Primära och främmande nycklar är grundläggande egenskaper hos relationsdatabaser, som ursprungligen noterades i E.F. Codds artikel, "A Relational Model of Data for Large Shared Data Banks", publicerad 1970. Citatet som ofta upprepas är:"Nyckeln, hela nyckeln, och inget annat än nyckeln, så hjälp mig Codd."
Bakgrund:Primära nycklar
En primärnyckel är en begränsning i SQL Server, som fungerar för att unikt identifiera varje rad i en tabell. Nyckeln kan definieras som en enda kolumn som inte är NULL eller en kombination av kolumner som inte är NULL som genererar ett unikt värde och används för att framtvinga entitetsintegritet för en tabell. En tabell kan bara ha en primärnyckel, och när en primärnyckelbegränsning definieras för en tabell skapas ett unikt index. Det indexet kommer att vara ett klustrat index som standard, såvida det inte anges som ett icke-klustrat index när den primära nyckelbegränsningen är definierad.
Tänk på Sales.SalesOrderHeader tabellen i AdventureWorks2012 databas. Den här tabellen innehåller grundläggande information om en försäljningsorder, inklusive orderdatum och kund-ID, och varje försäljning identifieras unikt av ett SalesOrderID , som är den primära nyckeln för tabellen. Varje gång en ny rad läggs till i tabellen kommer den primära nyckelbegränsningen (med namnet PK_SalesOrderHeader_SalesOrderID ) kontrolleras för att säkerställa att ingen rad redan finns med samma värde för SalesOrderID .
Främmande nycklar
Separata från primärnycklar, men mycket relaterade, är främmande nycklar. En främmande nyckel är en kolumn eller kombination av kolumner som är samma som primärnyckeln, men i en annan tabell. Främmande nycklar används för att definiera en relation och upprätthålla integritet mellan två tabeller.
För att fortsätta använda det ovannämnda exemplet, SalesOrderID kolumnen finns som en främmande nyckel i Sales.SalesOrderDetail tabell, där ytterligare information om försäljningen lagras, såsom produkt-ID och pris. När en ny rea läggs till i SalesOrderHeader tabell, är det inte nödvändigt att lägga till en rad för den försäljningen i SalesOrderDetail tabell Men när du lägger till en rad i SalesOrderDetail tabell, en motsvarande rad för SalesOrderID måste finns i SalesOrderHeader bord.
Omvänt, vid radering av data, en rad för ett specifikt SalesOrderID kan tas bort när som helst från SalesOrderDetail tabell, men för att en rad ska raderas från SalesOrderHeader tabell, associerade rader från SalesOrderDetail måste raderas först.
Till skillnad från primärnyckelbegränsningar, när en främmande nyckelbegränsning definieras för en tabell, skapas inte ett index som standard av SQL Server. Det är dock inte ovanligt att utvecklare och databasadministratörer lägger till dem manuellt. Den främmande nyckeln kan vara en del av en sammansatt primärnyckel för tabellen, i vilket fall ett klustrat index skulle existera med den främmande nyckeln som en del av klustringsnyckeln. Alternativt kan frågor kräva ett index som inkluderar den främmande nyckeln och en eller flera ytterligare kolumner i tabellen, så ett icke-klustrat index skulle skapas för att stödja dessa frågor. Vidare kan index på främmande nycklar ge prestandafördelar för tabellkopplingar som involverar den primära och främmande nyckeln, och de kan påverka prestandan när primärnyckelns värde uppdateras eller om raden tas bort.
I AdventureWorks2012 databas, det finns en tabell, SalesOrderDetail , med SalesOrderID som en främmande nyckel. För SalesOrderDetail tabell, SalesOrderID och SalesOrderDetailID kombinera för att bilda den primära nyckeln, med stöd av ett klustrat index. Om SalesOrderDetail Tabellen hade inget index på SalesOrderID kolumn, sedan när en rad raderas från SalesOrderHeader , skulle SQL Server behöva verifiera att inga rader för samma SalesOrderID värde finns. Utan några index som innehåller SalesOrderID kolumnen skulle SQL Server behöva utföra en fullständig tabellsökning av SalesOrderDetail . Som du kan föreställa dig, ju större den refererade tabellen är, desto längre tid tar borttagningen.
Ett exempel
Vi kan se detta i följande exempel, som använder kopior av de tidigare nämnda tabellerna från AdventureWorks2012 databas som har utökats med ett skript som finns här. Skriptet har utvecklats av Jonathan Kehayias (blogg | @SQLPoolBoy) och skapar en SalesOrderHeaderEnlarged tabell med 1 258 600 rader och en SalesOrderDetailEnlarged tabell med 4 852 680 rader. Efter att skriptet körts lades den främmande nyckelbegränsningen till med hjälp av satserna nedan. Observera att begränsningen skapas med ON DELETE CASCADE alternativ. Med det här alternativet, när en uppdatering eller radering utfärdas mot SalesOrderHeaderEnlarged tabell, rader i motsvarande tabell(er) – i det här fallet bara SalesOrderDetailEnlarged – uppdateras eller raderas.
Dessutom är standard, klustrade index för SalesOrderDetailEnglarged släpptes och återskapades för att bara ha SalesOrderDetailID som primärnyckel, eftersom den representerar en typisk design.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Med den främmande nyckel-begränsningen och inget stödjande index, utfärdades en enda radering mot SalesOrderHeaderEnlarged tabell, vilket resulterade i att en rad togs bort från SalesOrderHeaderEnlarged och 72 rader från SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Statistikens IO och tidsinformation visade följande:
SQL Server-analys och kompileringstid:CPU-tid =8 ms, förfluten tid =8 ms.
Tabell 'Försäljningsorderdetaljförstorad'. Scan count 1, logiskt läser 50647, fysiskt läser 8, read-ahead läser 50667, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Arbetstabell'. Scan count 2, logisk läser 7, fysisk läser 0, read-ahead läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'SalesOrderHeaderEnlarged'. Skanningsantal 0, logiskt läser 15, fysiskt läser 14, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
SQL Server Execution Times:
CPU-tid =1045 ms, förfluten tid =1898 ms.
Genom att använda SQL Sentry Plan Explorer visar exekveringsplanen en klustrad indexskanning mot SalesOrderDetailEnlarged eftersom det inte finns något index på SalesOrderID :
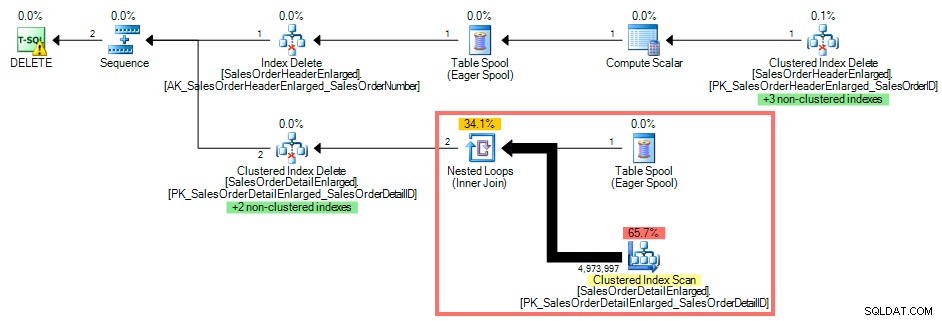
Frågeplan utan index på den främmande nyckeln
Det icke-klustrade indexet som stöder SalesOrderDetailEnlarged skapades sedan med följande uttalande:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
En annan radering utfördes för ett SalesOrderID som påverkade en rad i SalesOrderHeaderEnlarged och 72 rader i SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Statistikens IO och tidsinformation visade en dramatisk förbättring:
SQL Server-analys och kompileringstid:CPU-tid =0 ms, förfluten tid =7 ms.
Tabell 'Försäljningsorderdetaljförstorad'. Scan count 1, logiskt läser 48, fysiskt läser 13, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.
Tabell 'Arbetstabell'. Scan count 2, logisk läser 7, fysisk läser 0, read-ahead läser 0, lob logisk läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'SalesOrderHeaderEnlarged'. Skanningsantal 0, logiskt läser 15, fysiskt läser 15, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
SQL Server Execution Times:
CPU-tid =0 ms, förfluten tid =27 ms.
Och frågeplanen visade en indexsökning av det icke-klustrade indexet på SalesOrderID , som förväntat:
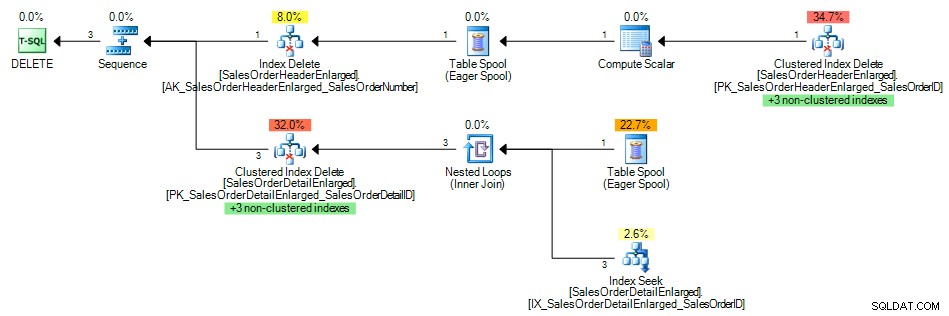
Frågeplan med index på den främmande nyckeln
Frågekörningstiden sjönk från 1898 ms till 27 ms – en minskning med 98,58 %, och visar SalesOrderDetailEnlarged tabellen minskade från 50647 till 48 – en förbättring på 99,9 %. Bortsett från procentandelar, överväg endast I/O som genereras av borttagningen. SalesOrderDetailEnlarged tabellen är bara 500 MB i det här exemplet, och för ett system med 256 GB tillgängligt minne verkar en tabell som tar upp 500 MB i buffertcachen inte som en hemsk situation. Men en tabell med 5 miljoner rader är relativt liten; de flesta stora OLTP-system har tabeller med hundratals miljoner rader. Dessutom är det inte ovanligt att det finns flera främmande nyckelreferenser för en primärnyckel, där en radering av primärnyckeln kräver borttagningar från flera relaterade tabeller. I så fall är det möjligt att se förlängda varaktigheter för borttagningar, vilket inte bara är ett prestandaproblem, utan också ett blockeringsproblem, beroende på isoleringsnivå.
Slutsats
Det rekommenderas generellt att skapa ett index som leder på kolumnen/kolumnerna för främmande nyckel för att stödja inte bara kopplingar mellan primär- och främmande nycklar, utan även uppdateringar och borttagningar. Observera att detta är en allmän rekommendation, eftersom det finns edge-fallscenarier där det extra indexet på den främmande nyckeln inte användes på grund av extremt liten tabellstorlek, och de ytterligare indexuppdateringarna faktiskt påverkade prestandan negativt. Som med alla schemaändringar bör indextillägg testas och övervakas efter implementering. Det är viktigt att säkerställa att de ytterligare indexen ger önskade effekter och inte påverkar lösningens prestanda negativt. Det är också värt att notera hur mycket extra utrymme som krävs av indexen för främmande nycklar. Detta är viktigt att överväga innan du skapar indexen, och om de ger en fördel måste det övervägas för kapacitetsplanering framöver.