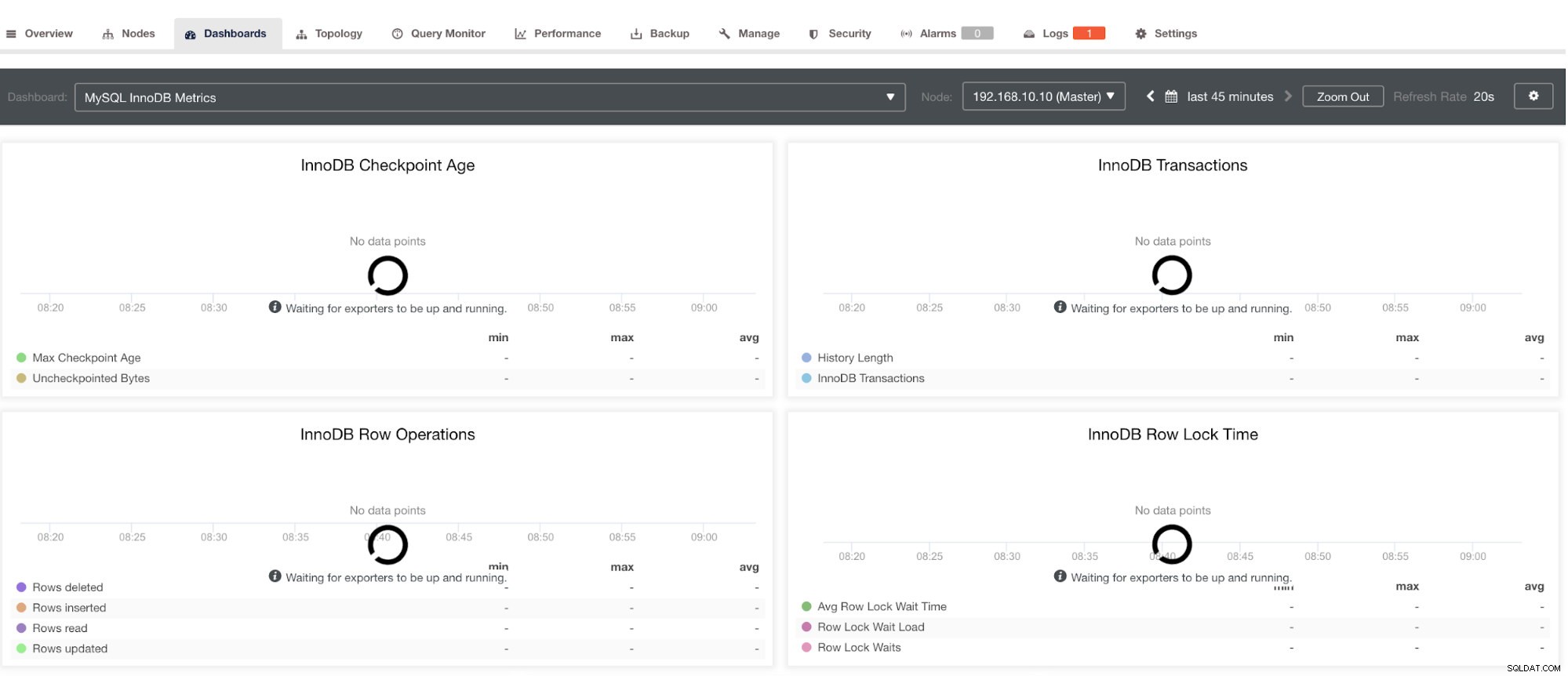
och i PostgreSQL Dashboard, kommer att ha samma laddningsikon med etiketten "Inga datapunkter" i grafen. Se nedan:
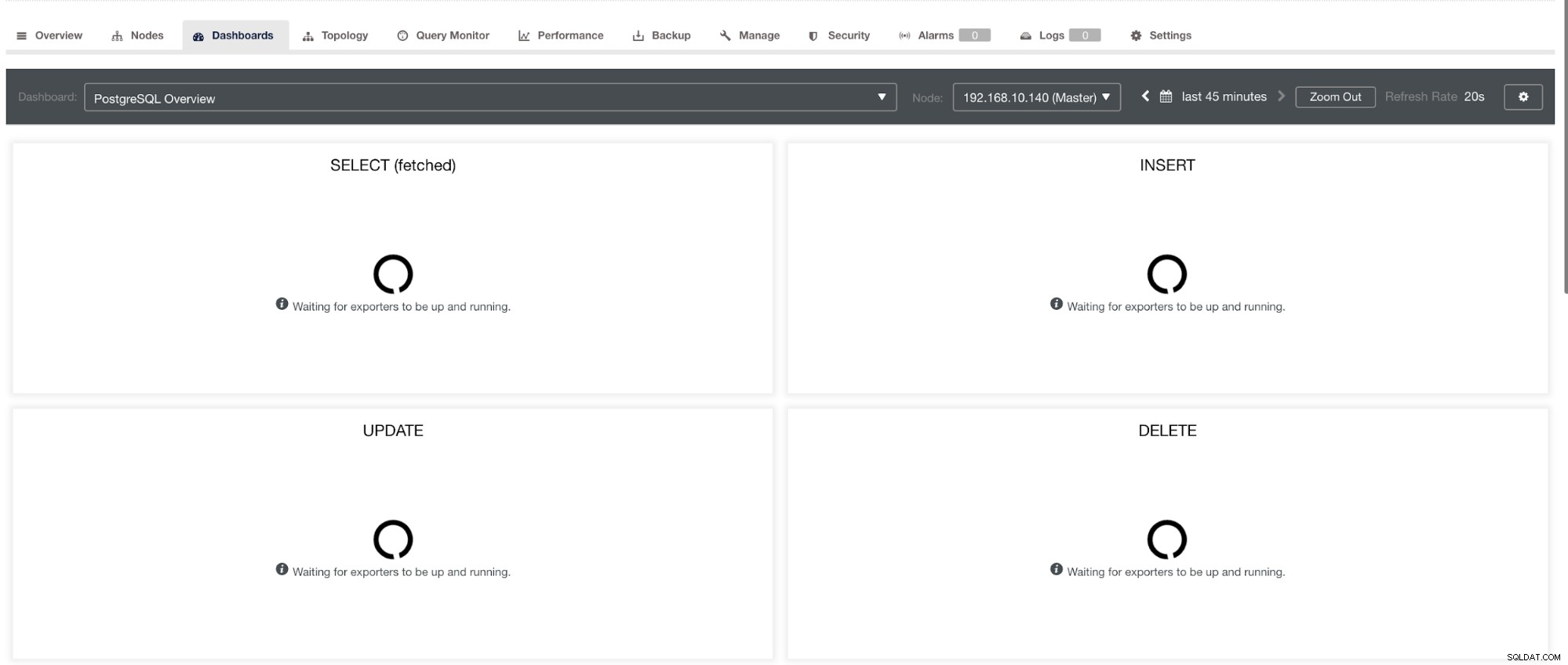
Därför kan dessa felsökas genom olika tekniker som kommer att följa i följande avsnitt.
Felsökning av problem med Prometheus
Prometheus-agenter, kända som exportörerna, använder följande portar:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) och den alldeles egna prometheus 909. bearbeta. Det här är portarna för dessa agenter som används av ClusterControl.
För att börja felsöka SCUMM Dashboard-problemen kan du börja med att kontrollera portarna öppna från databasnoden. Du kan följa listorna nedan:
-
Kontrollera om portarna är öppna
t.ex.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporDet kan finnas en möjlighet att portarna inte är öppna på grund av att en brandvägg (som iptables eller brandvägg) blockerar den från att öppna porten eller att själva processdemonen inte körs.
-
Använd curl från värdmonitorn och kontrollera om porten är tillgänglig och öppen.
t.ex.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Helst fann jag praktiskt taget det här tillvägagångssättet möjligt för mig eftersom jag lätt kan grep och felsöka från terminalen.
-
Varför inte använda webbgränssnittet?
-
Prometheus exponerar port 9090 som används av ClusterControl i våra SCUMM Dashboards. Bortsett från detta kan portarna som exportörerna exponerar också användas för att felsöka och bestämma de tillgängliga metriska namnen med hjälp av PromQL. På servern där Prometheus körs kan du besöka https://
:9090/targets . Skärmdumpen nedan visar hur det fungerar: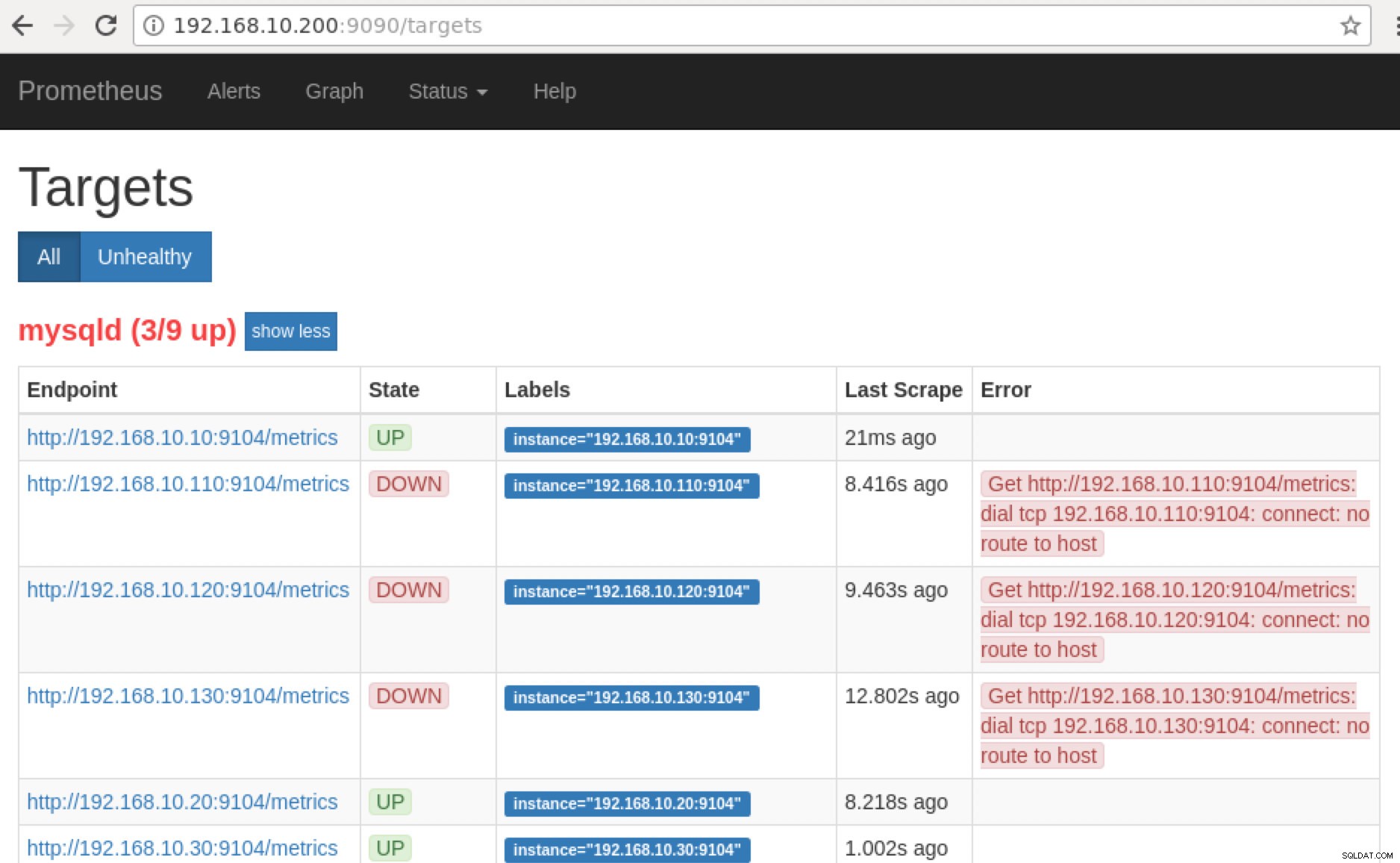
och genom att klicka på "Slutpunkter", kan du verifiera mätvärdena precis som på skärmdumpen nedan:
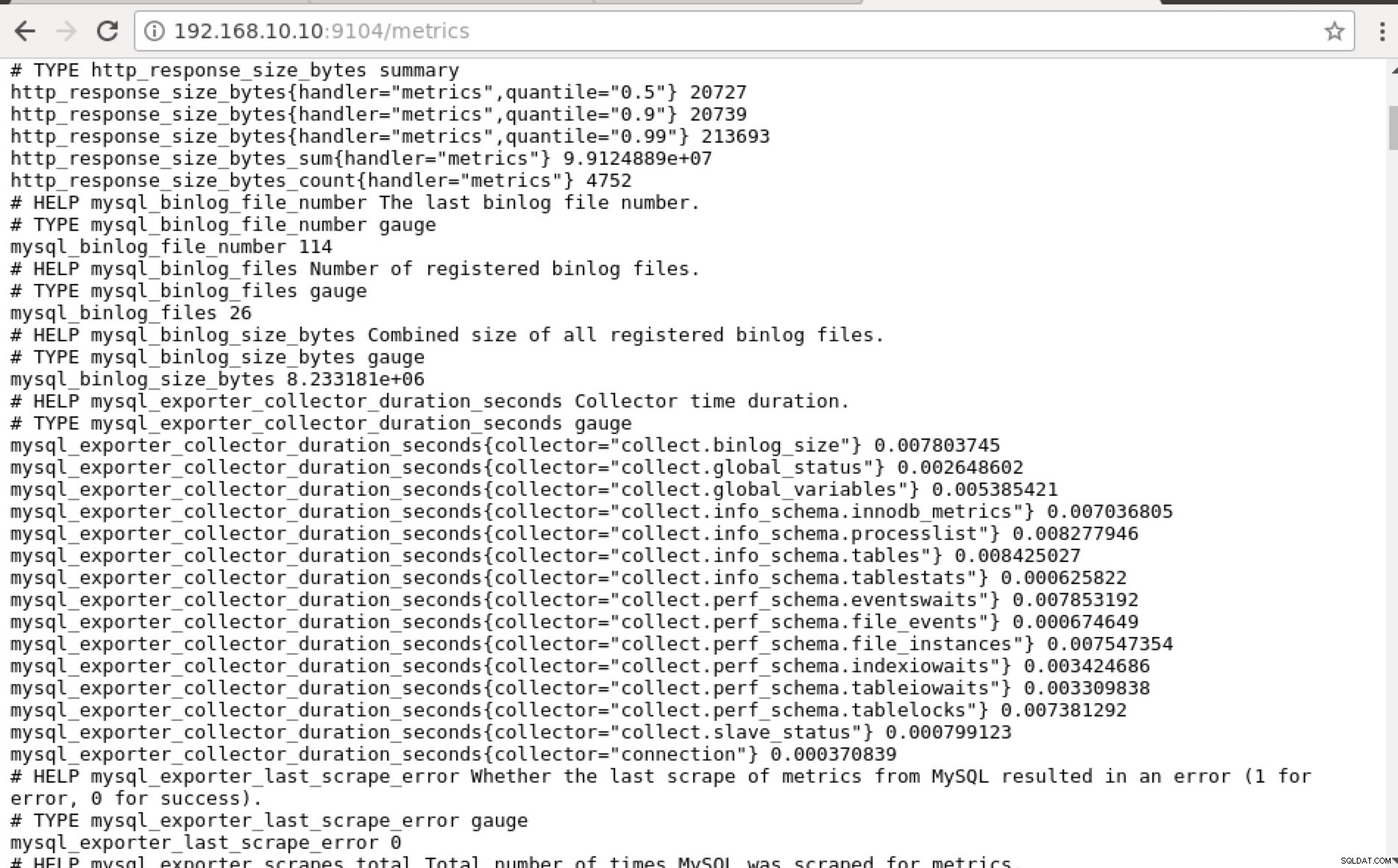
Istället för att använda IP-adressen kan du också kontrollera detta lokalt via localhost på den specifika noden, som att besöka https://localhost:9104/metrics antingen i ett webbgränssnitt eller med hjälp av cURL.
Om vi nu går tillbaka till "Mål ”-sidan kan du se listan över noder där det kan vara problem med porten. Anledningarna som kan orsaka detta är listade nedan:
- Servern är nere
- Nätverket går inte att nå eller portarna öppnas inte på grund av att en brandvägg körs
- Demonen körs inte där
_exporter är inte igång. Till exempel, mysqld_exporter körs inte.
-
När dessa exportörer körs kan du starta och köra processen med daemon kommando. Du kan referera till de tillgängliga processerna som jag hade använt i exemplet ovan, eller som nämns i föregående avsnitt av den här bloggen.
Vad sägs om graferna för "inga datapunkter" i min instrumentpanel?
SCUMM Dashboards kommer med ett allmänt användningsfallsscenario som vanligtvis används av MySQL. Det finns dock vissa variabler när anrop av sådan statistik kanske inte är tillgänglig i en viss MySQL-version eller en MySQL-leverantör, som MariaDB eller Percona Server.
Låt mig visa ett exempel nedan:
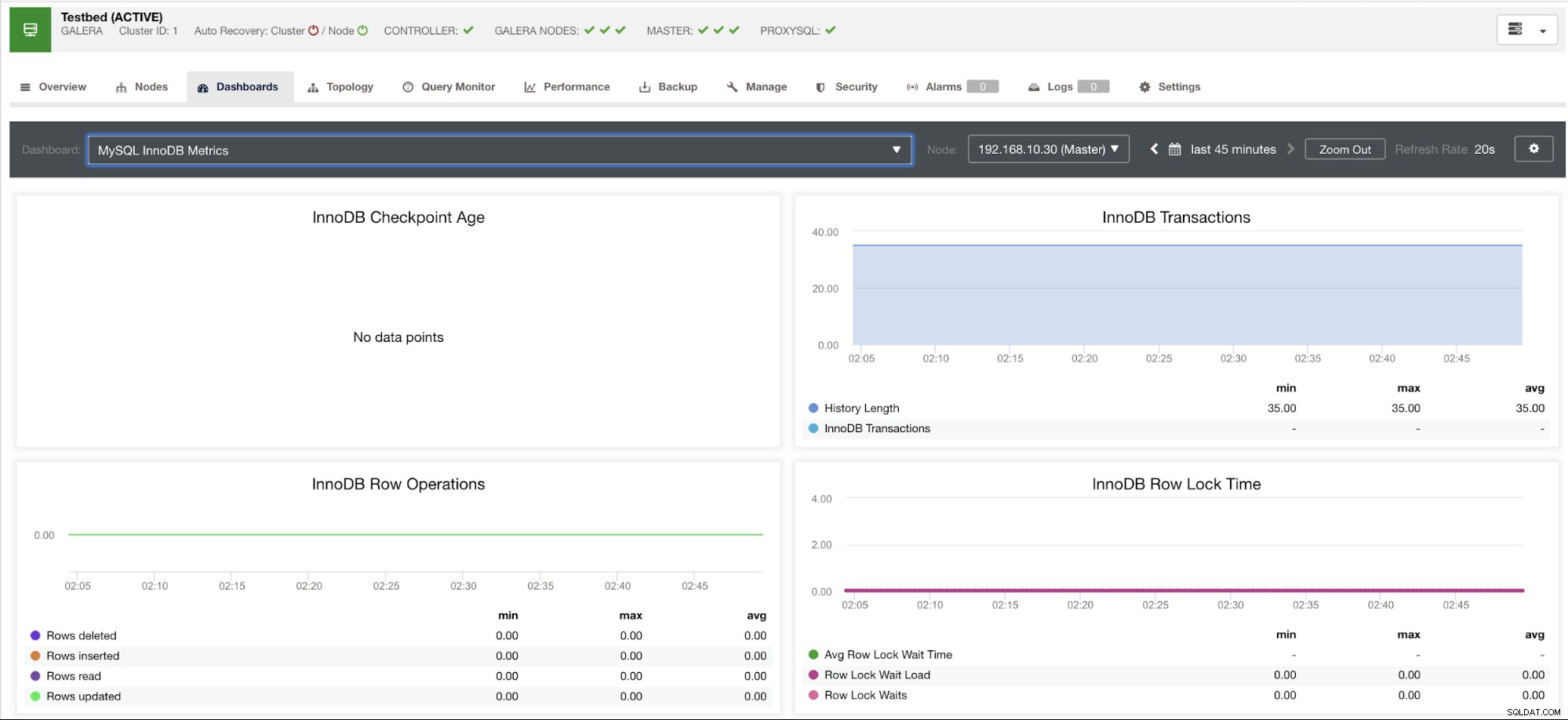
Det här diagrammet togs på en databasserver som körs på en version 10.3.9-MariaDB-log MariaDB Server med wsrep_patch_version av wsrep_25.23-instansen. Nu är frågan, varför laddas inga datapunkter? Tja, när jag frågade noden för en kontrollpunkts åldersstatus, avslöjar den att den är tom eller ingen variabel hittades. Se nedan:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Jag har ingen aning om varför MariaDB inte har denna variabel (vänligen meddela oss i kommentarsfältet på den här bloggen om du har svaret). Detta till skillnad från en Percona XtraDB Cluster Server där variabeln Innodb_checkpoint_max_age existerar. Se nedan:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Vad detta betyder är dock att det kan finnas grafer som inte har samlade datapunkter eftersom det inte har någon data som samlas in på det specifika måttet när en Prometheus-fråga kördes.
En graf som inte har datapunkter betyder dock inte att din nuvarande version av MySQL eller dess variant inte stöder det. Det finns till exempel vissa grafer som kräver vissa variabler som måste ställas in korrekt eller aktiveras.
Följande avsnitt kommer att visa vad dessa grafer är.
Index Condition Pushdown (ICP) Diagram

Den här grafen har nämnts i min tidigare blogg. Den förlitar sig på en MySQL global variabel som heter innodb_monitor_enable. Denna variabel är dynamisk så du kan ställa in den utan en hård omstart av din MySQL-databas. Det kräver också innodb_monitor_enable =modul_icp eller så kan du ställa in den här globala variabeln till innodb_monitor_enable =all. Vanligtvis, för att undvika sådana fall och förvirring om varför en sådan graf inte visar några datapunkter, kan du behöva använda allt utom med försiktighet. Det kan finnas vissa overhead när denna variabel är påslagen och inställd på alla.
MySQL Performance Schema Graphs
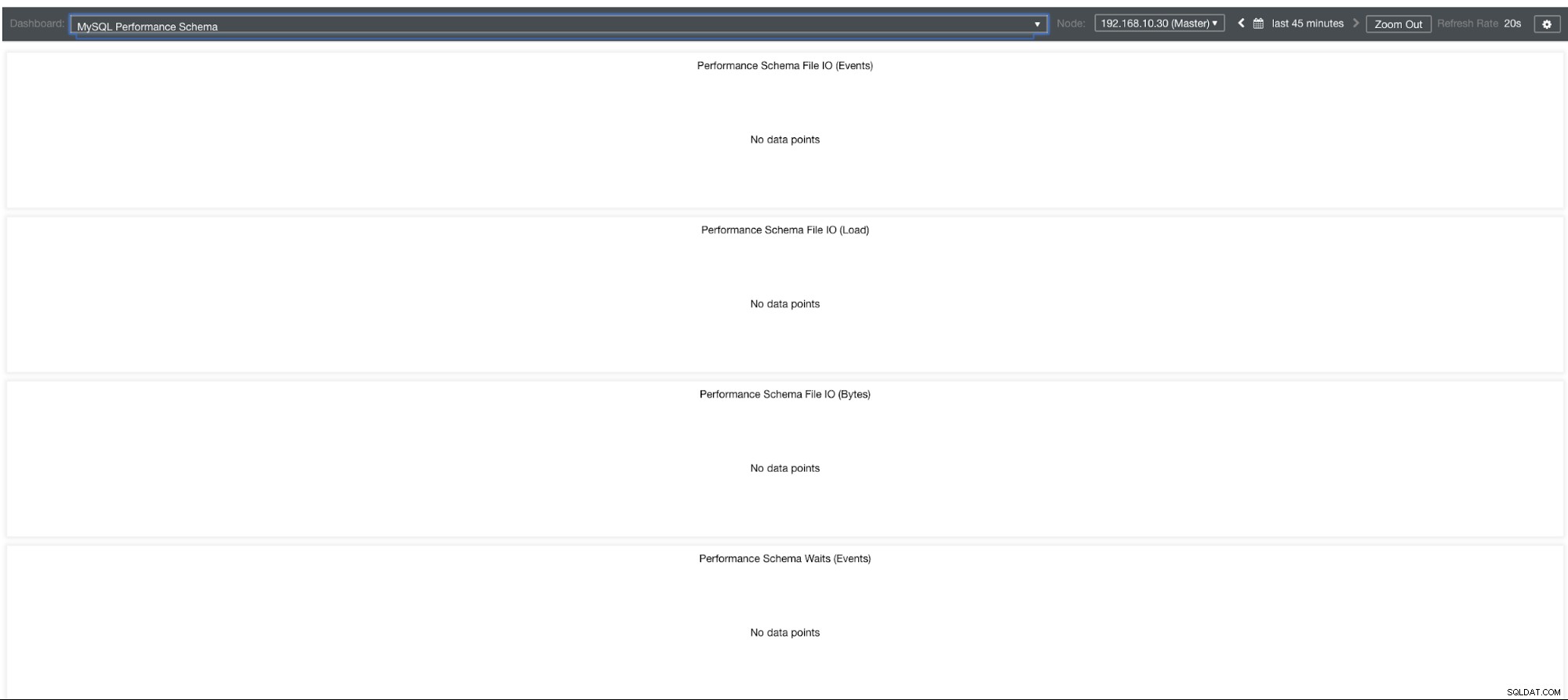
Så varför visar dessa grafer "Inga datapunkter"? När du skapar ett kluster med ClusterControl med våra mallar kommer det som standard att definiera variabler för performance_schema. Till exempel är dessa variabler nedan inställda:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Men om performance_schema =OFF, så är det anledningen till att de relaterade graferna skulle visa "Inga datapunkter".
Men jag har aktiverat performance_schema, varför är andra grafer fortfarande ett problem?
Tja, det finns fortfarande grafer som kräver att flera variabler måste ställas in. Detta har redan tagits upp i vår tidigare blogg. Därför måste du ställa in innodb_monitor_enable =all och userstat=1. Resultatet skulle se ut så här:
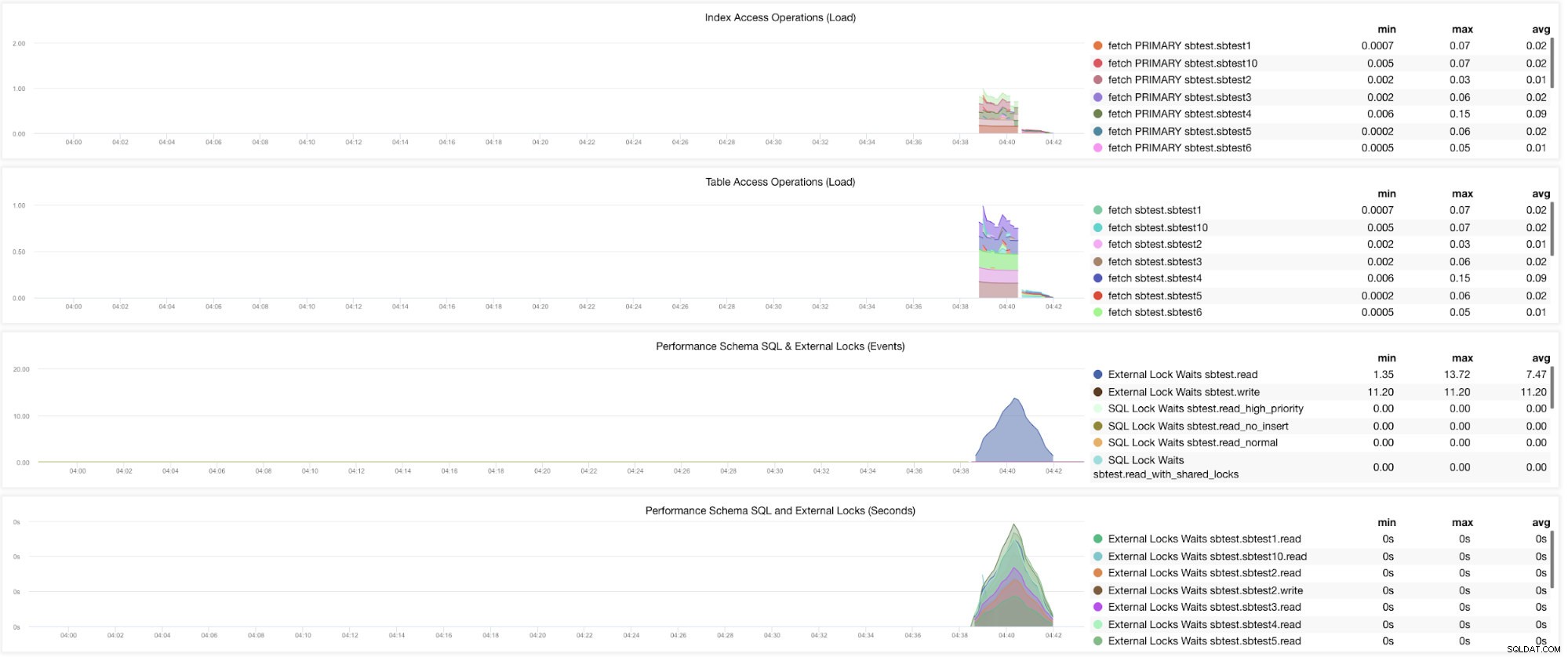
Jag märker dock att i versionen av MariaDB 10.3 (särskilt 10.3.11) kommer inställningen performance_schema=ON att fylla i de mätvärden som behövs för MySQL Performance Schema Dashboard. Detta är en stor fördel eftersom den inte behöver ställa innodb_monitor_enable=ON vilket skulle lägga till extra overhead på databasservern.
Avancerad felsökning
Finns det någon förväg felsökning jag kan rekommendera? Ja, det finns! Men du behöver åtminstone vissa JavaScript-kunskaper. Eftersom SCUMM Dashboards som använder Prometheus förlitar sig på highcharts, kan sättet som mätvärdena som används för PromQL-förfrågningar bestämmas genom app.js-skriptet som visas nedan:
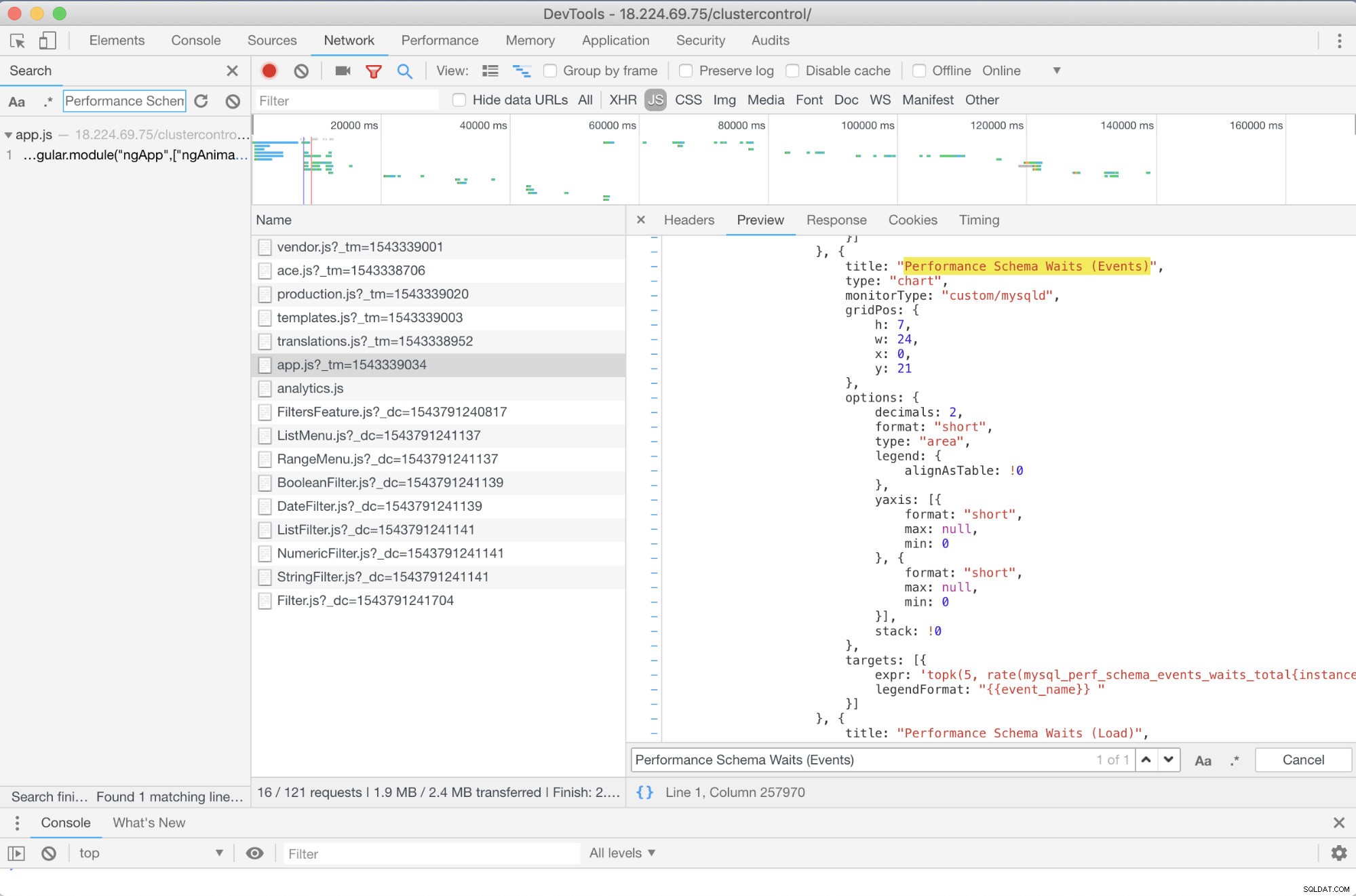
Så i det här fallet använder jag Google Chromes DevTools och försökte leta efter Performance Schema Waits (Events) . Hur kan detta hjälpa? Tja, om du tittar på målen ser du:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Nu kan du använda den begärda statistiken som är mysql_perf_schema_events_waits_total. Du kan kontrollera det till exempel genom att gå igenom https://
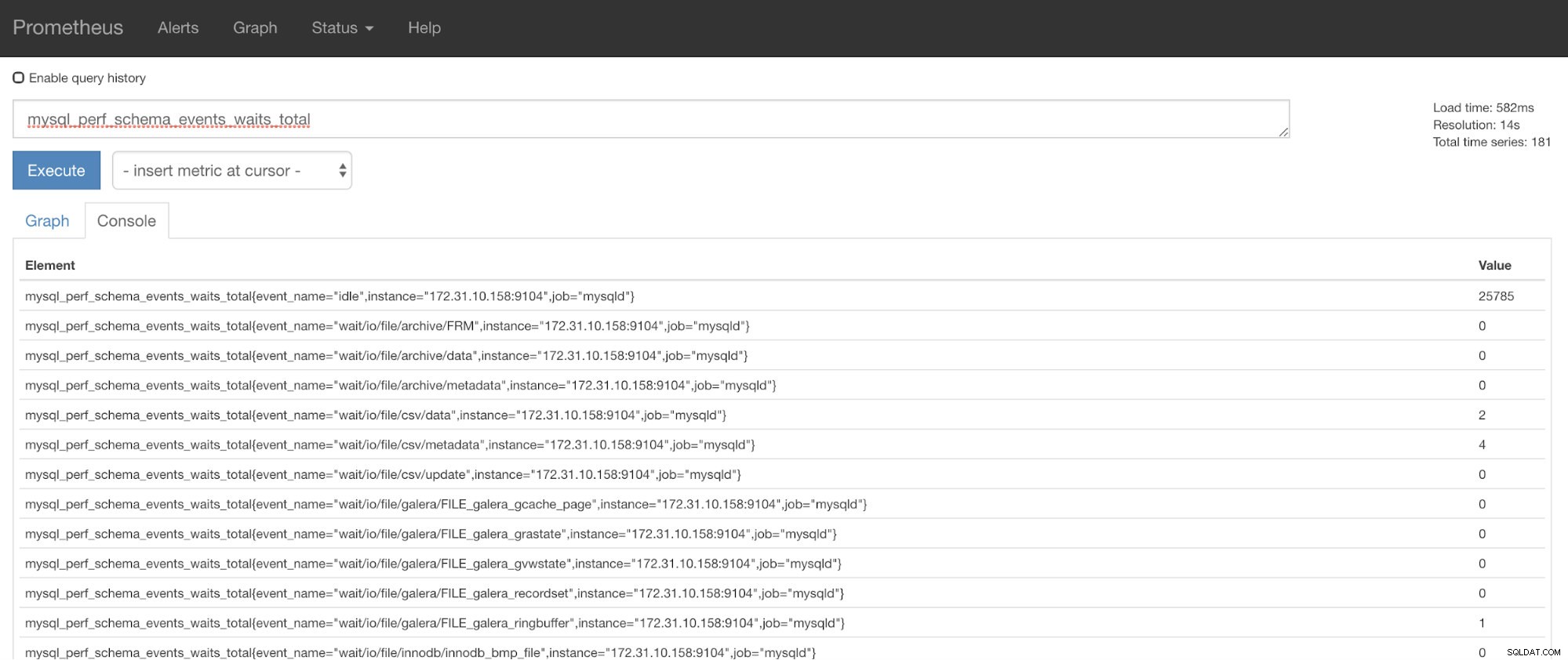
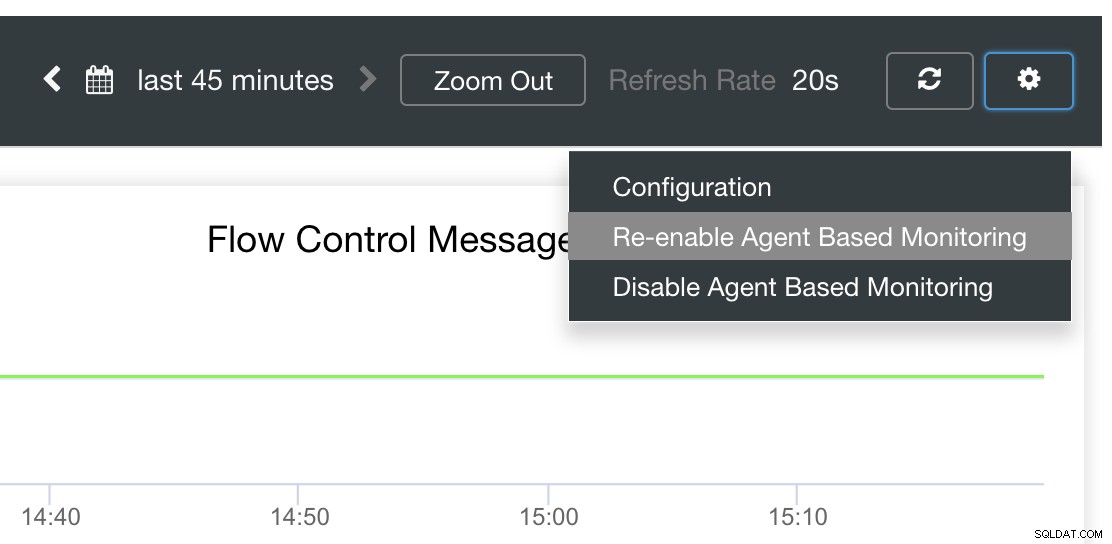
ClusterControl Auto-Recovery till undsättning!
Slutligen är huvudfrågan, finns det ett enkelt sätt att starta om misslyckade exportörer? ja! Vi nämnde tidigare att ClusterControl övervakar exportens tillstånd och startar om dem vid behov. Om du märker att SCUMM Dashboards inte laddar grafer normalt, se till att du har aktiverat automatisk återställning. Se bilden nedan:

När detta är aktiverat kommer detta att säkerställa att
Det är också möjligt att installera om eller konfigurera om exportörerna.
Slutsats
I den här bloggen såg vi hur ClusterControl använder Prometheus för att erbjuda SCUMM Dashboards. Det ger en kraftfull uppsättning funktioner, från högupplösta övervakningsdata och rika grafer. Du har lärt dig att med PromQL kan du fastställa och felsöka våra SCUMM Dashboards som låter dig samla tidsseriedata i realtid. Du kan också skapa grafer eller se genom konsolen för alla mätvärden som har samlats in.
Du lärde dig också hur du felsöker våra SCUMM Dashboards, särskilt när inga datapunkter samlas in.
Om du har frågor, vänligen lägg till dina kommentarer eller låt oss veta genom våra communityforum.