I min tidigare artikel började vi beskriva grunderna för kommandot EXPLAIN och analyserade vad som händer i PostgreSQL när en fråga körs.
Jag kommer att fortsätta skriva om grunderna i EXPLAIN i PostgreSQL. Informationen är en kort recension av Understanding EXPLAIN av Guillaume Lelarge. Jag rekommenderar starkt att läsa originalet eftersom viss information missas.
Cache
Vad händer på fysisk nivå när vi kör vår fråga? Låt oss ta reda på det. Jag distribuerade min server på Ubuntu 13.10 och använde diskcacher på OS-nivå.
Jag stoppar PostgreSQL, gör ändringar i filsystemet, rensar cacheminnet och kör PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
När cachen är tömd kör du frågan med alternativet BUFFAR
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Vi läser tabellen blockvis. Cachen är tom. Vi var tvungna att komma åt 8334 block för att läsa hela tabellen från disken.
Buffertar:delad läsning är antalet block som PostgreSQL läser från disken.
Kör den föregående frågan
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffertar:delad träff är antalet block som hämtas från PostgreSQL-cachen.
Med varje fråga tar PostgreSQL mer och mer data från cachen och fyller därmed sin egen cache.
Cacheläsoperationer är snabbare än diskläsoperationer. Du kan se denna trend genom att spåra det totala körtidsvärdet.
Cachelagringsstorleken definieras av shared_buffers-konstanten i postgresql.conf-filen.
VAR
Lägg till villkoret i frågan
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Det finns inga index på bordet. När frågan körs, skannas varje post i tabellen sekventiellt (Seq Scan) och jämförs med villkoret c1> 500. Om villkoret är uppfyllt läggs posten till resultatet. Annars kasseras den. Filter indikerar detta beteende, liksom kostnadsvärdet ökar.
Det uppskattade antalet rader minskar.
Den ursprungliga artikeln förklarar varför kostnaden tar detta värde och hur det uppskattade antalet rader beräknas.
Det är dags att skapa index.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Det uppskattade antalet rader har ändrats. Hur är det med indexet?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Endast 510 rader på mer än 1 miljon filtreras. PostgreSQL var tvungen att läsa mer än 99,9 % av tabellen.
Vi kommer att tvinga använda indexet genom att inaktivera Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

I Index Scan och Index Cond används foo_c1_idx index istället för Filter.
När du väljer hela tabellen kommer användningen av indexet att öka kostnaden och tiden för att köra frågan.
Aktivera Seq Scan:
SET enable_seqscan TO on;
Ändra frågan:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
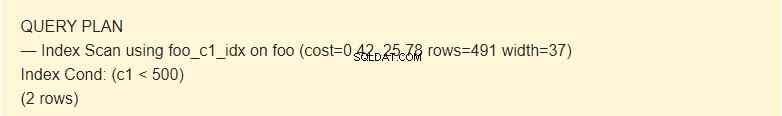
Här använder planeraren indexet.
Låt oss nu komplicera värdet genom att lägga till textfältet.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Som du kan se används foo_c1_idx-indexet för c1 <500. För att utföra c2 ~~ 'abcd%'::text, använd filtret.
Det bör noteras att POSIX-formatet för LIKE-operatorn används i resultatet av resultaten. Om det bara finns textfältet i villkoret:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan tillämpas.
Bygg indexet med c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Indexet tillämpas inte eftersom min databas för testfält använder UTF-8-kodning.
När du bygger indexet är det nödvändigt att ange klassen för text_pattern_ops-operatorn:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Bra! Det fungerade!
Bitmap Index Scan använder foo_c2_idx1 index för att bestämma de poster vi behöver. Sedan går PostgreSQL till tabellen (Bitmap Heap Scan) för att se till att dessa poster faktiskt existerar. Detta beteende hänvisar till versionshanteringen av PostgreSQL.
Om du bara väljer fältet som indexet är byggt på, istället för hela raden:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan kommer att utföras snabbare än Index Scan på grund av att det inte är nödvändigt att läsa raden i tabellen:width=4.
Slutsats
- Seq Scan läser hela tabellen
- Index Scan använder indexet för WHERE-satserna och läser tabellen när man väljer rader
- Bitmap Index Scan använder Index Scan och urvalskontroll genom tabellen. Effektiv för ett stort antal rader.
- Endast indexsökning är det snabbaste blocket, som endast läser indexet.
Mer läsning:
Frågeoptimering i PostgreSQL. FÖRKLARA Grunderna – Del 3