Du kanske har hört talas om termen "failover" i samband med MySQL-replikering. Du kanske undrade vad det är när du börjar ditt äventyr med databaser. Kanske vet du vad det är men du är inte säker på potentiella problem relaterade till det och hur de kan lösas?
I det här blogginlägget kommer vi att försöka ge dig en introduktion till failover-hantering i MySQL &MariaDB.
Vi kommer att diskutera vad failover är, varför det är oundvikligt, vad skillnaden är mellan failover och switchover. Vi kommer att diskutera failover-processen i den mest generiska formen. Vi kommer också att beröra lite olika frågor som du kommer att behöva hantera i samband med failover-processen.
Vad betyder "failover"?
MySQL-replikering är ett kollektiv av noder, var och en av dem kan tjäna en roll i taget. Det kan bli en mästare eller en replik. Det finns bara en huvudnod vid en given tidpunkt. Denna nod tar emot skrivtrafik och den replikerar skrivningar till sina repliker.
Som du kan föreställa dig är masternoden ganska viktig eftersom den är en enda ingångspunkt för data till replikeringsklustret. Vad skulle hända om det hade misslyckats och blivit otillgängligt?
Detta är ett ganska allvarligt tillstånd för ett replikeringskluster. Den kan inte acceptera några skrivningar vid ett givet tillfälle. Som du kanske förväntar dig kommer en av replikerna att behöva ta över mästarens uppgifter och börja acceptera skrivningar. Resten av replikeringstopologin kan också behöva ändras - återstående repliker bör ändra sin master från den gamla, misslyckade noden till den nyligen valda. Denna process att "promota" en replik till att bli en mästare efter att den gamla mästaren har misslyckats kallas "failover".
Å andra sidan händer "byte" när användaren utlöser marknadsföringen av repliken. En ny master befordras från en replik som pekas ut av användaren och den gamla mastern blir vanligtvis en replik till den nya mastern.
Den viktigaste skillnaden mellan "failover" och "switchover" är den gamla mästarens tillstånd. När en failover utförs är den gamla mastern på något sätt inte tillgänglig. Den kan ha kraschat, den kan ha drabbats av en nätverkspartitionering. Den kan inte användas vid ett givet tillfälle och dess tillstånd är vanligtvis okänt.
Å andra sidan, när en omställning utförs, lever den gamle mästaren i gott humör. Detta får allvarliga konsekvenser. Om en master inte kan nås kan det betyda att en del av datan ännu inte har skickats till slavarna (såvida inte semisynkron replikering användes). En del av datan kan ha skadats eller skickats delvis.
Det finns mekanismer på plats för att undvika spridning av sådan korruption på slavar, men poängen är att en del av data kan gå förlorade under processen. Å andra sidan, när en övergång utförs, är den gamla mastern tillgänglig och datakonsistensen bibehålls.
Failover-process
Låt oss ägna lite tid åt att diskutera exakt hur failover-processen ser ut.
Master Crash har upptäckts
Till att börja med måste en master krascha innan failover kommer att utföras. När det inte är tillgängligt utlöses en failover. Än så länge verkar det enkelt men sanningen är att vi redan är på halt underlag.
Först och främst, hur testas mästarens hälsa? Testas det från en plats eller distribueras tester? Försöker programvaran för failover-hantering bara att ansluta till mastern eller implementerar den mer avancerade verifieringar innan masterfel deklareras?
Låt oss föreställa oss följande topologi:
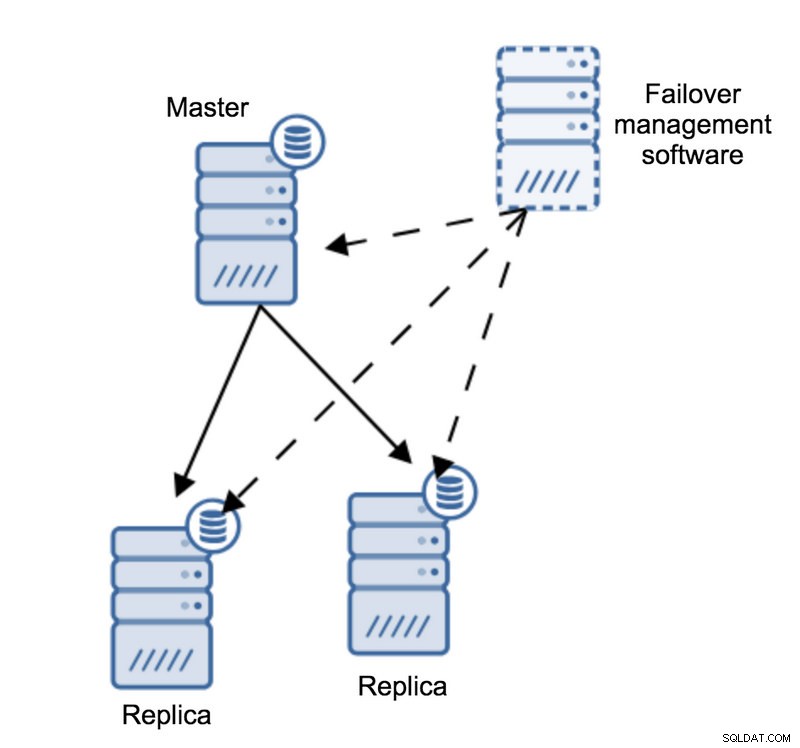
Vi har en mästare och två repliker. Vi har också en programvara för hantering av failover som finns på någon extern värd. Vad skulle hända om en nätverksanslutning mellan värden med failover-programvara och mastern misslyckades?
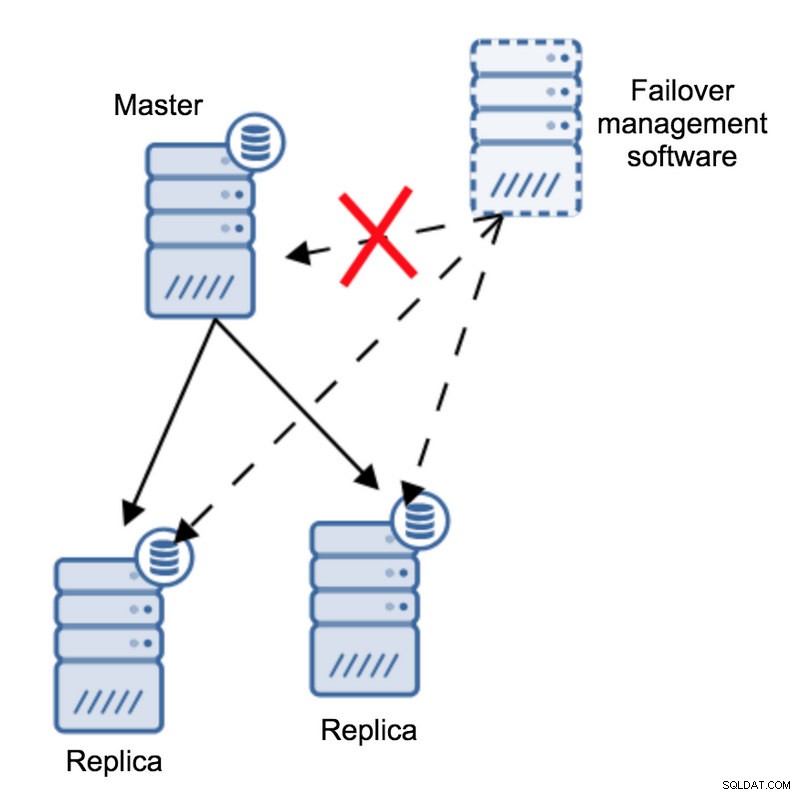
Enligt programvaran för failover-hantering har mastern kraschat - det finns ingen anslutning till den. Ändå fungerar själva replikeringen alldeles utmärkt. Vad som bör hända här är att programvaran för failover-hantering skulle försöka ansluta till repliker och se vad deras synvinkel är.
Klagar de över en trasig replikering eller replikerar de glatt?
Saker och ting kan bli ännu mer komplexa. Vad händer om vi lägger till en proxy (eller en uppsättning fullmakter)? Den kommer att användas för att dirigera trafik - skriver till master och läser till repliker. Vad händer om en proxy inte kan komma åt mastern? Vad händer om ingen av proxyerna kan komma åt mastern?
Detta innebär att applikationen inte kan fungera under dessa förhållanden. Ska failover (det skulle faktiskt vara mer av en övergång eftersom mastern tekniskt sett lever) utlösas?
Tekniskt sett lever mastern men den kan inte användas av applikationen. Här måste affärslogiken komma in och ett beslut måste fattas.
Förhindra den gamla mästaren från att springa
Oavsett hur och varför, om det finns ett beslut att marknadsföra en av replikerna till att bli en ny mästare, måste den gamla mästaren stoppas och, idealiskt sett, borde den inte kunna börja igen.
Hur detta kan uppnås beror på detaljerna i den speciella miljön; därför förstärks denna del av failover-processen vanligtvis av externa skript som är integrerade i failover-processen genom olika krokar.
Dessa skript kan designas för att använda verktyg som finns tillgängliga i den specifika miljön för att stoppa den gamla mastern. Det kan vara ett CLI- eller API-anrop som stoppar en virtuell dator; det kan vara skalkod som kör kommandon genom någon sorts "lights out management"-enhet; det kan vara ett skript som skickar SNMP-fällor till Power Distribution Unit som inaktiverar strömuttagen som den gamla mastern använder (utan ström kan vi vara säkra på att den inte startar igen).
Om en failover-hanteringsprogramvara är en del av en mer komplex produkt, som också hanterar återställning av noder (som det är fallet för ClusterControl), kan den gamla mastern markeras som exkluderad från återställningsrutinerna.
Du kanske undrar varför det är så viktigt att förhindra att den gamla mästaren blir tillgänglig igen?
Huvudproblemet är att i replikeringsinställningar kan endast en nod användas för skrivningar. Vanligtvis säkerställer du det genom att aktivera en read_only (och super_read_only, om tillämpligt) variabel på alla repliker och hålla den inaktiverad endast på mastern.
När en ny master har befordrats kommer den att ha skrivskyddad inaktiverad. Problemet är att om den gamla mastern inte är tillgänglig kan vi inte byta tillbaka den till read_only=1. Om MySQL eller en värd kraschar är det inte så mycket problem eftersom god praxis är att ha my.cnf konfigurerad med den inställningen, så när MySQL startar startar den alltid i skrivskyddat läge.
Problemet visas när det inte är en krasch utan ett nätverksproblem. Den gamla mastern körs fortfarande med read_only inaktiverad, den är bara inte tillgänglig. När nätverk konvergerar kommer du att få två skrivbara noder. Detta kan vara ett problem eller inte. Vissa av proxyservrar använder inställningen read_only som en indikator om en nod är en master eller en replik. Två masters som dyker upp vid det givna ögonblicket kan resultera i ett stort problem eftersom data skrivs till båda värdarna, men repliker får bara hälften av skrivtrafiken (den del som träffade den nya mastern).
Ibland handlar det om hårdkodade inställningar i några av skripten som är konfigurerade att endast ansluta till en given värd. Normalt skulle de misslyckas och någon skulle märka att mastern har ändrats.
När den gamla mastern är tillgänglig kommer de gärna att ansluta till den och dataavvikelser kommer att uppstå. Som du kan se är det en ganska hög prioritet att se till att den gamla mastern inte startar.
Beslut om en masterkandidat
Den gamla mästaren är nere och den kommer inte tillbaka från sin grav, nu är det dags att bestämma vilken värd vi ska använda som ny mästare. Vanligtvis finns det mer än en kopia att välja på, så ett beslut måste tas. Det finns många anledningar till att en replik kan väljas framför en annan, därför måste kontroller utföras.
Vitlistor och svartlistor
Till att börja med kan ett team som hanterar databaser ha sina skäl att välja en replik framför en annan när de bestämmer sig för en masterkandidat. Kanske använder den svagare hårdvara eller har något särskilt jobb tilldelat den (den repliken kör säkerhetskopiering, analytiska frågor, utvecklare har tillgång till den och kör anpassade, handgjorda frågor). Kanske är det en testreplik där en ny version genomgår acceptanstest innan den fortsätter med uppgraderingen. De flesta programvara för failover-hantering stöder vita och svarta listor, som kan användas för att exakt definiera vilka repliker som ska eller inte kan användas som masterkandidater.
Halvsynkron replikering
En replikeringsinställning kan vara en blandning av asynkrona och semisynkrona repliker. Det är en enorm skillnad mellan dem - halvsynkron replika innehåller garanterat alla händelser från mastern. En asynkron replika kanske inte har tagit emot all data, så att misslyckas med den kan leda till dataförlust. Vi skulle hellre se att halvsynkrona repliker marknadsförs.
Replikeringsfördröjning
Även om en halvsynkron replik kommer att innehålla alla händelser, kan dessa händelser fortfarande finnas i reläloggar. Med tät trafik kan alla repliker, oavsett om de är halvsynkroniserade eller asynkrona, släpa efter.
Problemet med replikeringsfördröjning är att när du marknadsför en replik bör du återställa replikeringsinställningarna så att den inte försöker ansluta till den gamla mastern. Detta tar också bort alla reläloggar, även om de inte har tillämpats ännu - vilket leder till dataförlust.
Även om du inte kommer att återställa replikeringsinställningarna kan du fortfarande inte öppna en ny master för anslutningar om den inte har tillämpat alla händelser från sin relälogg. Annars riskerar du att de nya frågorna kommer att påverka transaktioner från reläloggen, vilket utlöser alla slags problem (till exempel kan en applikation ta bort några rader som nås av transaktioner från reläloggen).
Med allt detta under övervägande är det enda säkra alternativet att vänta på att reläloggen ska tillämpas. Ändå kan det ta ett tag om repliken släpade efter kraftigt. Beslut måste fattas om vilken replika som skulle vara en bättre master - asynkron, men med liten fördröjning eller halvsynkron, men med fördröjning som skulle kräva en betydande tid att applicera.
Felaktiga transaktioner
Även om repliker inte bör skrivas till, kan det fortfarande hända att någon (eller något) har skrivit till den.
Det kan ha varit bara en enda transaktion tidigare, men det kan fortfarande ha en allvarlig effekt på förmågan att utföra en failover. Problemet är strikt relaterat till Global Transaction ID (GTID), en funktion som tilldelar ett distinkt ID till varje transaktion som utförs på en given MySQL-nod.
Nuförtiden är det ganska populärt eftersom det ger stora nivåer av flexibilitet och det möjliggör bättre prestanda (med flertrådiga repliker).
Problemet är att, när man omslavar till en ny master, kräver GTID-replikering att alla händelser från den mastern (som inte har körts på repliken) replikeras till repliken.
Låt oss överväga följande scenario:någon gång i det förflutna hände en skrivning på en replik. Det var länge sedan och denna händelse har rensats från replikens binära loggar. Vid något tillfälle har en mästare misslyckats och repliken utsågs till en ny mästare. Alla återstående repliker kommer att slavas av den nya mastern. De kommer att fråga om transaktioner som utförs på den nya mastern. Den kommer att svara med en lista över GTID som kom från den gamla mastern och det enda GTID som är relaterat till den gamla skrivningen. GTID från den gamla mastern är inte ett problem eftersom alla återstående repliker innehåller åtminstone majoriteten av dem (om inte alla) och alla saknade händelser bör vara tillräckligt färska för att vara tillgängliga i den nya masterns binära loggar.
I värsta fall kommer vissa saknade händelser att läsas från de binära loggarna och överföras till repliker. Problemet är med den gamla skrivningen - den hände bara på en ny master, medan den fortfarande var en replik, så den existerar inte på återstående värdar. Det är en gammal händelse och därför finns det inget sätt att hämta den från binära loggar. Som ett resultat kommer ingen av replikerna att kunna slav från den nya mastern. Den enda lösningen här är att vidta en manuell åtgärd och injicera en tom händelse med det problematiska GTID på alla repliker. Det betyder också att replikerna, beroende på vad som hände, kanske inte är synkroniserade med den nya mastern.
Som du kan se är det ganska viktigt att spåra felaktiga transaktioner och avgöra om det är säkert att marknadsföra en viss replik för att bli en ny mästare. Om den innehåller felaktiga transaktioner kanske det inte är det bästa alternativet.
Failover-hantering för applikationen
Det är viktigt att komma ihåg att huvudströmbrytaren, påtvingad eller inte, har en effekt på hela topologin. Skrivningar måste omdirigeras till en ny nod. Detta kan göras på flera sätt och det är viktigt att se till att denna förändring är så transparent för applikationen som möjligt. I det här avsnittet kommer vi att ta en titt på några av exemplen på hur failover kan göras transparent för applikationen.
DNS
Ett av sätten som en applikation kan peka på en master är genom att använda DNS-poster. Med låg TTL är det möjligt att ändra IP-adressen som en DNS-post som "master.dc1.example.com" pekar på. En sådan förändring kan göras genom externa skript som körs under failover-processen.
Tjänstupptäckt
Verktyg som Consul eller etc.d kan också användas för att dirigera trafik till en korrekt plats. Sådana verktyg kan innehålla information om att den aktuella masterns IP är inställd på något värde. Vissa av dem ger också möjlighet att använda värdnamnssökningar för att peka på en korrekt IP. Återigen, poster i tjänsteupptäcktsverktyg måste underhållas och ett av sätten att göra det är att göra dessa ändringar under failover-processen, med hjälp av krokar som exekveras på olika stadier av failover.
Proxy
Proxies kan också användas som en källa till sanning om topologi. Generellt sett, oavsett hur de upptäcker topologin (det kan antingen vara en automatisk process eller så måste proxyn konfigureras om när topologin ändras), bör de innehålla det aktuella tillståndet för replikeringskedjan eftersom de annars inte skulle kunna dirigera frågor korrekt.
Tillvägagångssättet att använda en proxy som en källa till sanning kan vara ganska vanligt i samband med tillvägagångssättet att samlokalisera proxyservrar på applikationsvärdar. Det finns många fördelar med att samlokalisera proxy- och webbservrar:snabb och säker kommunikation med Unix-socket, att hålla ett cachinglager (eftersom vissa av proxyerna, som ProxySQL också kan göra cachningen) nära applikationen. I ett sådant fall är det vettigt att applikationen bara ansluter till proxyn och antar att den kommer att dirigera frågor korrekt.
Failover i ClusterControl
ClusterControl tillämpar branschens bästa praxis för att säkerställa att failover-processen utförs korrekt. Det säkerställer också att processen kommer att vara säker - standardinställningarna är avsedda att avbryta failover om möjliga problem upptäcks. Dessa inställningar kan åsidosättas av användaren om de vill prioritera failover framför datasäkerhet.
När ett masterfel har upptäckts av ClusterControl, initieras en failover-process och en första failover-hook exekveras omedelbart:

Därefter testas mastertillgänglighet.

ClusterControl gör omfattande tester för att säkerställa att mastern verkligen inte är tillgänglig. Detta beteende är aktiverat som standard och det hanteras av följande variabel:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Som ett följande steg ser ClusterControl till att den gamla mastern är nere och om inte, kommer ClusterControl inte att försöka återställa den:

Nästa steg är att bestämma vilken värd som kan användas som masterkandidat. ClusterControl kontrollerar om en vitlista eller en svartlista är definierad.
Du kan göra det genom att använda följande variabler i cmon-konfigurationsfilen:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Det är också möjligt att konfigurera ClusterControl för att leta efter skillnader i binära loggfilter över alla repliker. Det kan göras med variabeln replication_check_binlog_filtration_bf_failover. Som standard är dessa kontroller inaktiverade. ClusterControl verifierar också att det inte finns några felaktiga transaktioner på plats, vilket kan orsaka problem.

Du kan också be ClusterControl att automatiskt bygga om repliker som inte kan replikera från den nya mastern med följande inställning i cmon-konfigurationsfilen:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Efteråt exekveras ett andra skript:det definieras i inställningen replication_pre_failover_script. Därefter genomgår en kandidat förberedelseprocess.


ClusterControl väntar på att redo-loggar ska tillämpas (försäkrar att dataförlusten är minimal). Den kontrollerar också om det finns andra transaktioner tillgängliga på återstående repliker, som inte har tillämpats på masterkandidat. Båda beteendena kan kontrolleras av användaren genom att använda följande inställningar i cmon-konfigurationsfilen:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Som du kan se kan du tvinga fram en failover även om inte alla redo-logghändelser har tillämpats - det låter användaren bestämma vad som har högre prioritet - datakonsistens eller failover-hastighet.


Slutligen väljs mastern och det sista skriptet körs (ett skript som kan definieras som replication_post_failover_script.
Om du inte har provat ClusterControl än rekommenderar jag att du laddar ner det (det är gratis) och provar.
Master Detection i ClusterControl
ClusterControl ger dig möjlighet att distribuera full hög tillgänglighetsstack inklusive databas- och proxylager. Master discovery är alltid en av frågorna att ta itu med.
Hur fungerar det i ClusterControl?
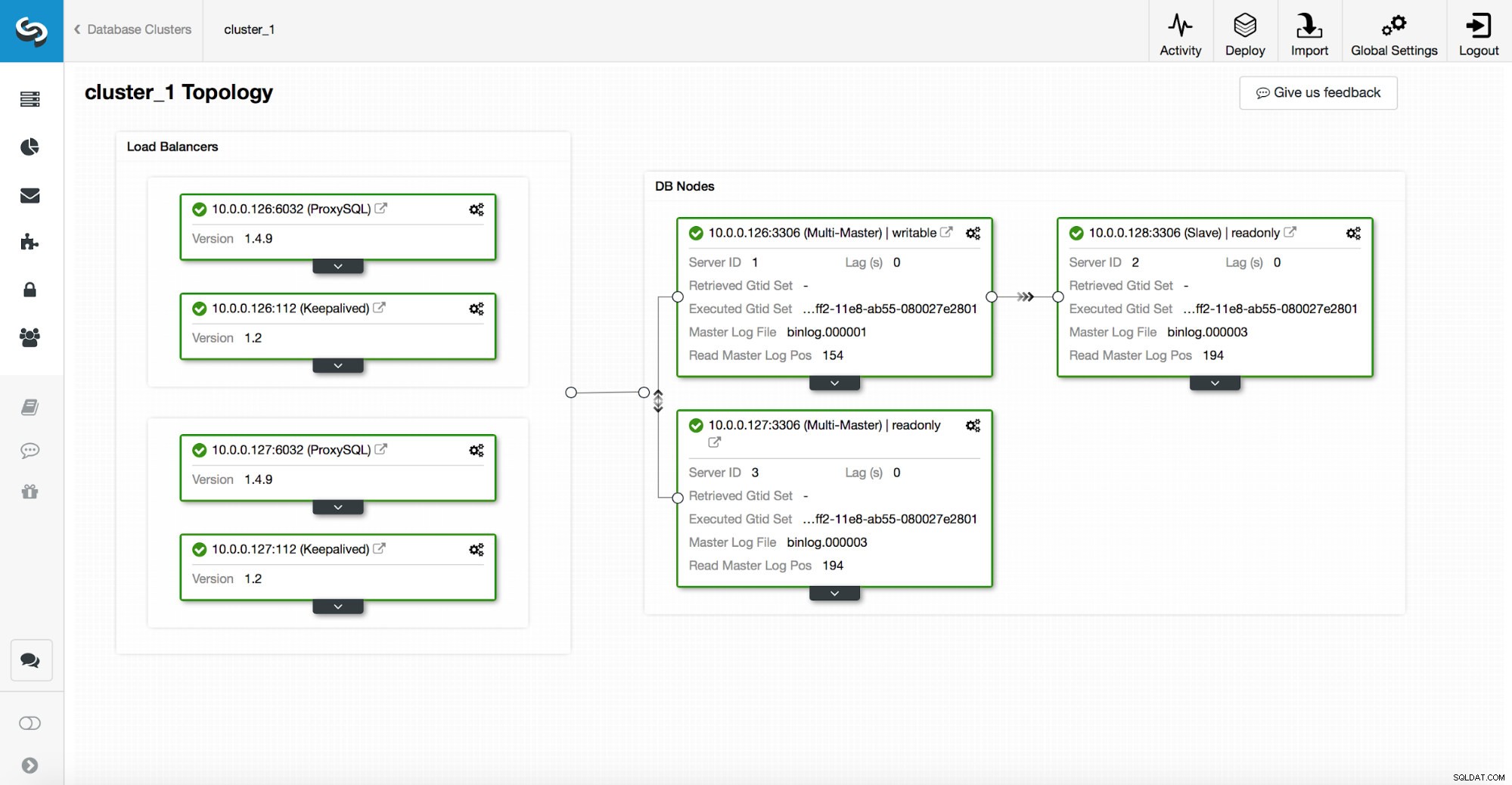
En hög tillgänglighetsstack, distribuerad genom ClusterControl, består av tre delar:
- databaslager
- proxylager som kan vara HAProxy eller ProxySQL
- bevarat lager, som med användning av virtuell IP säkerställer hög tillgänglighet för proxylagret
Proxyer förlitar sig på read_only variabler på noderna.
Som du kan se i skärmdumpen ovan är endast en nod i topologin markerad som "skrivbar". Detta är mastern och detta är den enda noden som kommer att ta emot skrivningar.
En proxy (i det här exemplet ProxySQL) kommer att övervaka denna variabel och den kommer att omkonfigurera sig själv automatiskt.
På andra sidan av den ekvationen tar ClusterControl hand om topologiförändringar:failovers och switchovers. Den kommer att göra nödvändiga ändringar i skrivskyddat värde för att återspegla topologins tillstånd efter ändringen. Om en ny master befordras kommer den att bli den enda skrivbara noden. Om en master väljs efter failover, kommer den att ha skrivskyddad inaktiverad.
Ovanpå proxylagret är keepalived utplacerad. Den distribuerar en VIP och den övervakar tillståndet för underliggande proxynoder. VIP pekar på en proxynod vid en given tidpunkt. Om denna nod går ner omdirigeras virtuell IP till en annan nod, vilket säkerställer att trafiken som dirigeras till VIP når en sund proxynod.
För att sammanfatta det, en applikation ansluter till databasen med hjälp av virtuell IP-adress. Denna IP pekar på en av fullmakterna. Proxyer omdirigerar trafik i enlighet med topologistrukturen. Information om topologi härleds från skrivskyddat tillstånd. Denna variabel hanteras av ClusterControl och den ställs in baserat på de topologiändringar som användaren begärt eller ClusterControl som utförs automatiskt.