I åratal brukade MySQL-replikering baseras på binära logghändelser - allt en slav visste var den exakta händelsen och den exakta positionen den just läste från mastern. Varje enskild transaktion från en master kan ha slutat i olika binära loggar och i olika positioner i dessa loggar. Det var en enkel lösning som kom med begränsningar - mer komplexa topologiändringar kan kräva att en administratör stoppar replikering på de inblandade värdarna. Eller så kan dessa ändringar orsaka andra problem, t.ex. en slav kunde inte flyttas ner i replikeringskedjan utan en tidskrävande ombyggnadsprocess (vi kunde inte enkelt ändra replikering från A -> B -> C till A -> C -> B utan att stoppa replikeringen på både B och C). Vi har alla varit tvungna att kringgå dessa begränsningar medan vi drömt om en global transaktionsidentifierare.
GTID introducerades tillsammans med MySQL 5.6 och medförde några stora förändringar i hur MySQL fungerar. Först och främst har varje transaktion en unik identifierare som identifierar den på samma sätt på varje server. Det är inte längre viktigt i vilken binär loggposition en transaktion registrerades, allt du behöver veta är GTID:'966073f3-b6a4-11e4-af2c-080027880ca6:4'. GTID är byggt av två delar - den unika identifieraren för en server där en transaktion först utfördes, och ett sekvensnummer. I exemplet ovan kan vi se att transaktionen exekverades av servern med server_uuid av '966073f3-b6a4-11e4-af2c-080027880ca6' och det är den fjärde transaktionen som exekveras där. Denna information räcker för att utföra komplexa topologiändringar - MySQL vet vilka transaktioner som har utförts och därför vet den vilka transaktioner som måste utföras härnäst. Glöm binära loggar, allt finns i GTID.
Så var kan du hitta GTID:s? Du hittar dem på två ställen. På en slav, i "visa slavstatus;" hittar du två kolumner:Retrieved_Gtid_Set och Executed_Gtid_Set. Den första täcker GTID:n som hämtades från mastern via replikering, den andra informerar om alla transaktioner som utfördes på en given värd - både via replikering eller exekveras lokalt.
Konfigurera ett replikeringskluster på det enkla sättet
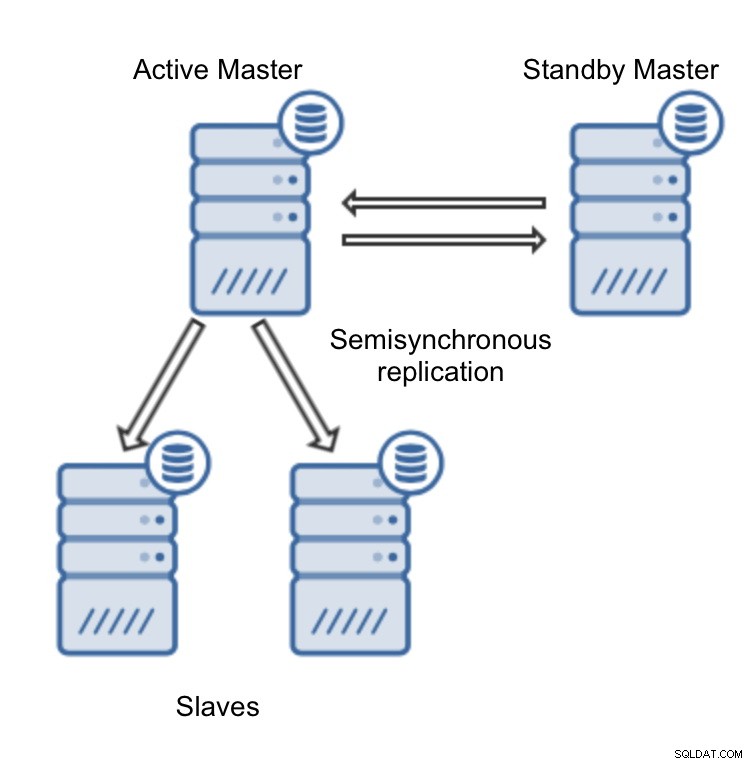
Distribueringen av MySQL-replikeringskluster är mycket lätt i ClusterControl (du kan prova det gratis). Den enda förutsättningen är att alla värdar, som du kommer att använda för att distribuera MySQL-noder till, kan nås från ClusterControl-instansen med en lösenordslös SSH-anslutning.
När anslutningen är på plats kan du distribuera ett kluster genom att använda alternativet "Distribuera". När guidefönstret är öppet måste du ta ett par beslut - vad vill du göra? Vill du distribuera ett nytt kluster? Distribuera en Postgresql-nod eller importera befintligt kluster.
Vi vill distribuera ett nytt kluster. Vi kommer sedan att presenteras med följande skärm där vi måste bestämma vilken typ av kluster vi vill distribuera. Låt oss välja replikering och sedan skicka den nödvändiga informationen om ssh-anslutning.
När du är klar klickar du på Fortsätt. Den här gången måste vi bestämma vilken MySQL-leverantör vi vill använda, vilken version och ett par konfigurationsinställningar inklusive bland annat lösenord för root-kontot i MySQL.
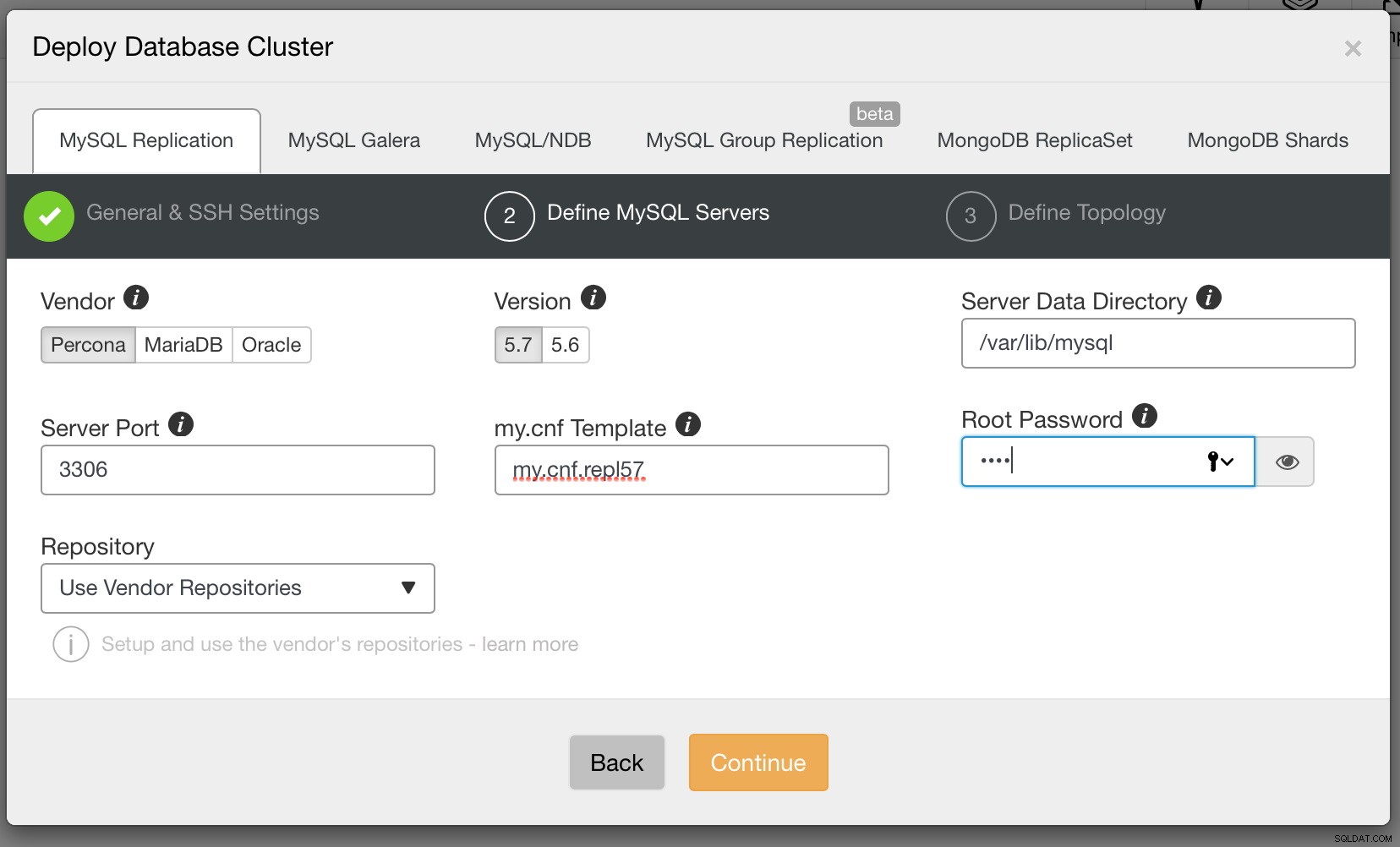
Slutligen måste vi bestämma replikeringstopologin - du kan antingen använda en typisk master - slav-inställning eller skapa mer komplexa, aktiva - standby master - master-par (+ slavar om du vill lägga till dem). När du är klar klickar du bara på "Distribuera" och om några minuter bör du ha ditt kluster distribuerat.
När detta är gjort kommer du att se ditt kluster i klusterlistan för ClusterControls användargränssnitt.
När replikeringen är igång kan vi titta närmare på hur GTID fungerar.
Felaktiga transaktioner – vad är problemet?
Som vi nämnde i början av det här inlägget har GTID medfört en betydande förändring i hur människor bör tänka på MySQL-replikering. Allt handlar om vanor. Låt oss säga, av någon anledning, att en applikation skrev på en av slavarna. Det borde inte ha hänt men överraskande nog händer det hela tiden. Som ett resultat avbryts replikeringen med dubblettnyckelfel. Det finns två sätt att hantera ett sådant problem. En av dem skulle vara att ta bort den felande raden och starta om replikering. En annan skulle vara att hoppa över den binära logghändelsen och sedan starta om replikering.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Båda sätten bör få replikeringen att fungera igen, men de kan introducera datadrift så det är nödvändigt att komma ihåg att slavkonsistensen bör kontrolleras efter en sådan händelse (pt-table-checksum och pt-table-sync fungerar bra här).
Om ett liknande problem inträffar när du använder GTID kommer du att märka vissa skillnader. Att ta bort den felande raden kan tyckas lösa problemet, replikering bör kunna påbörjas. Den andra metoden, att använda sql_slave_skip_counter kommer inte att fungera alls - det kommer att returnera ett fel. Kom ihåg att det nu inte handlar om binlog-händelser, det handlar om att GTID körs eller inte.
Varför "tycks" det bara lösa problemet att ta bort raden? En av de viktigaste sakerna att tänka på när det gäller GTID är att en slav, när den ansluter till mastern, kontrollerar om den saknar några transaktioner som utfördes på mastern. Dessa kallas felaktiga transaktioner. Om en slav hittar sådana transaktioner kommer den att utföra dem. Låt oss anta att vi körde efter SQL för att rensa en felande rad:
DELETE FROM mytable WHERE id=100;Låt oss kontrollera visa slavstatus:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,Och se var 84d15910-b6a4-11e4-af2c-080027880ca6:1 kommer ifrån:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Som du kan se har vi 29 transaktioner som kom från mastern, UUID av 966073f3-b6a4-11e4-af2c-080027880ca6 och en som utfördes lokalt. Låt oss säga att vi någon gång failover och mastern (966073f3-b6a4-11e4-af2c-080027880ca6) blir en slav. Den kommer att kontrollera sin lista över exekverade GTID och hittar inte denna:84d15910-b6a4-11e4-af2c-080027880ca6:1. Som ett resultat kommer den relaterade SQL att köras:
DELETE FROM mytable WHERE id=100;Detta är inte något vi förväntade oss... Om binloggen som innehåller denna transaktion under tiden skulle rensas på den gamla slaven, kommer den nya slaven att klaga efter failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Hur upptäcker man felaktiga transaktioner?
MySQL har två funktioner som är väldigt användbara när du vill jämföra GTID-uppsättningar på olika värdar.
GTID_SUBSET() tar två GTID-uppsättningar och kontrollerar om den första uppsättningen är en delmängd av den andra.
Låt oss säga att vi har följande tillstånd.
Mästare:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Slav:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Vi kan kontrollera om slaven har några felaktiga transaktioner genom att köra följande SQL:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Det verkar som att det finns felaktiga transaktioner. Hur identifierar vi dem? Vi kan använda en annan funktion, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Våra saknade GTID är ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - dessa transaktioner utfördes på slaven men inte på mastern.
Hur löser man problem som orsakas av felaktiga transaktioner?
Det finns två sätt - injicera tomma transaktioner eller exkludera transaktioner från GTID-historiken.
För att injicera tomma transaktioner kan vi använda följande SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Detta måste köras på varje värd i replikeringstopologin som inte har dessa GTID:er exekverade. Om mastern är tillgänglig kan du injicera dessa transaktioner där och låta dem replikera ner i kedjan. Om mastern inte är tillgänglig (till exempel kraschade den), måste dessa tomma transaktioner utföras på varje slav. Oracle utvecklade ett verktyg som heter mysqlslavetrx som är designat för att automatisera denna process.
Ett annat tillvägagångssätt är att ta bort GTID från historiken:
Stoppa slav:
mysql> STOP SLAVE;Skriv ut Executed_Gtid_Set på slaven:
mysql> SHOW MASTER STATUS\GÅterställ GTID-information:
RESET MASTER;Ställ in GTID_PURGED till en korrekt GTID-uppsättning. baserat på data från SHOW MASTER STATUS. Du bör utesluta felaktiga transaktioner från uppsättningen.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Starta slav.
mysql> START SLAVE\GI alla fall bör du verifiera att dina slavar är konsekventa med hjälp av pt-table-checksum och pt-table-sync (om det behövs) - felaktig transaktion kan resultera i datadrift.
Failover i ClusterControl
Från och med version 1.4 förbättrade ClusterControl sina processer för failover-hantering för MySQL-replikering. Du kan fortfarande utföra en manuell huvudswitch genom att befordra en av slavarna till master. Resten av slavarna kommer sedan att övergå till den nya mastern. Från version 1.4 har ClusterControl också möjlighet att utföra en helautomatisk failover om mastern skulle misslyckas. Vi behandlade det på djupet i ett blogginlägg som beskrev ClusterControl och automatiserad failover. Vi vill ändå nämna en funktion som är direkt relaterad till ämnet för det här inlägget.
Som standard utför ClusterControl failover på ett "säkert sätt" - vid tidpunkten för failover (eller switchover, om det är användaren som utförde en master switch), väljer ClusterControl en masterkandidat och verifierar sedan att denna nod inte har några felaktiga transaktioner vilket skulle påverka replikeringen när den väl har befordrats till master. Om en felaktig transaktion upptäcks kommer ClusterControl att stoppa failover-processen och masterkandidaten kommer inte att befordras till att bli en ny master.
Om du vill vara 100 % säker på att ClusterControl kommer att marknadsföra en ny master även om vissa problem (som felaktiga transaktioner) upptäcks, kan du göra det med inställningen replication_stop_on_error=0 i cmon-konfigurationen. Naturligtvis, som vi diskuterade, kan det leda till problem med replikering - slavar kan börja fråga efter en binär logghändelse som inte är tillgänglig längre.
För att hantera sådana fall lade vi till experimentellt stöd för slavåteruppbyggnad. Om du ställer in replication_auto_rebuild_slave=1 i cmon-konfigurationen och din slav är markerad som nere med följande fel i MySQL, kommer ClusterControl att försöka bygga om slaven med hjälp av data från mastern:
Fick fatalt fel 1236 från master vid läsning av data från binär logg:'Slaven ansluter med CHANGE MASTER TO MASTER_AUTO_POSITION =1, men mastern har rensat binära loggar som innehåller GTID som slaven kräver.'
En sådan inställning kanske inte alltid är lämplig eftersom ombyggnadsprocessen kommer att inducera en ökad belastning på mastern. Det kan också vara så att din datauppsättning är mycket stor och att en vanlig ombyggnad inte är ett alternativ - det är därför detta beteende är inaktiverat som standard.