Jag har publicerat flera riktmärken som jämför olika PostgreSQL-versioner, som till exempel prestationsarkeologiföredraget (utvärderar PostgreSQL 7.4 upp till 9.4), och alla dessa riktmärken antagna fasta miljöer (hårdvara, kärna, ...). Vilket är bra i många fall (t.ex. när man utvärderar prestandaeffekten av en patch), men i produktionen förändras dessa saker med tiden – du får hårdvaruuppgraderingar och då och då får du en uppdatering med en ny kärnversion.
För hårdvaruuppgraderingar (bättre lagring, mer RAM, snabbare processorer, …) är effekten vanligtvis ganska lätt att förutsäga, och dessutom inser folk generellt att de måste bedöma effekten genom att analysera flaskhalsarna i produktionen och kanske till och med testa den nya hårdvaran först .
Men vad sägs om kärnuppdateringar? Tyvärr gör vi vanligtvis inte mycket benchmarking på detta område. Antagandet är mest att nya kärnor är bättre än äldre (snabbare, effektivare, skala till fler CPU-kärnor). Men är det verkligen sant? Och hur stor är skillnaden? Om du till exempel uppgraderar en kärna från 3.0 till 4.7 – kommer det att påverka prestandan, och om ja, kommer prestandan att förbättras eller inte?
Då och då får vi rapporter om allvarliga regressioner med en viss kärnversion, eller plötsliga förbättringar mellan kärnversioner. Så klart kan kärnversioner påverka prestanda.
Jag är medveten om ett enda PostgreSQL-riktmärke som jämför olika kärnversioner, gjort 2014 av Sergey Konoplev som svar på rekommendationer om att undvika 3.0-3.8-kärnor. Men det riktmärket är ganska gammalt (den senaste kärnversionen som var tillgänglig för ~18 månader sedan var 3.13, medan vi nuförtiden har 3.19 och 4.6), så jag har bestämt mig för att köra några riktmärken med nuvarande kärnor (och PostgreSQL 9.6beta1).
PostgreSQL kontra kärnversioner
Men låt mig först diskutera några betydande skillnader mellan policyer som styr åtaganden i de två projekten. I PostgreSQL har vi konceptet med större och mindre versioner – större versioner (t.ex. 9.5) släpps ungefär en gång om året och innehåller olika nya funktioner. Mindre versioner (t.ex. 9.5.2) inkluderar bara buggfixar och släpps ungefär var tredje månad (eller oftare när en allvarlig bugg upptäcks). Så det bör inte förekomma några större prestanda- eller beteendeförändringar mellan mindre versioner, vilket gör det ganska säkert att distribuera mindre versioner utan omfattande tester.
Med kärnversioner är situationen mycket mindre tydlig. Linux-kärnan har också grenar (t.ex. 2.6, 3.0 eller 4.7), de är inte på något sätt lika med "huvudversioner" från PostgreSQL, eftersom de fortsätter att få nya funktioner och inte bara buggfixar. Jag påstår inte att PostgreSQL-versionspolicyn på något sätt automatiskt är överlägsen, men konsekvensen är att uppdatering mellan mindre kärnversioner lätt kan påverka prestandan avsevärt eller till och med introducera buggar (t.ex. 3.18.37 drabbas av OOM-problem på grund av en sådan icke-buggfix begå).
Naturligtvis inser distributioner dessa risker och låser ofta kärnversionen och gör ytterligare tester för att sålla bort nya buggar. Det här inlägget använder dock långtidskärnor av vanilj, som finns på www.kernel.org.
Benchmark
Det finns många riktmärken vi kan använda - det här inlägget presenterar en uppsättning pgbench-tester, det vill säga ett ganska enkelt OLTP (TPC-B-liknande) riktmärke. Jag planerar att göra ytterligare tester med andra benchmarktyper (särskilt DWH/DSS-orienterade), och jag kommer att presentera dem på den här bloggen i framtiden.
Nu, tillbaka till pgbench – när jag säger "samling av tester" menar jag kombinationer av
- skrivskyddad vs. läs-skriv
- Datauppsättningsstorlek – aktiv uppsättning passar (inte) i delade buffertar/RAM
- antal klienter – en klient kontra många klienter (låsning/schemaläggning)
Värdena beror uppenbarligen på vilken hårdvara som används, så låt oss se vilken hårdvara denna omgång av riktmärken kördes på:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- Lagring:6x Intel SSD DC S3700 i RAID-10 (Linux sw raid)
- filsystem:ext4 med standard I/O-schemaläggare (cfq)
Så det är samma maskin som jag har använt för ett antal tidigare riktmärken – en ganska liten maskin, inte precis den senaste CPU:n etc. men jag tror att det fortfarande är ett rimligt "litet" system.
Benchmarkparametrarna är:
- datauppsättningsskala:30, 300 och 1500 (alltså ungefär 450 MB, 4,5 GB och 22,5 GB)
- antal klienter:1, 4, 16 (maskinen har 4 kärnor)
För varje kombination fanns det 3 läs-körningar (15 minuter vardera) och 3 läs-skrivkörningar (30 minuter vardera). Det faktiska skriptet som driver riktmärket är tillgängligt här (tillsammans med resultat och annan användbar data).
Obs :Om du har väsentligt olika hårdvara (t.ex. roterande enheter) kan du se mycket olika resultat. Om du har ett system som du vill testa, låt mig veta så hjälper jag dig med det (förutsatt att jag får publicera resultaten).
Kärnversioner
När det gäller kärnversioner har jag testat de senaste versionerna i alla långsiktiga grenar sedan 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 och 4.7). Det finns fortfarande många system som körs på 2.6.x-kärnor, så det är användbart att veta hur mycket prestanda du kan få (eller förlora) genom att uppgradera till en nyare kärna. Men jag har kompilerat alla kärnor på egen hand (dvs med vaniljkärnor, inga distributionsspecifika patchar), och konfigurationsfilerna finns i git-förvaret.
Resultat
Som vanligt är all data tillgänglig på bitbucket, inklusive
- kärn .config-fil
- riktmärkesskript (run-pgbench.sh)
- PostgreSQL-konfiguration (med en del grundläggande justering av hårdvaran)
- PostgreSQL-loggar
- olika systemloggar (dmesg, sysctl, mount, …)
Följande diagram visar genomsnittliga tps för varje benchmarkerat fall – resultaten för de tre körningarna är ganska konsekventa, med ~2 % skillnad mellan min och max i de flesta fall.
skrivskyddad
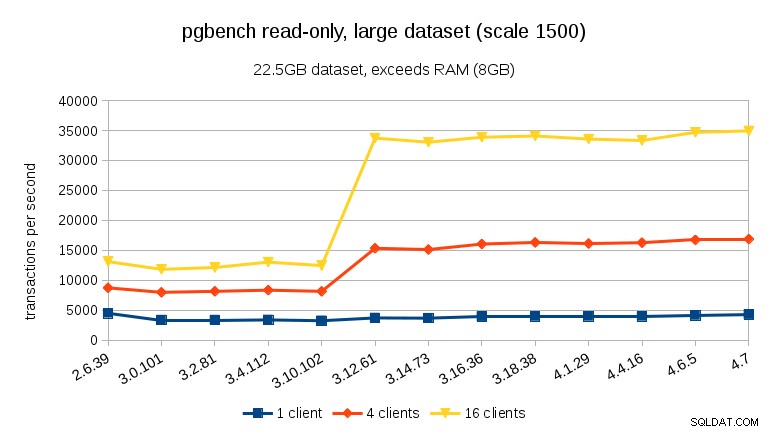
För den minsta datamängden finns det ett tydligt prestandafall mellan 3,4 och 3,10 för alla klientantal. Resultaten för 16 klienter (4 gånger antalet kärnor) återställs dock mer än i 3.12.
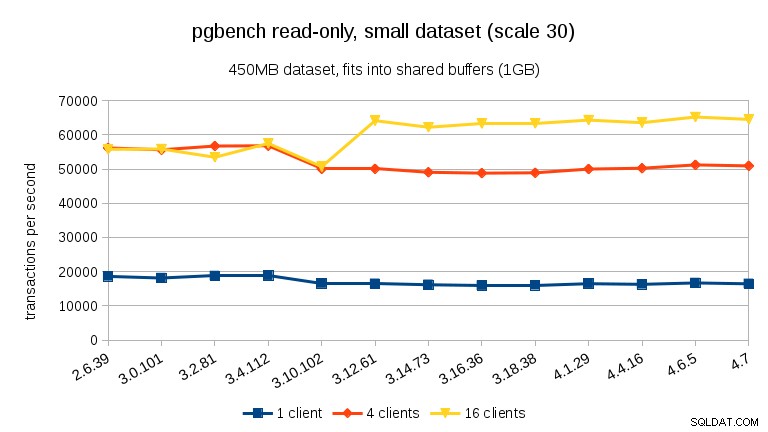
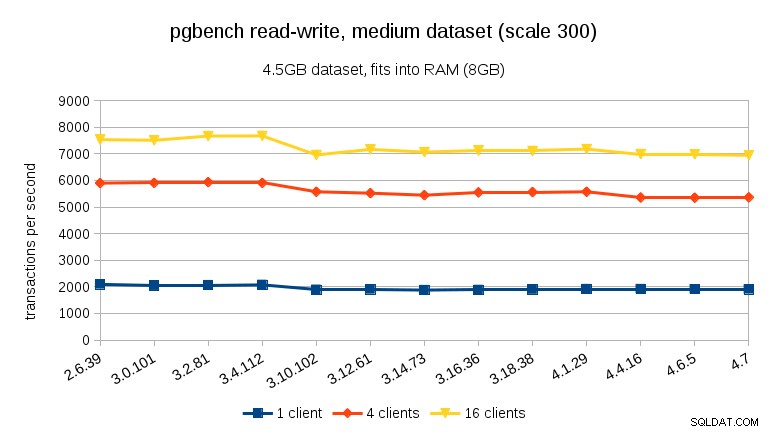
För den medium datamängden (passar i RAM men inte i delade buffertar) kan vi se samma minskning mellan 3.4 och 3.10 men inte återställningen i 3.12.
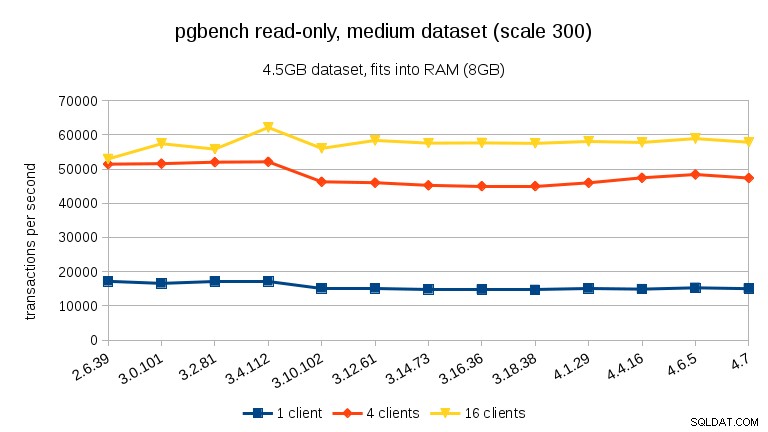
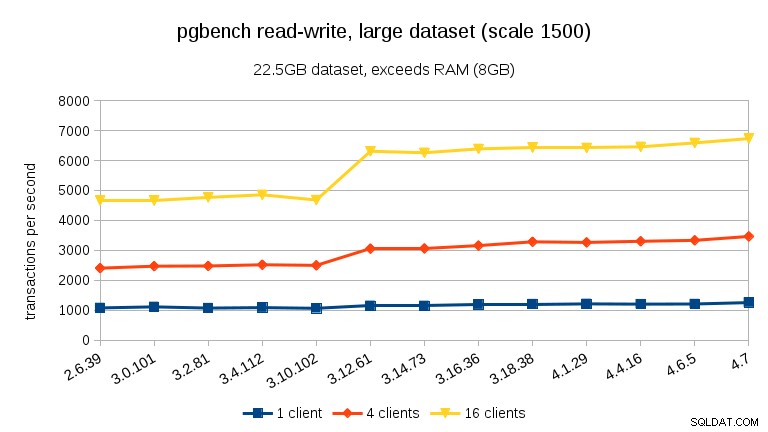
För stora datamängder (som överstiger RAM, så starkt I/O-bundet) är resultaten väldigt olika – jag är inte säker på vad som hände mellan 3.10 och 3.12, men prestandaförbättringen (särskilt för högre klientantal) är ganska häpnadsväckande.
läs-skriv
För läs-skriv-arbetsbelastningen är resultaten ganska likartade. För de små och medelstora datamängderna kan vi observera samma ~10% minskning mellan 3,4 och 3,10, men tyvärr ingen återhämtning i 3,12.
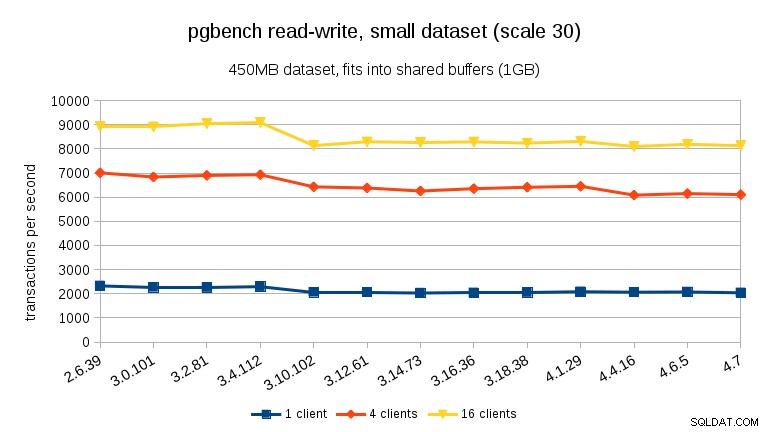
För den stora datamängden (återigen, betydligt I/O-bunden) kan vi se liknande förbättringar i 3.12 (inte lika signifikant som för skrivskyddad arbetsbelastning, men fortfarande betydande):
Sammanfattning
Jag vågar inte dra slutsatser från ett enda riktmärke på en enda maskin, men jag tror att det är säkert att säga:
- Det övergripande resultatet är ganska stabilt, men vi kan se några betydande prestandaförändringar (i båda riktningarna).
- Med datamängder som passar in i minnet (antingen i shared_buffers eller åtminstone i RAM) ser vi en mätbar prestandaminskning mellan 3,4 och 3,10. Vid skrivskyddat test återställs detta delvis i 3.12 (men bara för många klienter).
- Med datamängder som överstiger minnet, och därmed främst I/O-bundna, ser vi inga sådana prestandasänkningar utan istället en betydande förbättring i 3.12.
När det gäller orsakerna till att de plötsliga förändringarna inträffar är jag inte helt säker. Det finns många möjligen relevanta åtaganden mellan versionerna, men jag är inte säker på hur man identifierar den korrekta utan omfattande (och tidskrävande) testning. Om du har andra idéer (t.ex. är medveten om sådana åtaganden), låt mig veta.