För ett par år sedan (på pgconf.eu 2014 i Madrid) presenterade jag ett föredrag som heter "Performance Archaeology" som visade hur prestanda förändrades i de senaste PostgreSQL-utgåvorna. Jag gjorde det föredraget eftersom jag tycker att långsiktigheten är intressant och kan ge oss insikter som kan vara mycket värdefulla. För personer som faktiskt arbetar med PostgreSQL-kod som jag är det en användbar guide för framtida utveckling, och för PostgreSQL-användare kan den hjälpa till med att utvärdera uppgraderingar.
Så jag har bestämt mig för att upprepa den här övningen och skriva ett par blogginlägg som analyserar prestanda för ett antal PostgreSQL-versioner. I 2014 års föredrag började jag med PostgreSQL 7.4, som vid den tidpunkten var cirka 10 år gammal (släpptes 2003). Den här gången börjar jag med PostgreSQL 8.3, som är ungefär 12 år gammal.
Varför inte börja med PostgreSQL 7.4 igen? Det finns ungefär tre huvudsakliga skäl till varför jag bestämde mig för att börja med PostgreSQL 8.3. För det första, allmän lättja. Ju äldre version, desto svårare kan det vara att bygga med nuvarande kompilatorversioner etc. För det andra tar det tid att köra korrekta benchmarks, särskilt med större mängder data, så att lägga till en enda större version kan enkelt lägga till ett par dagars maskintid. Det verkade helt enkelt inte värt det. Och slutligen introducerade 8.3 ett antal viktiga förändringar – autovakuumförbättringar (aktiverade som standard, samtidiga arbetsprocesser, …), fulltextsökning integrerad i kärnan, spridning av kontrollpunkter och så vidare. Så jag tycker att det är helt vettigt att börja med PostgreSQL 8.3. Som släpptes för cirka 12 år sedan, så den här jämförelsen kommer faktiskt att täcka en längre tidsperiod.
Jag har bestämt mig för att jämföra tre grundläggande arbetsbelastningstyper – OLTP, analys och fulltextsökning. Jag tror att OLTP och analys är ganska självklara val, eftersom de flesta applikationer är en blandning av dessa två grundläggande typer. Fulltextsökningen låter mig demonstrera förbättringar av speciella typer av index, som också används för att indexera populära datatyper som JSONB, typer som används av PostGIS etc.
Varför göra det här överhuvudtaget?
Är det verkligen värt ansträngningen? Vi gör ju riktmärken under utveckling hela tiden för att visa att en patch hjälper och/eller att den inte orsakar regression, eller hur? Problemet är att dessa vanligtvis bara är "partiella" riktmärken, jämför två särskilda åtaganden, och vanligtvis med ett ganska begränsat urval av arbetsbelastningar som vi tror kan vara relevanta. Vilket är helt logiskt – du kan helt enkelt inte köra ett helt batteri av arbetsbelastningar för varje commit.
Då och då (vanligtvis kort efter en release av en ny PostgreSQL-storversion) kör folk tester som jämför den nya versionen med den föregående, vilket är trevligt och jag uppmuntrar dig att köra sådana riktmärken (vare sig det är någon form av standardriktmärke, eller något specifikt för din applikation). Men det är svårt att kombinera dessa resultat till en längre sikt, eftersom dessa tester använder olika konfigurationer och hårdvara (vanligtvis en nyare för den nyare versionen) och så vidare. Så det är svårt att göra tydliga bedömningar om förändringar i allmänhet.
Detsamma gäller applikationsprestanda, vilket är det "ultimata riktmärket" förstås. Men folk kanske inte uppgraderar till alla större versioner (ibland kan de hoppa över ett par versioner, t.ex. från 9.5 till 12). Och när de uppgraderar, kombineras det ofta med hårdvaruuppgraderingar etc. För att inte tala om att applikationer utvecklas över tiden (nya funktioner, ytterligare komplexitet), mängden data och antalet samtidiga användare växer, etc.
Det är vad den här bloggserien försöker visa – långsiktiga trender i PostgreSQL-prestanda för vissa grundläggande arbetsbelastningar, så att vi – utvecklarna – får en varm och luddig känsla av det goda arbetet genom åren. Och för att visa användarna att även om PostgreSQL är en mogen produkt vid det här laget, finns det fortfarande betydande förbättringar i varje ny större version.
Det är inte mitt mål att använda dessa riktmärken för jämförelse med andra databasprodukter, eller att producera resultat för att möta någon officiell ranking (som TPC-H). Mitt mål är helt enkelt att utbilda mig till PostgreSQL-utvecklare, kanske identifiera och undersöka några problem och dela resultaten med andra.
Rättvis jämförelse?
Jag tror inte att några sådana jämförelser av versioner släppta över 12 år inte kan vara helt rättvisa, eftersom vilken programvara som helst utvecklas i ett visst sammanhang – hårdvara är ett bra exempel för ett databassystem. Om du tittar på maskinerna du använde för 12 år sedan, hur många kärnor hade de, hur mycket RAM? Vilken typ av lagring använde de?
En typisk mellanregisterserver 2008 hade kanske 8-12 kärnor, 16GB RAM och en RAID med ett par SAS-enheter. En typisk mellanregisterserver idag kan ha ett par dussintals kärnor, hundratals GB RAM och SSD-lagring.
Mjukvaruutveckling är organiserad efter prioritet – det finns alltid fler potentiella uppgifter än du hinner med, så du måste välja uppgifter med det bästa förhållandet mellan kostnad och nytta för dina användare (särskilt de som finansierar projektet, direkt eller indirekt). Och under 2008 var vissa optimeringar förmodligen inte relevanta ännu – de flesta maskiner hade inte extrema mängder RAM så att optimera för stora delade buffertar var till exempel inte värt det ännu. Och många av CPU-flaskhalsarna överskuggades av I/O, eftersom de flesta maskiner hade "spinrost"-lagring.
Obs:Naturligtvis fanns det kunder som använde ganska stora maskiner redan då. Vissa använde Community Postgres med olika tweaks, andra bestämde sig för att köra med en av de olika Postgres gafflarna med ytterligare möjligheter (t.ex. massiv parallellism, distribuerade frågor, användning av FPGA etc.). Och detta påverkade förstås samhällsutvecklingen också.
När de större maskinerna blev vanligare med åren hade fler människor råd med maskiner med stora mängder RAM och högt antal kärnor, vilket förändrade förhållandet mellan kostnad och nytta. Flaskhalsarna undersöktes och åtgärdades, vilket gjorde att nyare versioner kunde prestera bättre.
Detta innebär att ett riktmärke som detta alltid är lite orättvist – det kommer att gynna antingen den äldre eller nyare versionen, beroende på installationen (hårdvara, konfiguration). Jag har försökt välja hårdvara och konfigurationsparametrar så att det inte är så illa för äldre versioner.
Poängen jag försöker göra är att detta inte betyder att de äldre PostgreSQL-versionerna var skit – det är så här mjukvaruutveckling fungerar. Du åtgärdar de flaskhalsar som dina användare sannolikt kommer att stöta på, inte de flaskhalsar de kan stöta på om 10 år.
Hårdvara
Jag föredrar att göra benchmarks på fysisk hårdvara jag har direkt tillgång till, eftersom det gör att jag kan kontrollera alla detaljer, jag har tillgång till alla detaljer och så vidare. Så jag har använt maskinen jag har på vårt kontor – inget fancy, men förhoppningsvis tillräckligt bra för detta ändamål.
- 2x E5-2620 v4 (16 kärnor, 32 trådar)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (data)
- 3 x 7.2k SATA RAID0 (tillfälligt tabellutrymme)
- kärna 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Jag har också använt en andra – mycket mindre – maskin, med bara 4 kärnor och 8 GB RAM, som generellt visar samma förbättringar/regressioner, bara mindre uttalade.
pgbench
Som ett benchmarkingverktyg har jag använt den välkända pgbench, med den senaste versionen (från PostgreSQL 13) för att testa alla versioner. Detta eliminerar möjlig fördom på grund av optimeringar gjorda i pgbench över tid, vilket gör resultaten mer jämförbara.
Riktmärket testar ett antal olika fall, varierande ett antal parametrar, nämligen:
skala
- liten – data passar in i delade buffertar, visar låsningsproblem etc.
- medium – data större än delade buffertar men passar in i RAM-minnet, vanligtvis CPU-bundet (eller möjligen I/O för läs-skriv-arbetsbelastningar)
- stor – data större än RAM, främst I/O-bunden
lägen
- skrivskyddad – pgbench -S
- läs-skriv – pgbench -N
kundantal
- 1, 4, 8, 16, 32, 64, 128, 256
- antalet pgbench-trådar (-j) justeras därefter
Resultat
OK, låt oss titta på resultaten. Jag kommer att presentera resultat från NVMe-lagringen först, sedan visar jag några intressanta resultat med SATA RAID-lagring.
NVMe SSD / skrivskyddad
För den lilla datamängden (som helt passar in i delade buffertar) ser de skrivskyddade resultaten ut så här:
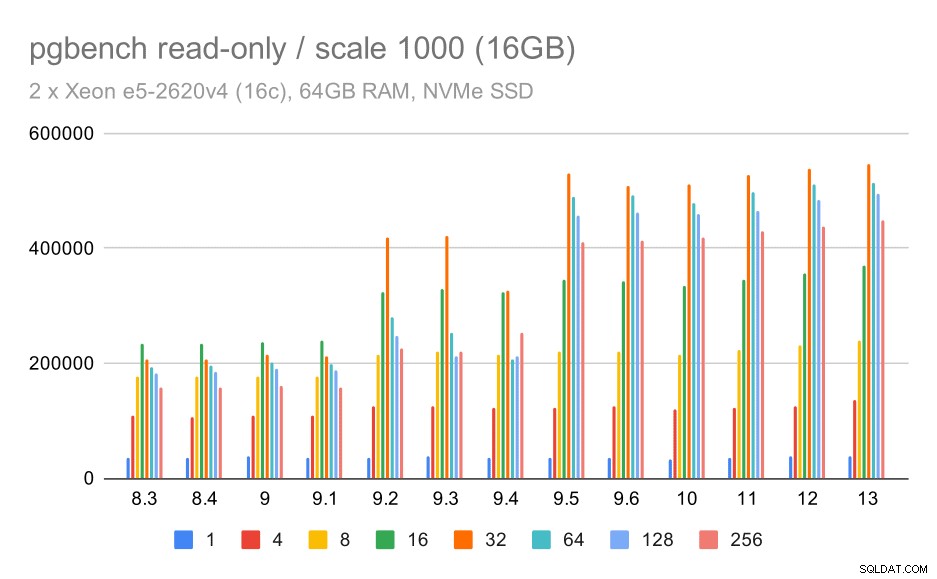
pgbench-resultat / skrivskyddad på liten datamängd (skala 100, dvs. 1,6 GB)
Det var uppenbart en betydande ökning av genomströmningen i 9.2, som innehöll ett antal prestandaförbättringar, till exempel snabb väg för låsning. Genomströmningen för en enskild klient sjunker faktiskt lite – från 47 000 tps till endast cirka 42 000 tps. Men för högre klientantal är förbättringen i 9.2 ganska tydlig.
pgbench-resultat / skrivskyddad på medium datauppsättning (skala 1000, dvs. 16 GB)
För den medelstora datamängden (som är större än delade buffertar men ändå passar in i RAM) verkar det finnas en viss förbättring i 9.2 också, även om det inte är lika tydligt som ovan, följt av en mycket tydligare förbättring av 9.5, troligen tack vare förbättringar av låsets skalbarhet .
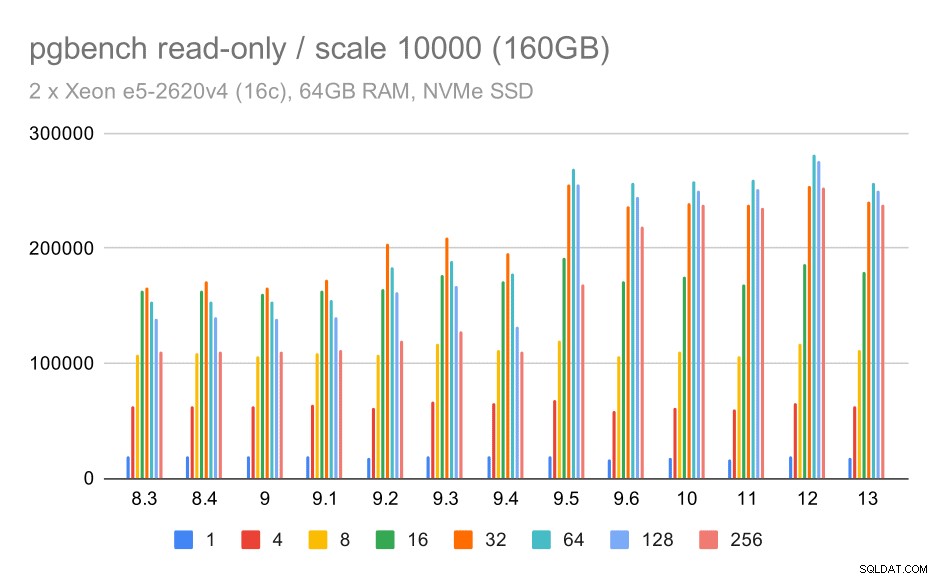
pgbench-resultat / skrivskyddad för stor datamängd (skala 10 000, dvs. 160 GB)
På den största datamängden, som mest handlar om förmågan att effektivt utnyttja lagringen, finns det också en viss snabbhet – troligen tack vare 9.5-förbättringarna också.
NVMe SSD / läs-skriv
Läs- och skrivresultaten visar också vissa förbättringar, även om de inte är lika uttalade. På den lilla datamängden ser resultaten ut så här:
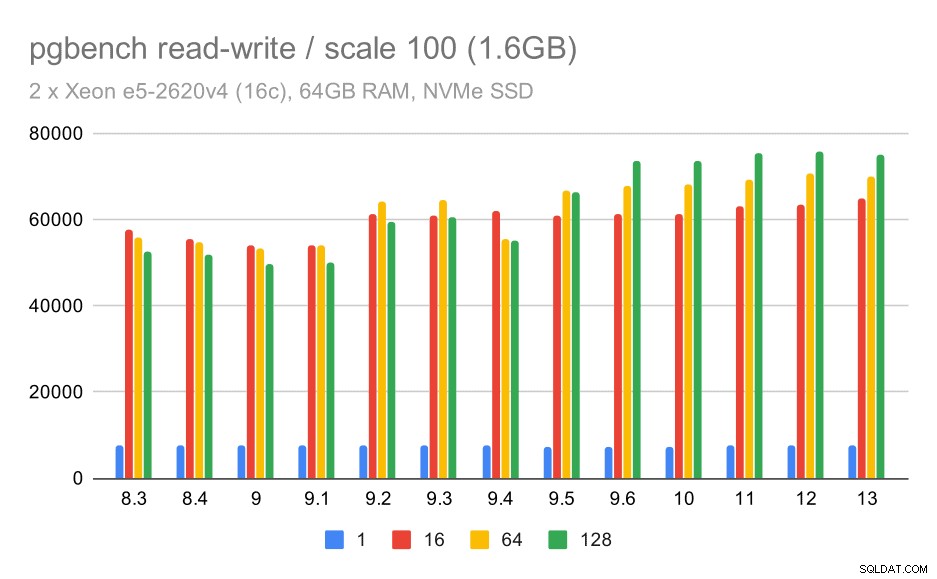
pgbench-resultat / läs-skriv på liten datamängd (skala 100, dvs. 1,6 GB)
Så en blygsam förbättring från cirka 52 000 till 75 000 tps med tillräckligt många klienter.
För den medelstora datamängden är förbättringen mycket tydligare – från cirka 27 000 till 63 000 tps, dvs genomströmningen mer än fördubblas.
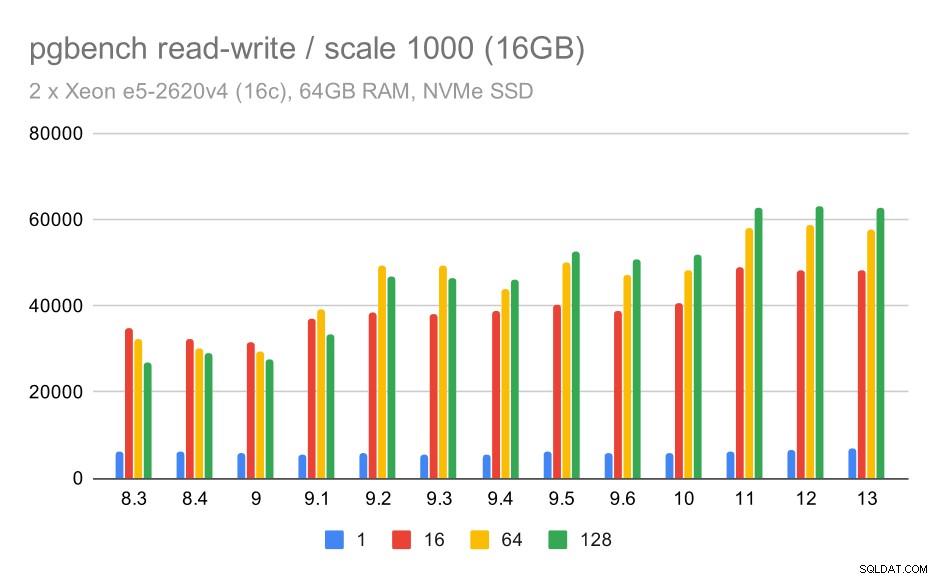
pgbench-resultat / läs-skriv på medium datauppsättning (skala 1000, dvs. 16 GB)
För den största datamängden ser vi en liknande övergripande förbättring, men det verkar finnas en viss regression mellan 9,5 och 11.
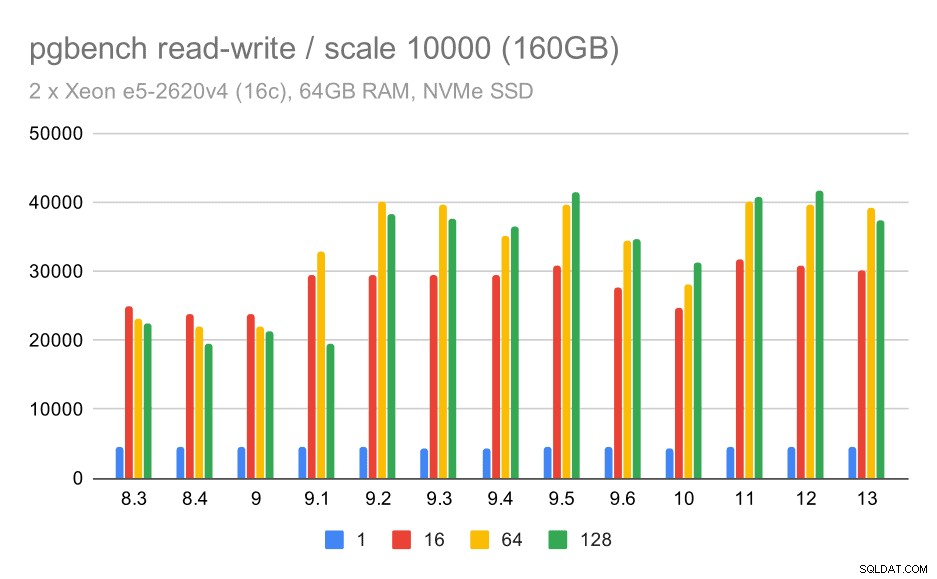
pgbench-resultat / läs-skriv på stor datamängd (skala 10000, dvs. 160 GB)
SATA RAID / skrivskyddad
För SATA RAID-lagring är de skrivskyddade resultaten inte så trevliga. Vi kan ignorera de små och medelstora datamängderna, för vilka lagringssystemet är irrelevant. För den stora datamängden är genomströmningen något bullrig men den verkar faktiskt minska med tiden – särskilt sedan PostgreSQL 9.6. Jag vet inte vad som är anledningen till detta (ingenting i 9.6 release notes sticker ut som en tydlig kandidat), men det verkar som någon form av regression.
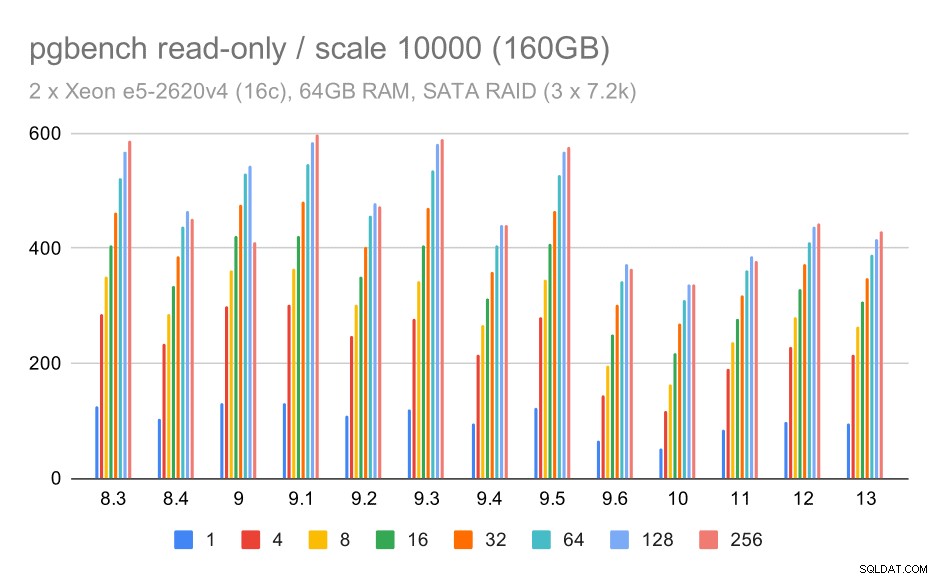
pgbench-resultat på SATA RAID / skrivskyddad på stor datamängd (skala 10 000, dvs. 160 GB)
SATA RAID / läs-skriv
Men läs-skrivbeteendet verkar mycket trevligare. På den lilla datamängden ökar genomströmningen från cirka 600 tps till mer än 6000 tps. Jag skulle slå vad om att detta är tack vare förbättringar av group commit i 9.1 och 9.2.
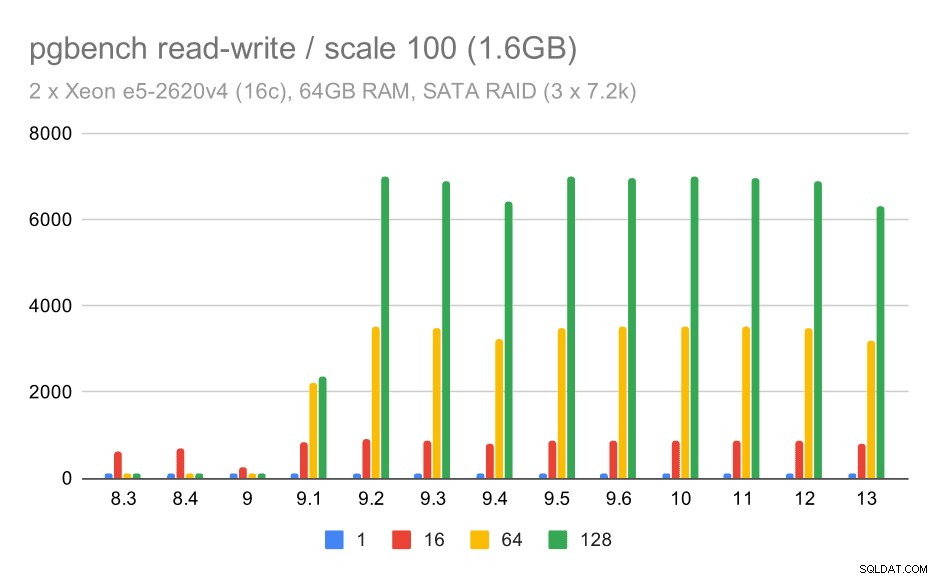
pgbench-resultat på SATA RAID / läs-skriv på liten datamängd (skala 100, dvs. 1,6 GB)
För medelstora och stora skalor kan vi se liknande – men mindre – förbättringar, eftersom lagringen också behöver hantera I/O-förfrågningar för att läsa och skriva datablocken. För den medelstora skalan behöver vi bara göra skrivningarna (eftersom data passar in i RAM), för den stora skalan behöver vi också göra läsningarna – så den maximala genomströmningen är ännu lägre.
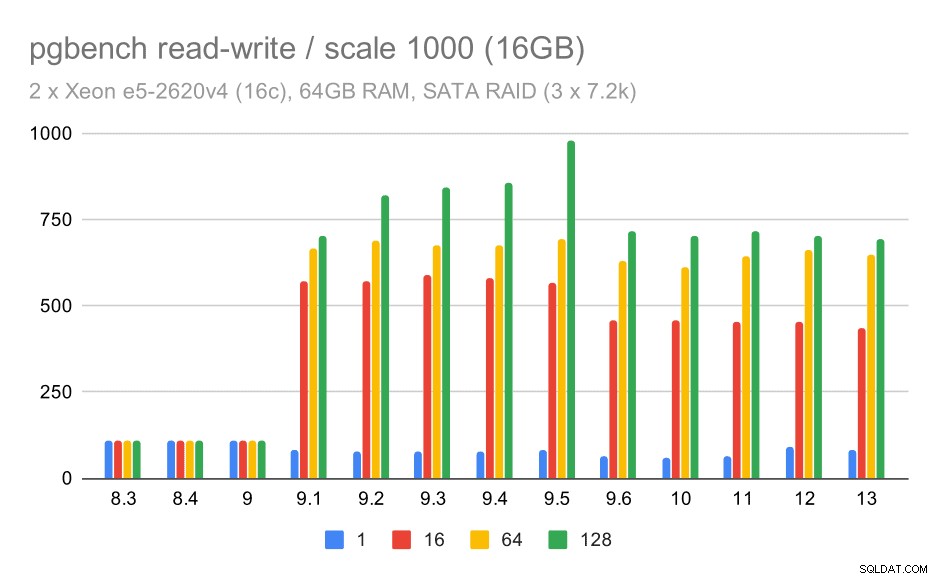
pgbench-resultat på SATA RAID / läs-skriv på medium datamängd (skala 1000, dvs. 16 GB)
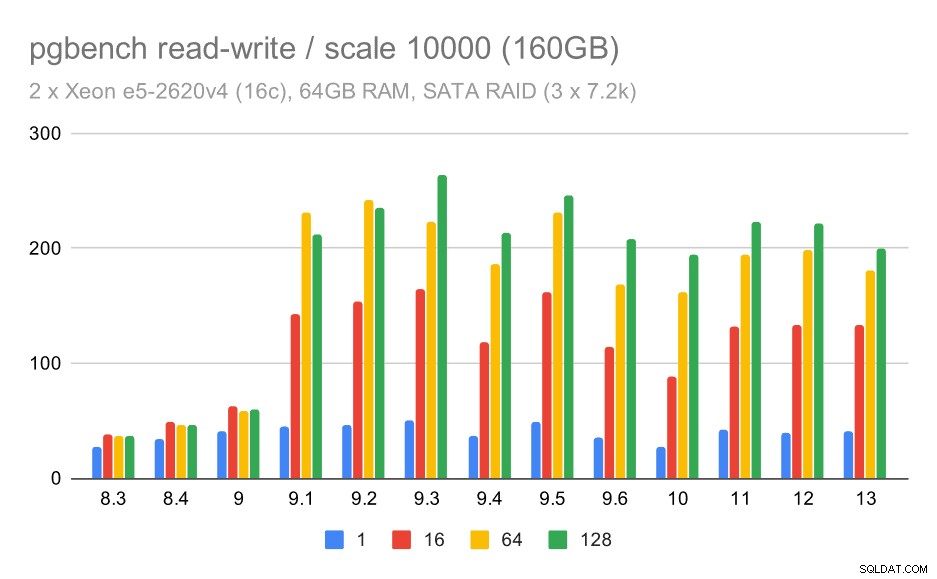
pgbench-resultat på SATA RAID / läs-skriv på stor datamängd (skala 10000, dvs. 160 GB)
Sammanfattning och framtid
För att sammanfatta detta, för NVMe-installationen verkar slutsatserna vara ganska positiva. För den skrivskyddade arbetsbelastningen finns en måttlig hastighetsökning i 9.2 och betydande hastighetsökning i 9.5, tack vare skalbarhetsoptimeringar, medan för läs-skrivarbetsbelastningen förbättrades prestandan med cirka 2 gånger över tiden, i flera versioner/steg.
Med SATA RAID-installationen är slutsatserna dock något blandade. I fallet med skrivskyddad arbetsbelastning finns det mycket variation/brus och möjlig regression i 9.6. För läs-skriv-arbetsbelastningen finns det en enorm snabbhet i 9.1 där genomströmningen plötsligt ökade från 100 tps till cirka 600 tps.
Hur är det med förbättringar i framtida PostgreSQL-versioner? Jag har inte en mycket tydlig uppfattning om vad nästa stora förbättring kommer att bli – jag är dock säker på att andra PostgreSQL-hackers kommer att komma med briljanta idéer som gör saker mer effektiva eller tillåter att utnyttja tillgängliga hårdvaruresurser. Patchen för att förbättra skalbarheten med många anslutningar eller patchen för att lägga till stöd för icke-flyktiga WAL-buffertar är exempel på sådana förbättringar. Vi kanske ser några radikala förbättringar av PostgreSQL-lagring (effektivare format på disken, använder direkt I/O etc.), indexering, etc.