Replikering är ett av de vanligaste sätten att uppnå hög tillgänglighet för MySQL och MariaDB. Den har blivit mycket mer robust med tillägg av GTID, och är noggrant testad av tusentals och åter tusentals användare. MySQL-replikering är dock inte en "ställ in och glöm"-egenskap, den måste övervakas för potentiella problem och underhållas så att den förblir i bra form. I det här blogginlägget vill vi dela med oss av några tips och tricks om hur man underhåller, felsöker och åtgärdar problem med MySQL-replikering.
Hur avgör man om MySQL-replikering är i bra form?
Detta är utan tvekan den viktigaste färdigheten som alla som tar hand om en MySQL-replikeringsinstallation måste besitta. Låt oss ta en titt på var du ska leta efter information om tillståndet för replikering. Det finns en liten skillnad mellan MySQL och MariaDB och vi kommer att diskutera detta också.
VISA SLAVSTATUS
Detta är utan tvekan den vanligaste metoden för att kontrollera tillståndet för replikering på en slavvärd - den har funnits med oss sedan alltid och det är vanligtvis den första platsen dit vi går om vi förväntar oss att det är något problem med replikeringen.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Vissa detaljer kan skilja sig åt mellan MySQL och MariaDB men majoriteten av innehållet kommer att se likadant ut. Ändringar kommer att synas i GTID-sektionen eftersom MySQL och MariaDB gör det på ett annat sätt. Från SHOW SLAVE STATUS kan du härleda en del information - vilken master som används, vilken användare och vilken port som används för att ansluta till mastern. Vi har en del data om den nuvarande binära loggpositionen (inte så viktigt längre eftersom vi kan använda GTID och glömma binlogs) och tillståndet för SQL- och I/O-replikeringstrådar. Sedan kan du se om och hur filtrering är konfigurerad. Du kan också hitta lite information om fel, replikeringsfördröjning, SSL-inställningar och GTID. Exemplet ovan kommer från MySQL 5.7 slav som är i ett hälsosamt tillstånd. Låt oss ta en titt på några exempel där replikeringen är trasig.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Detta prov är hämtat från MariaDB 10.1, du kan se ändringar längst ner i utgången för att få det att fungera med MariaDB GTID:s. Det som är viktigt för oss är felet - du kan se att något inte står rätt till i SQL-tråden:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Vi kommer att diskutera detta specifika problem senare, för nu räcker det att du ser hur du kan kontrollera om det finns några fel i replikeringen med hjälp av VISA SLAVSTATUS.
En annan viktig information som kommer från VISA SLAVSTATUS är – hur illa vår slav släpar. Du kan kontrollera det i kolumnen "Seconds_Behind_Master". Detta mått är särskilt viktigt att spåra om du vet att din applikation är känslig när det kommer till inaktuella läsningar.
I ClusterControl kan du spåra denna data i avsnittet "Översikt":
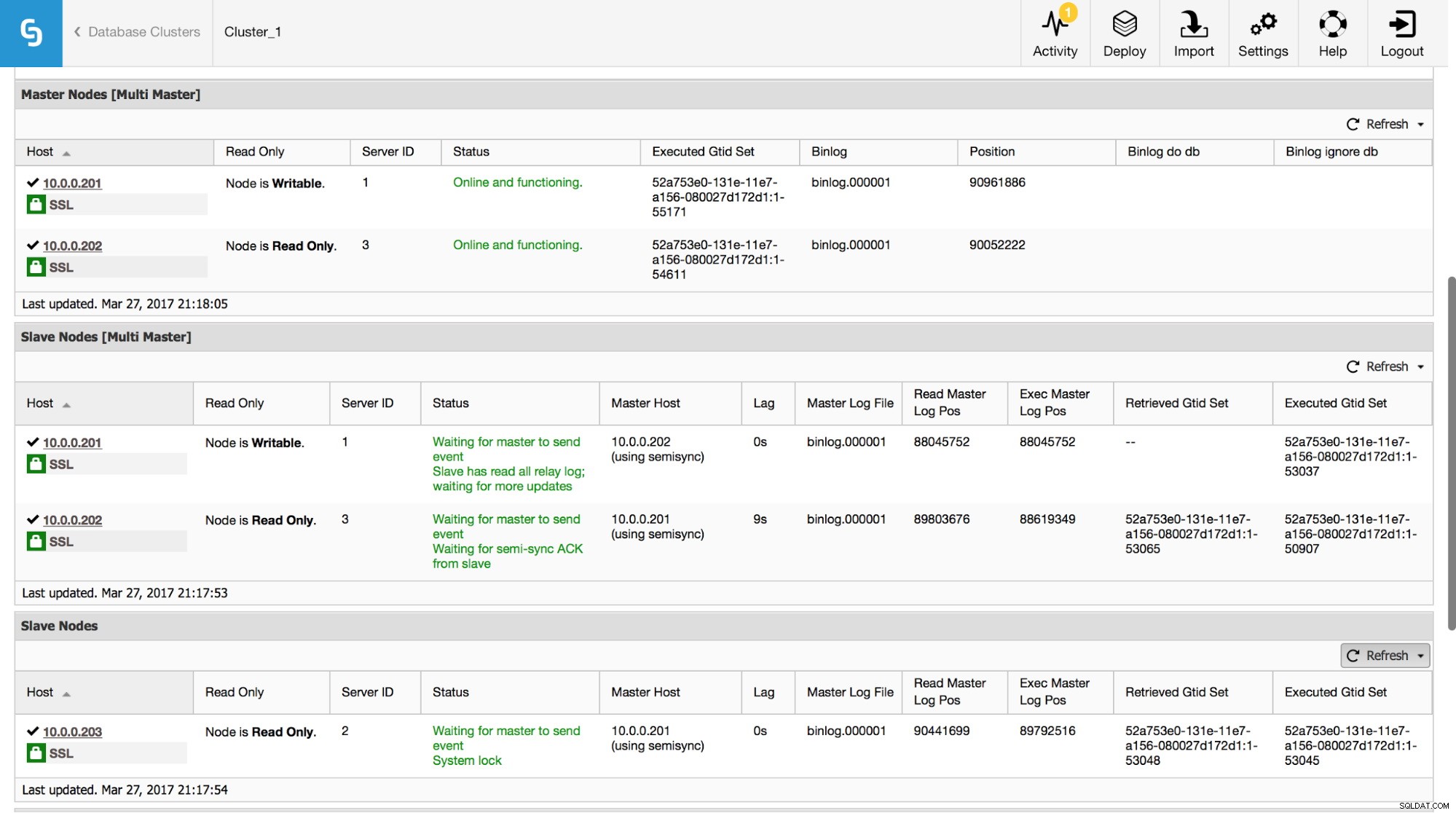
Vi har synliggjort all den viktigaste informationen från kommandot SHOW SLAVE STATUS. Du kan kontrollera statusen för replikeringen, vem som är master, om det finns en replikeringsfördröjning eller inte, binära loggpositioner. Du kan också hitta hämtade och exekverade GTID.
Prestandaschema
En annan plats där du kan leta efter information om replikering är performance_schema. Detta gäller endast Oracles MySQL 5.7 - tidigare versioner och MariaDB samlar inte in denna data.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Nedan kan du hitta några exempel på tillgängliga data i några av dessa tabeller.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Som du kan se kan vi verifiera tillståndet för replikeringen, senaste felet, mottagen transaktionsuppsättning och lite mer data. Vad som är viktigt - om du aktiverade flertrådsreplikering, i tabellen replication_applier_status_by_worker, kommer du att se tillståndet för varje enskild arbetare - detta hjälper dig att förstå tillståndet för replikering för var och en av arbetartrådarna.
Replikeringsfördröjning
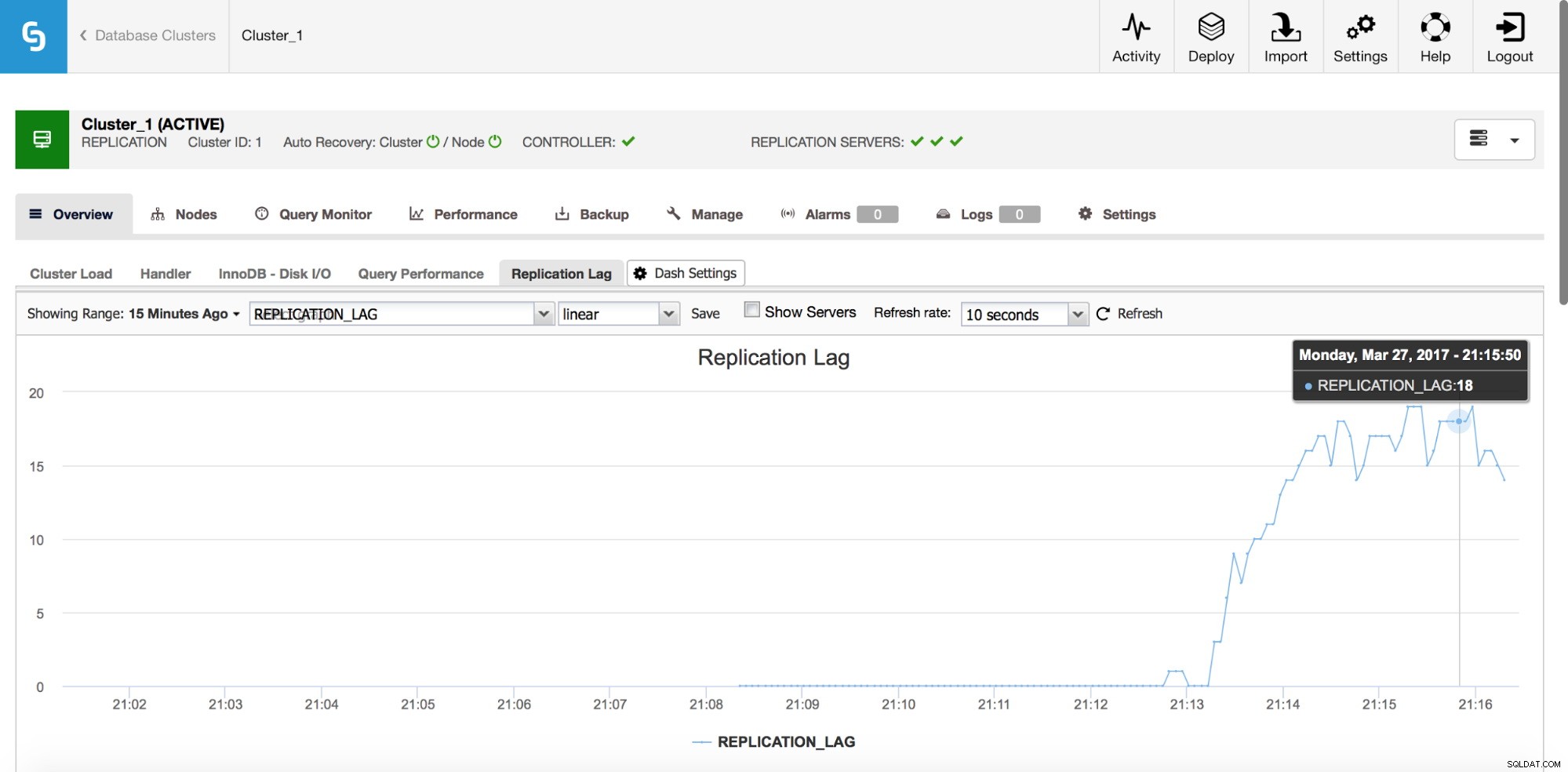
Lagring är definitivt ett av de vanligaste problemen du kommer att stöta på när du arbetar med MySQL-replikering. Replikeringsfördröjning dyker upp när en av slavarna inte kan hålla jämna steg med mängden skrivoperationer som utförs av mastern. Orsakerna kan vara olika - olika hårdvarukonfigurationer, tyngre belastning på slaven, hög grad av skrivparallellisering på master som måste serialiseras (när du använder en enkel tråd för replikeringen) eller så kan skrivningarna inte parallelliseras i samma utsträckning som den har gjort. varit på mastern (när du använder flertrådsreplikering).
Hur upptäcker jag det?
Det finns ett par metoder för att upptäcka replikeringsfördröjningen. Först och främst kan du kontrollera "Seconds_Behind_Master" i SHOW SLAVE STATUS-utgången - den kommer att tala om för dig om slaven släpar efter eller inte. Det fungerar bra i de flesta fall, men i mer komplexa topologier, när du använder mellanliggande masters, på värdar någonstans lågt i replikeringskedjan, kanske det inte är exakt. En annan, bättre, lösning är att lita på externa verktyg som pt-heartbeat. Idén är enkel - en tabell skapas med bland annat en tidsstämpelkolumn. Denna kolumn uppdateras på mastern med jämna mellanrum. På en slav kan du sedan jämföra tidsstämpeln från den kolumnen med aktuell tid - den kommer att berätta hur långt efter slaven är.
Oavsett hur du beräknar fördröjningen, se till att dina värdar är synkroniserade tidsmässigt. Använd ntpd eller andra sätt för tidssynkronisering - om det finns en tidsdrift kommer du att se "falsk" fördröjning på dina slavar.
Hur minskar man fördröjningen?
Det är ingen lätt fråga att svara på. Kort sagt, det beror på vad som orsakar eftersläpningen, och vad som blev en flaskhals. Det finns två typiska mönster - slav är I/O-bunden, vilket betyder att dess I/O-undersystem inte kan hantera mängden skriv- och läsoperationer. För det andra - slav är CPU-bunden, vilket innebär att replikeringstråden använder all CPU den kan (en tråd kan bara använda en CPU-kärna) och det räcker fortfarande inte för att hantera alla skrivoperationer.
När CPU är en flaskhals kan lösningen vara så enkel som att använda flertrådsreplikering. Öka antalet arbetsgängor för att tillåta högre parallellisering. Det är dock inte alltid möjligt - i sådana fall kanske du vill leka lite med grupp commit-variabler (för både MySQL och MariaDB) för att fördröja commits under en liten tidsperiod (vi pratar om millisekunder här) och på detta sätt , öka parallelliseringen av åtaganden.
Om problemet ligger i I/O är problemet lite svårare att lösa. Självklart ska du se över dina InnoDB I/O-inställningar – kanske finns det utrymme för förbättringar. Om my.cnf-tuning inte hjälper, har du inte för många alternativ - förbättra dina frågor (där det är möjligt) eller uppgradera ditt I/O-undersystem till något mer kapabelt.
De flesta proxyservrar (till exempel alla proxyservrar som kan distribueras från ClusterControl:ProxySQL, HAProxy och MaxScale) ger dig en möjlighet att ta bort en slav ur rotation om replikeringsfördröjningen passerar någon fördefinierad tröskel. Detta är inte på något sätt en metod för att minska fördröjningen, men det kan vara till hjälp att undvika inaktuella läsningar och, som en bieffekt, att minska belastningen på en slav vilket borde hjälpa den att komma ikapp.
Naturligtvis kan frågejustering vara en lösning i båda fallen - det är alltid bra att förbättra frågor som är CPU- eller I/O-tunga.
Felaktiga transaktioner
Felaktiga transaktioner är transaktioner som endast har utförts på en slav, inte på mastern. Kort sagt, de gör en slav inkonsekvent med befälhavaren. När du använder GTID-baserad replikering kan detta orsaka allvarliga problem om slaven befordras till en master. Vi har ett djupgående inlägg om detta ämne och vi uppmuntrar dig att titta närmare på det och bekanta dig med hur du upptäcker och åtgärdar problem med felaktiga transaktioner. Vi inkluderade också information om hur ClusterControl upptäcker och hanterar felaktiga transaktioner.
Ingen binlogfil på mastern
Hur identifierar jag problemet?
Under vissa omständigheter kan det hända att en slav ansluter till en master och ber om en icke-existerande binär loggfil. En anledning till detta kan vara den felaktiga transaktionen - någon gång i tiden har en transaktion utförts på en slav och senare blir denna slav en master. Andra värdar, som är konfigurerade att slav från den mastern, kommer att fråga efter den saknade transaktionen. Om det kördes för länge sedan finns det en chans att binära loggfiler redan har rensats.
Ett annat, mer typiskt exempel - du vill tillhandahålla en slav med hjälp av xtrabackup. Du kopierar säkerhetskopian på en värd, applicerar loggen, byter ägare till MySQL-datakatalogen - typiska åtgärder du gör för att återställa en säkerhetskopia. Du kör
SET GLOBAL gtid_purged=baserat på data från xtrabackup_binlog_info och du kör CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (detta är i MySQL, MariaDB har en något annorlunda process), starta slaven och sedan får du ett fel som:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'i MySQL eller:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'i MariaDB.
Detta betyder i princip att mastern inte har alla binära loggar som behövs för att utföra alla saknade transaktioner. Med största sannolikhet är säkerhetskopian för gammal och mastern har redan rensat en del av binära loggar som skapats mellan den tidpunkt då säkerhetskopieringen skapades och när slaven provisionerades.
Hur löser man det här problemet?
Tyvärr finns det inte mycket du kan göra i det här fallet. Om du har några MySQL-värdar som lagrar binära loggar längre tid än mastern, kan du försöka använda dessa loggar för att spela om saknade transaktioner på slaven. Låt oss ta en titt på hur det kan göras.
Först av allt, låt oss ta en titt på det äldsta GTID i masterns binära loggar:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Så, 'binlog.000021' är den senaste (och enda) filen. Låt oss kontrollera vad som är den första GTID-posten i den här filen:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Som vi kan se är den äldsta binära loggposten som finns tillgänglig:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Vi måste också kontrollera vad som är det sista GTID som täcks av säkerhetskopian:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Det är:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 så vi saknar två händelser:
5d1e2227-07c6-11e7-8123-0800274195a:-1066:-1066:-1666:-1666
Låt oss se om vi kan hitta dessa transaktioner på en annan slav.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Det verkar som att 'binlog.000003' är den senaste binära loggen. Vi måste kontrollera om våra saknade GTID:n kan hittas i den:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Tänk på att du kanske vill kopiera binlog-filer utanför produktionsservern eftersom bearbetning av dem kan lägga till en viss belastning. När vi har verifierat att dessa GTID finns kan vi extrahera dem:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlEfter en snabb scp kan vi tillämpa dessa händelser på slaven
slave1:~# mysql -ppass < to_apply_on_slave1.sqlNär det är klart kan vi verifiera om dessa GTID:er har tillämpats genom att titta på utdata från VISA SLAVSTATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set ser bra ut, därför kan vi starta slavtrådar:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Låt oss kolla om det fungerade bra. Vi kommer återigen att använda SHOW SLAVE STATUS output:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Ser bra ut, den är igång!
En annan metod för att lösa detta problem är att ta en säkerhetskopia en gång till och tillhandahålla slaven igen, med hjälp av färska data. Detta kommer sannolikt att vara snabbare och definitivt mer tillförlitligt. Det är inte ofta som du har olika binlog-rensningspolicyer på master och på slavar)
Vi kommer att fortsätta diskutera andra typer av replikeringsproblem i nästa blogginlägg.