För att implementera stöd för flera språk i din datamodell behöver du inte uppfinna hjulet på nytt. Den här artikeln visar dig de olika sätten att göra det och hjälper dig välja det som fungerar bäst för dig.
Begreppet lokalisering är avgörande för utvecklingen av en mjukvaruapplikation, särskilt när den applikationens omfattning är global. Stöd för flera språk är den viktigaste aspekten att överväga; en databasdesign som stöder en flerspråkig applikation gör att du kan diversifiera dina målmarknader och på så sätt nå många fler kunder. Dessutom kan en sådan databasdesign vara en del av din långsiktiga strategi för att designa lokaliseringsfärdiga system.
Nyckeln till att integrera flerspråkig support i din applikation är att göra det på ett sätt som inte drastiskt ökar utvecklings- eller underhållskostnaderna. Eftersom databasmodellering är en oskiljaktig del av mjukvaruutvecklingsprocessen måste du tänka på den bästa designstrategin för datamodeller för att ge din applikation flerspråksstöd.
En korrekt datamodell bör tillåta dig att modifiera applikationen eller lägga till ny funktionalitet samtidigt som du bibehåller stöd för flera språk – utan att lägga till extra ansträngning eller kostnad. Det bör också tillåta dig att införliva nya språk utan att röra applikationen; du behöver bara lägga till motsvarande översättningsdata till databasen.
Enkel implementering kontra flexibilitet och funktionalitet
Det finns olika tillvägagångssätt för att skapa en databasdesign för flerspråkiga applikationer. Var och en har sina fördelar och nackdelar. De som är lättare att implementera erbjuder mindre flexibilitet och mindre funktionalitet; de som erbjuder mer flexibilitet och funktionalitet har mer komplexa implementeringar.
Mitt råd här är att alltid gå efter de som erbjuder mer funktionalitet och flexibilitet även om de är dyrare att genomföra. Ibland gör vi misstaget att tro att en applikation är för liten, att det inte är värt att implementera komplexa scheman för att lösa saker som flerspråksstöd. Men så småningom kommer den applikationen att växa och vi kommer att ångra att vi valde det "snabba och smutsiga" tillvägagångssättet som verkade enklare och billigare.
Det idealiska för att implementera tillbehörsfunktioner till en applikation – vare sig det är stöd för flera språk, ändringsloggning, användarautentisering eller något annat – är att den funktionen har ett eget underschema och dess logik inkapslad i återanvändbara komponenter. På så sätt kan både tillbehörsfunktionerna och dess underschema införlivas i alla nya program med minimal ansträngning.
Ett intelligent databasdesign- och datamodelleringsverktyg som Vertabelo är till stor hjälp för effektiv hantering av dina scheman och underscheman. Kolla också in dessa tips för bättre databasdesign och se till att du följer dem alla. Innan du börjar rita ditt ER-diagram föreslår jag att du överväger denna viktiga serie av databasmodelleringstips.
Vissa tilltalande (men olämpliga) flerspråkiga databasdesignlösningar
Enklast – men minst rekommenderad
Låt oss börja med det minst rekommenderade men enklaste sättet att implementera en flerspråkig applikationsdatabas. Det låter dig snabbt lösa behovet av att stödja en flerspråkig applikation, men det kommer att ge dig problem när applikationen växer i funktionalitet eller i geografisk täckning.
Denna enkla strategi består av att lägga till en extra kolumn för varje textkolumn som behöver översättas och för varje språk som texterna måste översättas till.
Till exempel i Movies tabellen nedan finns en OriginalTitle fält. En extra rubrikkolumn läggs till för varje språk som ska översättas:
| Film-ID | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Die Hard | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | Tillbaka till framtiden | Volver al futuro | Ritorno al futuro | Retour vers le futur |
| 3 | Jurassic Park | Jurásico-parken | Giurassico parco | Parc jurassique |
Applikationen måste hämta beskrivningsdata från kolumnen som motsvarar det språk som valts av användaren. När du behöver lägga till ett nytt språk måste du lägga till ytterligare en kolumn i tabellen för att innehålla texterna översatta till det nya språket. Du måste också anpassa applikationen för att bekräfta det tillagda språket och kolumnerna.
Den här lösningen kräver inte komplicerade JOINs för att få de översatta texterna, och den kräver inte heller dubblerade poster – bara replikering av textinnehållskolumner. Men dess tillämplighet är begränsad till situationer där endast ett fåtal tabeller behöver översättas.
Anta till exempel att du har en Products tabell och en Processes tabell. Var och en av dem har ett beskrivningsfält som behöver översättas; verkar lätt nog, eller hur? Men om hela applikationen (inklusive alla dess menyalternativ, felmeddelanden, etc.) behöver vara flerspråkig, är den här lösningen otillämplig.
Mer mångsidig, men inte heller att rekommendera
För att fortsätta med tanken att behålla översättningar inom samma tabell, är ett alternativ till det tidigare alternativet att förstora textfälten. Detta skulle tillåta oss att lagra alla översättningar i samma fält, organisera dem i en datastruktur (t.ex. ett XML-dokument eller ett JSON-objekt). Nedan har vi ett exempel:
| Film-ID | OriginalTitle | Översättningar |
| 1 | Die Hard | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | Tillbaka till framtiden | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Jurassic Park | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Det här alternativet kräver inga ytterligare kolumner, men lägger till komplexitet. Datafrågorna måste nu kunna bearbeta och tolka datastrukturen som används för flerspråksstöd korrekt. Om till exempel JSON eller XML används för att lagra översättningar måste SQL-frågor använda en SQL-version som stöder den valda datatypen.
Följande SQL-kommando använder MS SQL Server OPENJSON() funktion för att använda innehållet i Translations fältet som en underordnad tabell:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Eftersom det inte finns några funktioner eller operatorer för att manipulera JSON- eller XML-formaterade data i standard SQL, tvingas du skriva dina frågor för en viss RDBMS om du vill använda denna teknik för att lagra översatta texter. Till exempel stöds inte den tidigare frågan av MySQL. Om du behöver läsa JSON-data i Movies tabell med MySQL, skulle du skriva den här frågan:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Lagra översatt text i olika poster
Du kan också välja att använda olika poster för varje språk. Du måste dock övergå till att förlora normaliseringen:samma data upprepas i flera poster, där endast översättningen varierar.
| Film-ID | LanguageId | Titel |
|---|---|---|
| 1 | sv | Die Hard |
| 1 | sp | Duro de matar |
| 1 | det | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | sv | Tillbaka till framtiden |
| 2 | sp | Volver al futuro |
| 2 | det | Ritorno al futuro |
Med det här alternativet kan du skapa vyer av varje tabell som endast returnerar raderna på ett visst språk:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Sedan, för att fråga i tabellen, kan du använda en annan vy enligt målöversättningsspråket. Men normaliseringen av modellen går förlorad och bordsunderhållet är onödigt komplicerat.
Lagra översatt text i separata tabeller
Ett sätt att lagra de översatta texterna utan att bryta relationsmodellen är att ha en detaljtabell för varje tabell som innehåller texter som ska översättas. Den underordnade tabellen som innehåller översättningarna måste ha samma nyckelfält som modertabellen, plus ett fält som anger översättningsspråket.
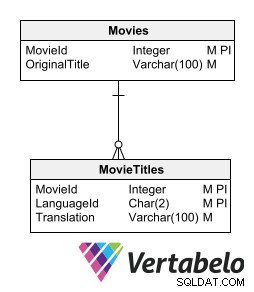
En underordnad tabell med översättningar måste ha samma nyckelfält som modertabellen, plus ett fält som anger översättningsspråket.
Det här alternativet gör det möjligt att införliva nya språk utan att ändra tabellstrukturen. Det kräver inte generering av redundant information eller bryta modellnormaliseringen.
Nackdelen med detta alternativ är att det kräver skapandet av en underordnad tabell för varje tabell som lagrar textdata som kräver översättning. Men tanken på att lagra översättningar i relaterade tabeller för oss närmare det mest tillrådliga sättet att utforma en flerspråkig databas.
Den universella lösningen:Ett översättningsunderschema
För att en applikation och dess databas verkligen ska vara flerspråkig bör alla texter ha en översättning till varje språk som stöds – inte bara textdata i en viss tabell. Detta uppnås med ett översättningsunderschema där all data med textinnehåll som kan nå användarens ögon lagras.
I webbapplikationer avsedda för användning på olika språk är ett översättningsunderschema en nödvändighet, inte ett alternativ. Allt annat kommer att leda till komplexitet som kommer att göra korrekt underhåll av programmet omöjligt.
Nyckeln till att hålla översättningar i ett separat schema är att upprätthålla en indexerad katalog med alla texter som behöver översättas, oavsett om de är enhetsbeskrivningar, felmeddelanden eller menyalternativ. Tanken är att ingen text som kan nå användarens ögon lagras i någon tabell utanför detta underschema.
Ett sätt att organisera översättningskatalogen är att använda tre tabeller:
- En huvudtabell över språk.
- En tabell med texter på originalspråket.
- En tabell över översatta texter.
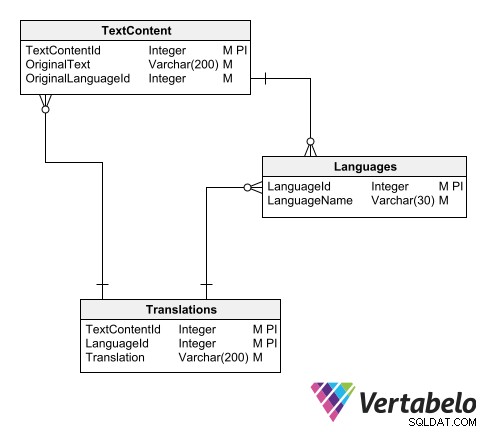
Schema för en universell översättningskatalog.
I huvudtabellen över språk infogar vi helt enkelt en post för varje språk som stöds av datamodellen. Var och en har en ID-kod och ett namn:
| LanguageId | Språknamn |
|---|---|
| sv | Engelska |
| sp | spanska |
| det | Italienska |
| fr | Franska |
Texttabellen registrerar alla texter som kräver översättning. Varje post har ett godtyckligt ID, originaltexten och originalspråkets ID.
I TextContent tabell, originaltexten och originalspråkets ID är inte strikt nödvändiga. Men de förenklar frågor som inte kräver översättning. Till exempel, när man gör statistisk analys eller hanteringskontrollfrågor (som vanligtvis bara är tillgängliga för användare som förstår originalspråket) kan frågorna förenklas genom att använda standardtexterna (icke översatta).
Originaltexterna är också användbara för den som ska fylla tabellen med översatta texter. Inmatning av översättningsdata kan göras med hjälp av en miniapplikation som visar originaltexten och översättningarna på alla tillgängliga språk. Det är också möjligt att generera information för översättningsunderschemat genom en automatisk process med hjälp av ett översättnings-API.
Länka till huvudschemat
I programmets huvudschema ersätts kolumner med textvärden som behöver översättas av ID:n som pekar på tabellen över översatta texter:
Huvudschemat är länkat till översättningsschemat genom tabeller med texter som behöver översättas.
Du kan lämna det ursprungliga textfältet i några av huvudschematabellerna för att underlätta frågor där översättning inte krävs, även om detta genererar redundant information. Till exempel kan vi behålla ProductDescription fältet i Products tabell för att underlätta statistiska frågor eller för att fylla i dimensionerna för ett datalager, och lämna översättningsunderschemat åt sidan när det inte behövs.
- Flerspråkig databasdesign:Gör det en gång och gör det rätt
Vi har sett flera alternativ för att skapa en flerspråkig databasdesign. Vissa är lättare och snabbare att implementera. Den sista lösningen är lite mer komplex, men den ger dig mycket mer flexibilitet. Det kommer också att spara dig problem när det är dags att underhålla applikationen och databasen. På lång sikt blir det alltså mycket billigare.
Ibland lockar den kortaste vägen inom databasdesign dig att tro att du kommer att spara tid och ansträngning. Men när du väljer det, förbiser du det faktum att du förmodligen kommer att behöva gå ner det flera gånger. Om du ignorerar bästa praxis för flerspråkig databasdesign kommer du förmodligen att göra samma jobb om och om igen.