Jag hade nöjet att delta i PGDay UK förra veckan – ett mycket trevligt evenemang, förhoppningsvis får jag chansen att komma tillbaka nästa år. Det fanns många intressanta föredrag, men det som särskilt fångade min uppmärksamhet var Performace för frågor med gruppering av Alexey Bashtanov.
Jag har hållit en hel del liknande prestationsinriktade föredrag tidigare, så jag vet hur svårt det är att presentera benchmarkresultat på ett begripligt och intressant sätt, och Alexey gjorde ett ganska bra jobb, tycker jag. Så om du sysslar med dataaggregering (t.ex. BI, analys eller liknande arbetsbelastningar) rekommenderar jag att du går igenom bilderna och om du får chansen att delta i föredraget på någon annan konferens rekommenderar jag starkt att du gör det.
Men det finns en punkt där jag inte håller med om samtalet. På ett antal ställen föreslog föredraget att du i allmänhet skulle föredra HashAggregate, eftersom sorterna är långsamma.
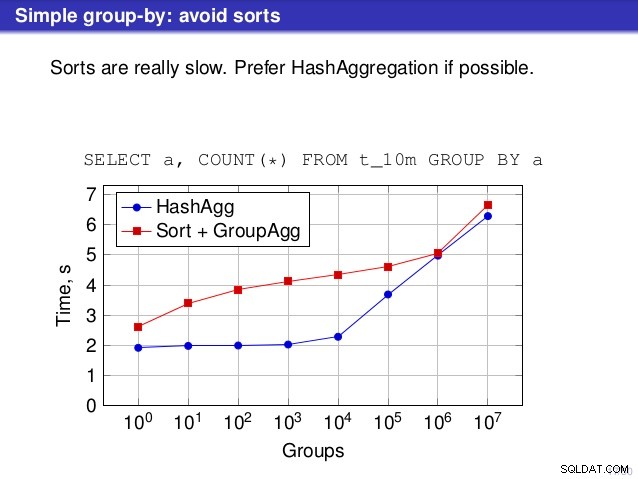
Jag anser att detta är lite missvisande, eftersom ett alternativ till HashAggregate är GroupAggregate, inte Sort. Så rekommendationen förutsätter att varje GroupAggregate har en kapslad sortering, men det är inte riktigt sant. GroupAggregate kräver sorterad indata, och en explicit sortering är inte det enda sättet att göra det – vi har också IndexScan och IndexOnlyScan-noder, som eliminerar sorteringskostnaderna och behåller de andra fördelarna som är förknippade med sorterade sökvägar (särskilt IndexOnlyScan).
Låt mig visa hur (IndexOnlyScan+GroupAggregate) presterar jämfört med både HashAggregate och (Sort+GroupAggregate) – skriptet jag har använt för mätningarna är här. Den bygger fyra enkla tabeller, var och en med 100 miljoner rader och olika antal grupper i kolumnen "branch_id" (bestämmer storleken på hashtabellen). Den minsta har 10k grupper
-- tabell med 10k grupper skapa tabell t_10000 (branch_id bigint, mängd numerisk); infoga i t_10000 välj mod(i, 10000), random() från gener_series(1,100000000) s(i);
och ytterligare tre bord har 100k, 1M och 5M grupper. Låt oss köra den här enkla frågan och sammanställa data:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
och övertyga sedan databasen att använda tre olika planer:
1) HashAggregate
SET enable_sort =off;SET enable_hashagg =on;EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FRÅGEPLAN -------------------------------------------- ---------------------------- HashAggregate (kostnad=2136943.00..2137067.99 rows=9999 width=40) Group Key:branch_id -> Seq Skanna på t_10000 (kostnad=0.00..1636943.00 rows=100000000 width=19)(3 rader)
2) GroupAggregate (med en sortering)
SET enable_sort =on;SET enable_hashagg =off;EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FRÅGEPLAN -------------------------------------------- ------------------------------- GroupAggregate (kostnad=16975438.38..17725563.37 rows=9999 width=40) Group Key:branch_id -> Sortera (kostnad=16975438.38..17225438.38 rows=100000000 width=19) Sorteringsnyckel:branch_id -> Seq Scan på t_10000 (kostnad=0,00..1636943.000 rows) ...pre =0100s)3) GroupAggregate (med en IndexOnlyScan)
SET enable_sort =on;SET enable_hashagg =off;SKAPA INDEX PÅ t_10000 (branch_id, amount);EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1; FRÅGEPLAN -------------------------------------------- -------------------------- GroupAggregate (kostnad=0,57..3983129.56 rader=9999 width=40) Gruppnyckel:branch_id -> Index Endast Scan använder t_10000_branch_id_amount_idx på t_10000 (kostnad=0.57..3483004.57 rows=100000000 width=19)(3 rader)Resultat
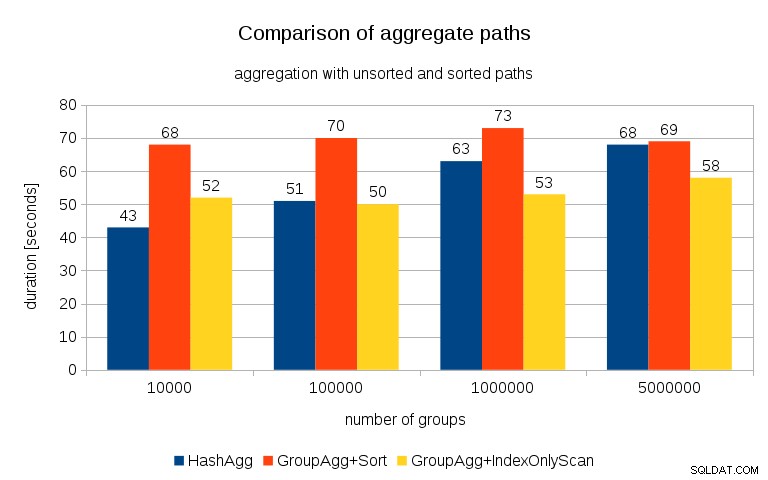
Efter att ha mätt timings för varje plan på alla tabeller ser resultaten ut så här:
För små hashtabeller (passar in i L3-cachen, vilket är 16MB i det här fallet), är HashAggregate-sökvägen klart snabbare än båda sorterade sökvägarna. Men ganska snart blir GroupAgg+IndexOnlyScan lika snabb eller till och med snabbare – detta beror på cacheeffektiviteten, den största fördelen med GroupAggregate. Medan HashAggregate behöver behålla hela hashtabellen i minnet på en gång, behöver GroupAggregate bara behålla den sista gruppen. Och ju mindre minne du använder, desto mer sannolikt är det att det får plats i L3-cachen, vilket är ungefär en storleksordning snabbare jämfört med vanligt RAM-minne (för L1/L2-cachen är skillnaden ännu större).
Så även om det finns en avsevärd omkostnad förknippad med IndexOnlyScan (för 10k-fallet är det cirka 20 % långsammare än HashAggregate-sökvägen), när hashtabellen växer sjunker L3-cachens träffförhållande snabbt och skillnaden gör så småningom GroupAggregate snabbare. Och så småningom blir även GroupAggregate+Sort i nivå med HashAggregate-sökvägen.
Du kanske hävdar att dina data generellt har ett ganska lågt antal grupper, och därför kommer hashtabellen alltid att passa in i L3-cachen. Men tänk på att L3-cachen delas av alla processer som körs på CPU:n och även av alla delar av frågeplanen. Så även om vi för närvarande har ~20 MB L3-cache per socket, kommer din fråga bara att få en del av det, och den biten kommer att delas av alla noder i din (möjligen ganska komplexa) fråga.
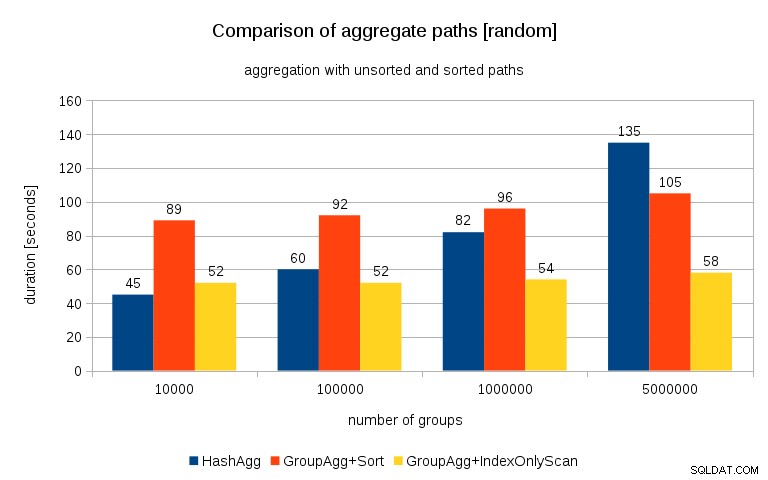
Uppdatering 2016/07/26 :Som påpekats i kommentarerna av Peter Geoghegan, resulterar det sätt som data genererades på förmodligen i korrelation – inte värdena (eller snarare hash av värdena), utan minnesallokationer. Jag har upprepat frågorna med korrekt randomiserad data, det vill säga gör
insert into t_10000 select (10000*random())::bigint, random() från generate_series(1,100000000) s(i);istället för
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);och resultaten ser ut så här:
Jämför jag detta med föregående diagram, tror jag att det är ganska tydligt att resultaten är ännu mer till fördel för sorterade vägar, särskilt för datamängden med 5M-grupper. 5M-datauppsättningen visar också att GroupAgg med en explicit sortering kan vara snabbare än HashAgg.
Sammanfattning
Även om HashAggregate förmodligen är snabbare än GroupAggregate med en explicit sortering (jag är dock tveksam till att säga att det alltid är fallet), men att använda GroupAggregate med IndexOnlyScan snabbare kan lätt göra det mycket snabbare än HashAggregate.
Naturligtvis får du inte välja den exakta planen direkt – planeraren bör göra det åt dig. Men du påverkar urvalsprocessen genom att (a) skapa index och (b) ställa in
work_mem. Det är därför som ibland sänkerwork_mem(ochmaintenance_work_mem) värden ger bättre prestanda.Ytterligare index är dock inte gratis – de kostar både CPU-tid (när ny data infogas) och diskutrymme. För IndexOnlyScans kan diskutrymmeskraven vara ganska betydande eftersom indexet måste inkludera alla kolumner som hänvisas till av frågan, och vanlig IndexScan skulle inte ge dig samma prestanda eftersom den genererar mycket slumpmässiga I/O mot tabellen (vilket eliminerar alla de potentiella vinsterna).
En annan trevlig funktion är stabiliteten i prestandan – lägg märke till hur HashAggregate-timingschansen beror på antalet grupper, medan GroupAggregate-vägarna fungerar i stort sett likadant.