PostgreSQL är ett fantastiskt projekt och det utvecklas i en otrolig hastighet. Vi kommer att fokusera på utvecklingen av feltoleransfunktioner i PostgreSQL genom hela dess versioner med en serie blogginlägg. Det här är det tredje inlägget i serien och vi kommer att prata om tidslinjeproblem och deras effekter på feltolerans och pålitlighet hos PostgreSQL.
Om du vill se utvecklingens framsteg från början, vänligen kolla de två första blogginläggen i serien:
- Utveckling av feltolerans i PostgreSQL
- Evolution av feltolerans i PostgreSQL:replikeringsfas

Tidslinjer
Möjligheten att återställa databasen till en tidigare tidpunkt skapar en del komplexitet som vi kommer att täcka några av fallen genom att förklara failover (Fig. 1), växling (Fig. 2) och pg_rewind (Fig. 3) fall senare i detta ämne.
Till exempel, i databasens ursprungliga historik, anta att du tappade ett kritiskt bord klockan 17:15 på tisdagskvällen, men inte insåg ditt misstag förrän onsdag middag. Obetydlig tar du ut din säkerhetskopia, återställer till tidpunkten 17:14 tisdag kväll och är igång. I den här historien om databasuniversum tappade du aldrig tabellen. Men anta att du senare inser att detta inte var en så bra idé och skulle vilja återvända till någon gång onsdag morgon i den ursprungliga historien. Du kommer inte att kunna göra det om, medan din databas var igång, den skrev över några av WAL-segmentfilerna som ledde fram till den tidpunkt du nu önskar att du kunde komma tillbaka till.
För att undvika detta måste du därför skilja serien av WAL-poster som genereras efter att du har gjort en punkt-i-tid-återställning från de som genererades i den ursprungliga databashistoriken.
För att hantera detta problem har PostgreSQL en uppfattning om tidslinjer. Närhelst en arkivåterställning slutförs skapas en ny tidslinje för att identifiera serien av WAL-poster som genereras efter återställningen. Tidslinjens ID-nummer är en del av WAL-segmentfilnamnen så en ny tidslinje skriver inte över WAL-data som genererats av tidigare tidslinjer. Det är faktiskt möjligt att arkivera många olika tidslinjer.
Tänk på situationen där du inte är helt säker på vilken tidpunkt du ska återhämta dig till, och därför måste göra flera punktåterställningar genom försök och misstag tills du hittar det bästa stället att förgrena dig från den gamla historien. Utan tidslinjer skulle denna process snart skapa en ohanterlig röra. Med tidslinjer kan du återställa till alla tidigare tillstånd, inklusive tillstånd i tidslinjegrenar som du övergav tidigare.
Varje gång en ny tidslinje skapas skapar PostgreSQL en "tidslinjehistorik"-fil som visar vilken tidslinje den förgrenade sig från och när. Dessa historikfiler är nödvändiga för att systemet ska kunna välja rätt WAL-segmentfiler vid återställning från ett arkiv som innehåller flera tidslinjer. Därför arkiveras de i WAL-arkivområdet precis som WAL-segmentfiler. Historikfilerna är bara små textfiler, så det är billigt och lämpligt att behålla dem på obestämd tid (till skillnad från segmentfilerna som är stora). Du kan, om du vill, lägga till kommentarer till en historikfil för att spela in dina egna anteckningar om hur och varför just denna tidslinje skapades. Sådana kommentarer kommer att vara särskilt värdefulla när du har ett snår av olika tidslinjer som ett resultat av experiment.
Standardbeteendet för återställning är att återställa längs samma tidslinje som var aktuell när bassäkerhetskopian togs. Om du vill återställa till någon underordnad tidslinje (det vill säga du vill återgå till ett tillstånd som själv skapades efter ett återställningsförsök), måste du ange måltidslinje-ID i recovery.conf. Du kan inte återställa till tidslinjer som förgrenades tidigare än basbackupen.
För att förenkla tidslinjekonceptet i PostgreSQL, tidslinjerelaterade problem vid failover , växling och pg_rewind sammanfattas och förklaras med Fig. 1, Fig. 2 och Fig. 3.
Failover-scenario:
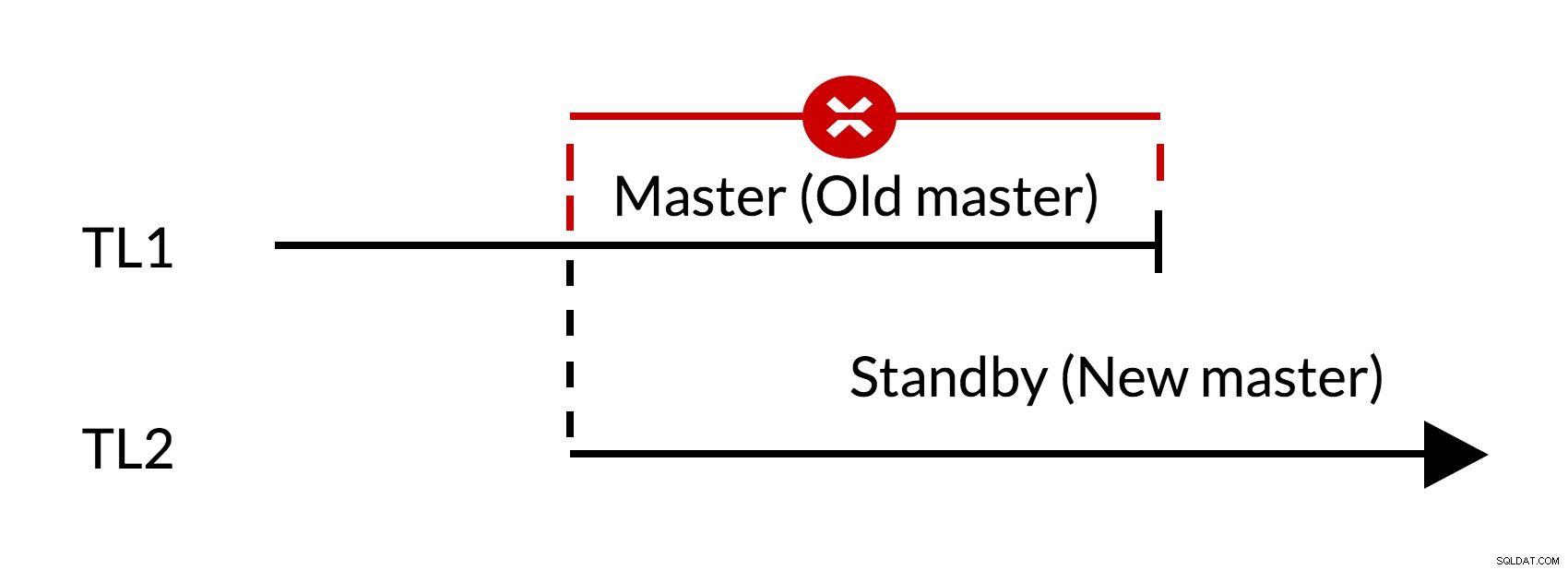
Fig.1 Failover
- Det finns utestående ändringar i den gamla mastern (TL1)
- Tidslinjeökning representerar ny historik över förändringar (TL2)
- Ändringar från den gamla tidslinjen kan inte spelas upp igen på servrarna som bytte till ny tidslinje
- Den gamla mästaren kan inte följa den nya mästaren
Omkopplingsscenario:
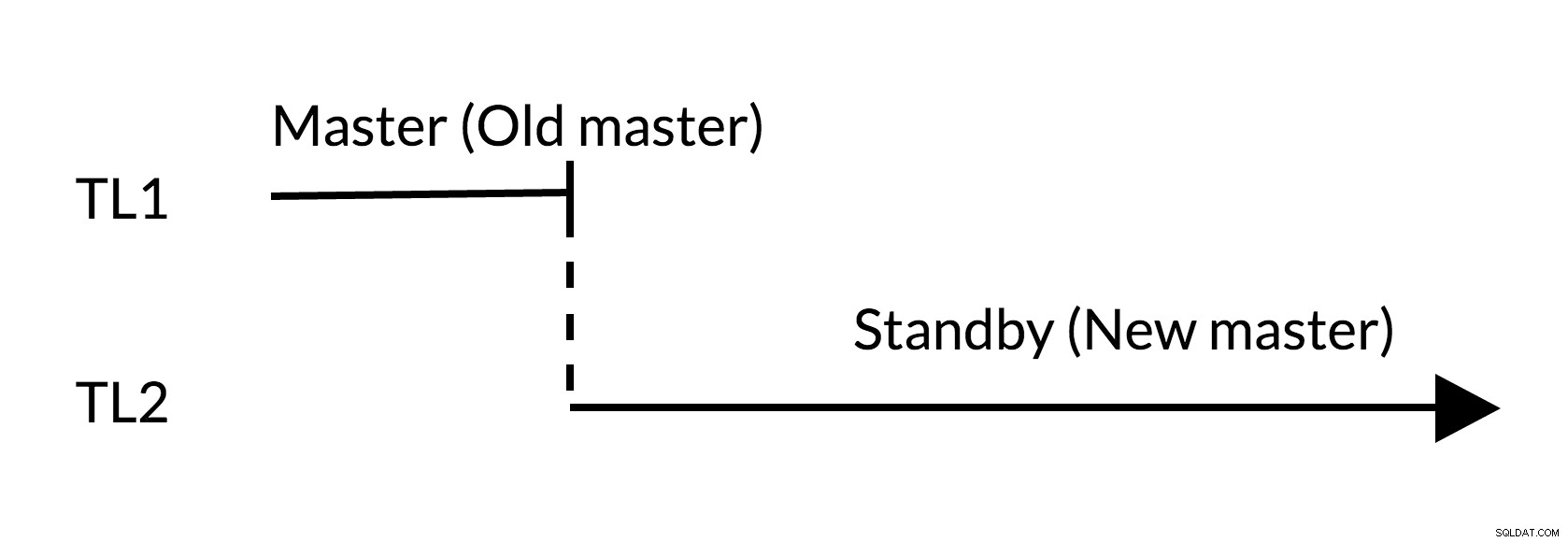 Bild 2 Övergång
Bild 2 Övergång
- Det finns inga utestående ändringar i den gamla mastern (TL1)
- Tidslinjeökning representerar ny historik över förändringar (TL2)
- Den gamla mastern kan bli standby för den nya mastern
pg_rewind scenario:
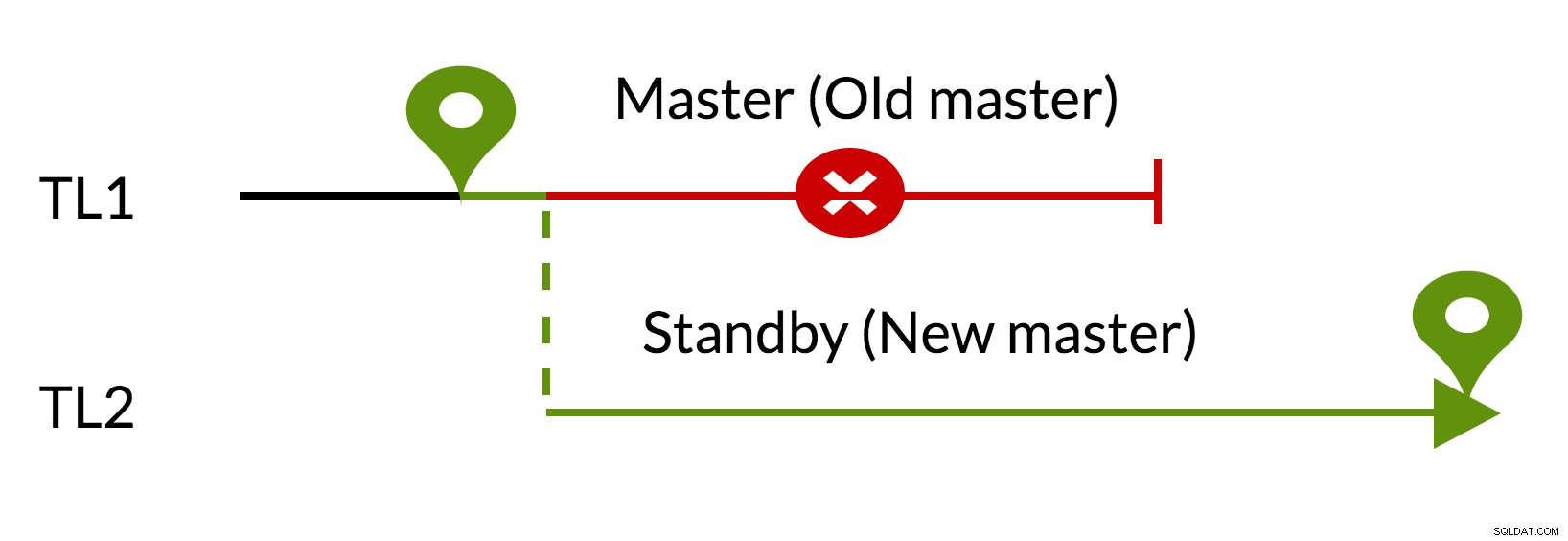 Fig.3 pg_rewind
Fig.3 pg_rewind
- Outstående ändringar tas bort med data från den nya mastern (TL1)
- Den gamla mastern kan följa den nya mastern (TL2)
pg_rewind
pg_rewind är ett verktyg för att synkronisera ett PostgreSQL-kluster med en annan kopia av samma kluster, efter att klustrens tidslinjer har divergerat. Ett typiskt scenario är att koppla in en gammal masterserver igen efter failover, som ett standbyläge som följer den nya mastern.
Resultatet motsvarar att ersätta måldatakatalogen med källkatalogen. Alla filer kopieras, inklusive konfigurationsfiler. Fördelen med pg_rewind framför att ta en ny bassäkerhetskopiering, eller verktyg som rsync, är att pg_rewind inte kräver att läsa igenom alla oförändrade filer i klustret. Det gör det mycket snabbare när databasen är stor och bara en liten del av den skiljer sig åt mellan klustren.
Hur fungerar det?
Grundidén är att kopiera allt från det nya klustret till det gamla klustret, förutom de block som vi vet är desamma.
- Skanna WAL-loggen för det gamla klustret, med början från den sista kontrollpunkten före punkten där det nya klustrets tidslinjehistorik togs bort från det gamla klustret. För varje WAL-post, anteckna datablocken som berördes. Detta ger en lista över alla datablock som ändrades i det gamla klustret, efter att det nya klustret klaffade av.
- Kopiera alla de ändrade blocken från det nya klustret till det gamla klustret.
- Kopiera alla andra filer som tilltäppning och konfigurationsfiler från det nya klustret till det gamla klustret, allt utom relationsfilerna.
- Tillämpa WAL från det nya klustret, med början från kontrollpunkten som skapades vid failover. (Strängt taget tillämpar inte pg_rewind WAL, den skapar bara en backupetikettfil som indikerar att när PostgreSQL startas, kommer den att börja spela upp från den kontrollpunkten och tillämpa alla nödvändiga WAL.)
Obs! wal_log_hints måste ställas in i postgresql.conf för att pg_rewind ska kunna fungera. Denna parameter kan endast ställas in vid serverstart. Standardvärdet är av .
Slutsats
I det här blogginlägget diskuterade vi tidslinjer i Postgres och hur vi hanterar fall av failover och övergång. Vi pratade också om hur pg_rewind fungerar och dess fördelar för Postgres feltolerans och pålitlighet. Vi fortsätter med synkron commit i nästa blogginlägg.
Referenser
PostgreSQL-dokumentation
PostgreSQL 9 Administration Cookbook – Andra upplagan
pg_rewind Nordic PGDay presentation av Heikki Linnakangas