Låt oss börja vår SQL-resa för att förstå aggregeringsdata i SQL och typer av aggregering inklusive enkla och glidande aggregationer.
Innan vi hoppar till aggregeringarna är det värt att överväga intressanta fakta som ofta missas av vissa utvecklare när det kommer till SQL i allmänhet och aggregeringen i synnerhet.
I den här artikeln hänvisar SQL till T-SQL som är Microsoft-versionen av SQL och har fler funktioner än standard-SQL.
Matematik bakom SQL
Det är mycket viktigt att förstå att T-SQL är baserat på några solida matematiska begrepp även om det inte är ett styvt matematikbaserat språk.
Enligt boken "Microsoft_SQL_Server_2008_T_SQL_Fundamentals" av Itzik Ben-Gan är SQL designad för att fråga och hantera data i ett relationsdatabashanteringssystem (RDBMS).
Själva relationsdatabashanteringssystemet är baserat på två solida matematiska grenar:
- Mängdteori
- Predikatlogik
Mängdteori
Mängdlära, som namnet indikerar, är en gren av matematiken om mängder som också kan kallas samlingar av bestämda distinkta objekt.
Kort sagt, i mängdteorin tänker vi på saker eller objekt som en helhet på samma sätt som vi tänker på ett enskilt objekt.
Till exempel är en bok en uppsättning av alla bestämda distinkta böcker, så vi tar en bok som helhet vilket är tillräckligt för att få detaljer om alla böcker i den.
Predikatlogik
Predikatlogik är en boolesk logik som returnerar sant eller falskt beroende på tillståndet eller värdena för variablerna.
Predikatlogik kan användas för att genomdriva integritetsregler (priset måste vara större än 0,00) eller filtrera data (där priset är mer än 10,00), men i T-SQL-sammanhang har vi tre logiska värden enligt följande:
- Sant
- False
- Okänd (Null)
Detta kan illustreras enligt följande:
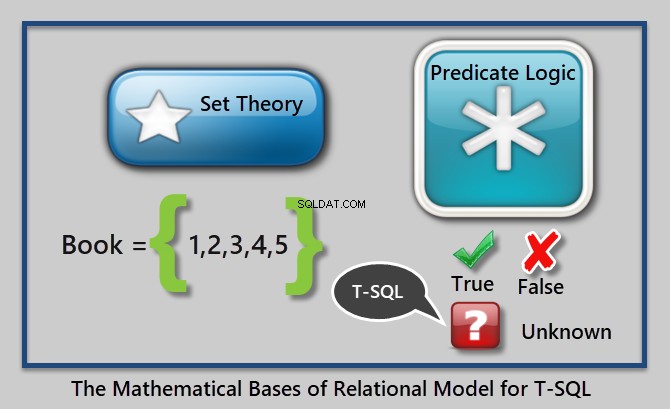
Ett exempel på ett predikat är "Där bokens pris är högre än 10,00".
Det räcker med matematik, men kom ihåg att jag kommer att hänvisa till det senare i artikeln.
Varför det är enkelt att samla data i SQL
Att aggregera data i SQL i sin enklaste form handlar om att ta reda på summan på en gång.
Om vi till exempel har en kundtabell som innehåller en lista över alla kunder tillsammans med deras uppgifter kan aggregerade data från kundtabellen ge oss det totala antalet kunder vi har.
Som diskuterats tidigare tänker vi på en uppsättning som en enskild artikel, så vi använder helt enkelt en aggregatfunktion på tabellen för att få summan.
Eftersom SQL ursprungligen är ett uppsättningsbaserat språk (som diskuterats tidigare), så är det relativt lättare att tillämpa aggregerade funktioner på det jämfört med andra språk.
Till exempel, om vi har en produkttabell som har register över alla produkter i databasen kan vi direkt tillämpa räknefunktionen på en produkttabell för att få det totala antalet produkter istället för att räkna dem en efter en i en slinga.
Dataaggregationsrecept
För att aggregera data i SQL behöver vi åtminstone följande saker:
- Data (tabell) med kolumner som när de är aggregerade är meningsfulla
- En aggregerad funktion som ska användas på data
Förbereda provdata (tabell)
Låt oss ta ett exempel på en enkel ordningstabell som innehåller tre saker (kolumner):
- Beställningsnummer (OrderId)
- Datum då beställningen gjordes (OrderDate)
- Beställningens belopp (TotalAmount)
Låt oss skapa AggregateSample-databasen för att gå vidare:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Skapa nu ordertabellen i exempeldatabasen enligt följande:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Pulera provdata
Fyll tabellen genom att lägga till en rad:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Låt oss titta på tabellen nu:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
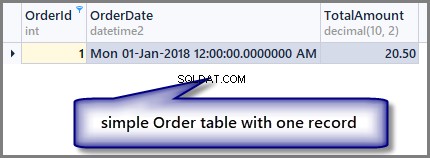
Observera att jag använder dbForge Studio för SQL Server i den här artikeln så endast utdatautseendet kan skilja sig om du kör samma kod i SSMS (SQL Server Management Studio), det är ingen skillnad vad gäller skript och deras resultat.
Grundläggande samlade funktioner
De grundläggande aggregerade funktionerna som kan tillämpas på tabellen är följande:
- Summa
- Räkna
- Min
- Max
- Genomsnitt
Aggregerande enstaka inspelningstabell
Nu är den intressanta frågan, "kan vi aggregera (summa eller räkna) data (poster) i en tabell om den bara har en rad som i vårt fall?" Svaret är "Ja", det kan vi, även om det inte är så meningsfullt men det kan hjälpa oss att förstå hur data blir redo för aggregering.
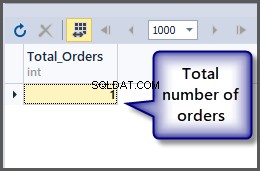
För att få det totala antalet order använder vi funktionen count() med tabellen, som diskuterats tidigare kan vi helt enkelt tillämpa aggregatfunktionen på tabellen eftersom SQL är ett setbaserat språk och operationer kan tillämpas på en uppsättning direkt.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
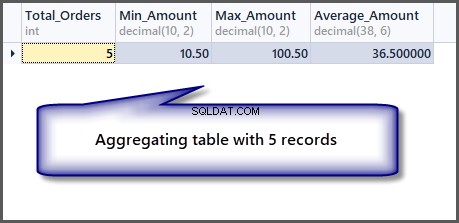
Hur är det nu med beställningen med ett lägsta, högsta och genomsnittliga belopp för en enda post:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
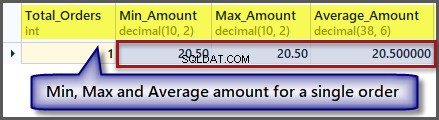
Som vi kan se från utdata är det minsta, högsta och genomsnittliga beloppet detsamma om vi har en enda post, så det är möjligt att tillämpa en aggregerad funktion på en enda post, men det ger oss samma resultat.
Vi behöver minst mer än en post för att förstå den aggregerade informationen.
Tabell för sammanställning av flera poster
Låt oss nu lägga till ytterligare fyra poster enligt följande:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
Tabellen ser nu ut som följer:
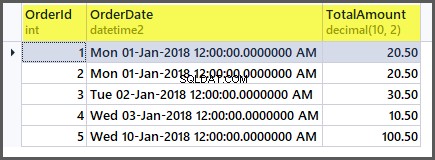
Om vi tillämpar de aggregerade funktionerna på tabellen nu kommer vi att få bra resultat:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
Gruppera aggregerad data
Vi kan gruppera den aggregerade informationen efter vilken kolumn eller uppsättning kolumner som helst för att få aggregat baserat på den kolumnen.
Till exempel, om vi vill veta det totala antalet beställningar per datum, vi måste gruppera tabellen efter datum med hjälp av Group by-satsen enligt följande:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
Utgången är som följer:
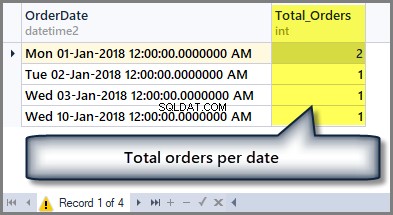
Så om vi vill se summan av hela beställningsbeloppet, vi kan helt enkelt tillämpa summafunktionen på kolumnen för totalt belopp utan någon gruppering enligt följande:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
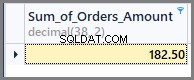
För att få summan av orderbelopp per datum lägger vi helt enkelt till grupp efter datum till ovanstående SQL-sats enligt följande:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
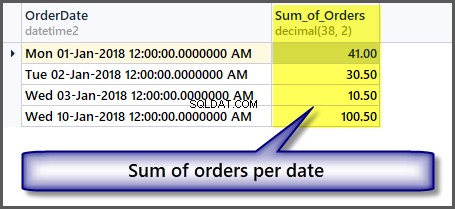
Hämta totaler utan att gruppera data
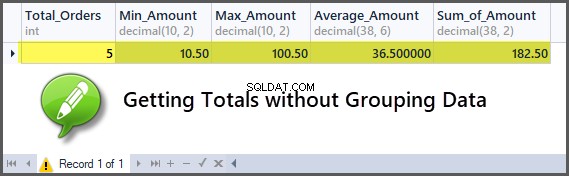
Vi kan genast få summor som totala order, högsta orderbelopp, minsta orderbelopp, summa av orderbelopp, genomsnittligt orderbelopp utan att behöva gruppera det om aggregeringen är avsedd för alla tabeller.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
Lägga till kunder i beställningarna
Låt oss lägga till lite kul genom att lägga till kunder i vår tabell. Vi kan göra detta genom att skapa en annan tabell över kunder och skicka kund-id till ordertabellen, men för att hålla det enkelt och för att håna datalagerstilen (där tabeller är avnormaliserade), lägger jag till kolumnen kundnamn i ordertabellen enligt följande :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
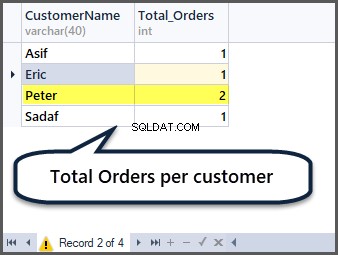
Få totala beställningar per kund
Kan du nu gissa hur man får totala beställningar per kund? Du måste gruppera efter kund (CustomerName) och tillämpa den aggregerade funktionen count() på alla poster enligt följande:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
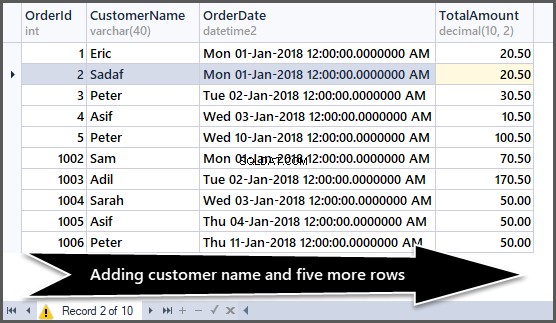
Lägga till ytterligare fem poster i beställningstabellen
Nu ska vi lägga till fem rader till i den enkla ordningstabellen enligt följande:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Ta en titt på data nu:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
Få totala beställningar per kund sorterade efter högsta till lägsta beställning
Om du är intresserad av den totala beställningen per kund sorterad efter max- till minimiorder, är det ingen dum idé att dela upp detta i mindre steg enligt följande:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
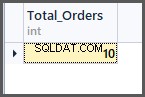
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
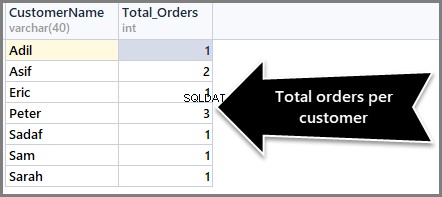
För att sortera order räknas från maximalt till minimum måste vi använda satsen Order By DESC (fallande ordning) med count() i slutet enligt följande:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
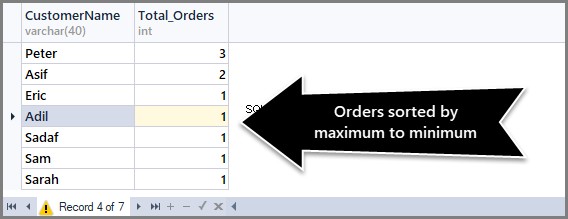
Få totala beställningar per datum sorterade efter senaste beställning först
Med metoden ovan kan vi nu ta reda på de totala beställningarna per datum sorterade efter senaste beställning först enligt följande:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
CAST-funktionen hjälper oss att bara få fram datumdelen. Utgången är som följer:
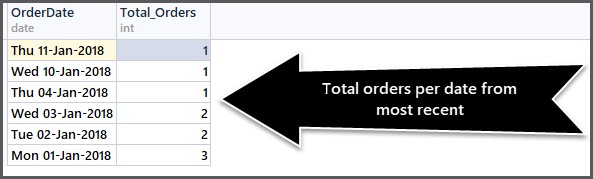
Du kan använda så många kombinationer som möjligt så länge de är vettiga.
Köra aggregationer
Nu när vi är bekanta med att tillämpa aggregerade funktioner på vår data, låt oss gå vidare till den avancerade formen av aggregering och en sådan aggregering är den löpande aggregeringen.
Körande aggregering är aggregering som tillämpas på en delmängd av data snarare än på hela datamängden, vilket hjälper oss att skapa små fönster på datan.
Hittills har vi sett att alla aggregerade funktioner tillämpas på alla rader i tabellen som kan grupperas efter någon kolumn som orderdatum eller kundnamn, men med löpande aggregering har vi friheten att tillämpa de aggregerade funktionerna utan att gruppera hela dataset.
Uppenbarligen betyder detta att vi kan tillämpa aggregatfunktionen utan att använda Group By-satsen, vilket är något konstigt för de SQL-nybörjare (eller ibland förbiser vissa utvecklare detta) som inte är bekanta med fönsterfunktionerna och köra aggregering.
Windows på data
Som nämnts tidigare tillämpas den löpande aggregeringen på en delmängd av dataset eller (med andra ord) på små datafönster.
Tänk på fönster som en uppsättning inom en uppsättning eller en tabell inom en tabell. Ett bra exempel på fönster på data i vårt fall är att vi har ordertabellen som innehåller beställningar som lagts på olika datum, så tänk om varje datum är ett separat fönster, då kan vi tillämpa aggregerade funktioner på varje fönster på samma sätt som vi tillämpade på bordet.
Om vi sorterar ordertabellen (SimpleOrder) efter orderdatum (OrderDate) enligt följande:
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows på data redo för körning av aggregering kan ses nedan:

Vi kan också betrakta dessa fönster eller delmängder som sex miniorderdatumbaserade tabeller och aggregat kan tillämpas på var och en av dessa minitabeller.
Användning av Partition By inuti OVER()-klausulen
Körande aggregationer kan tillämpas genom att partitionera tabellen med hjälp av "Partition by" inuti OVER()-satsen.
Till exempel, om vi vill partitionera beställningstabellen efter datum, som att varje datum är en undertabell eller ett fönster på datamängden, måste vi partitionera data efter beställningsdatum och detta kan uppnås genom att använda en aggregerad funktion som COUNT( ) med OVER() och partitionera med inuti OVER() enligt följande:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

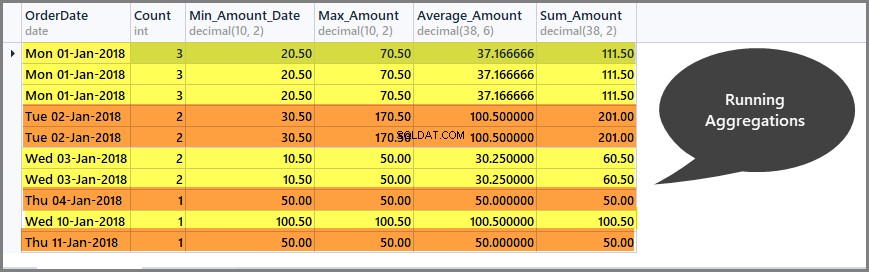
Fönstret Få löpande summor per datum (partition)
Körande aggregering hjälper oss att begränsa aggregeringsomfånget till endast det definierade fönstret och vi kan få löpande summor per fönster enligt följande:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
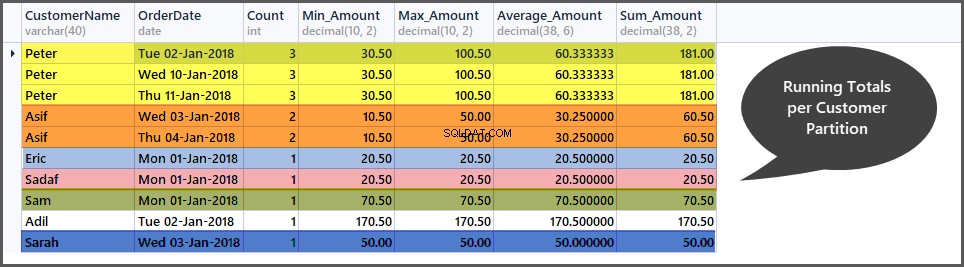
Få löpande summor per kundfönster (partition)
Precis som löpande totalsummor per datumfönster kan vi också beräkna löpande totalsummor per kundfönster genom att dela upp orderuppsättningen (tabellen) i små kundunderuppsättningar (partitioner) enligt följande:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
Glidande aggregationer
Glidande aggregering är de sammanställningar som kan appliceras på ramarna i ett fönster, vilket innebär att omfattningen begränsas ytterligare inom fönstret (partitionen).
Med andra ord, löpande summor ger oss totaler (summa, medelvärde, min, max, antal) för hela fönstret (delmängd) vi skapar i en tabell, medan glidande summor ger oss totaler (summa, medelvärde, min, max, antal) för ramen (undermängd av undermängd) inom fönstret (undermängd) i tabellen.
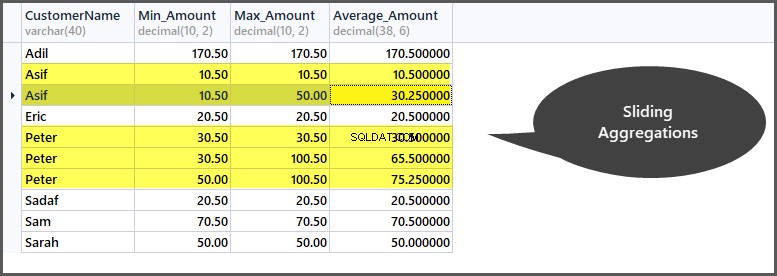
Till exempel, om vi skapar ett fönster på data baserat på (uppdelning efter kund) kund kan vi se att kunden "Peter" har tre poster i sitt fönster och alla aggregationer tillämpas på dessa tre poster. Om vi nu vill skapa en ram för endast två rader åt gången betyder det att aggregeringen minskas ytterligare och att den sedan tillämpas på den första och andra raden och sedan den andra och tredje raden och så vidare.
Användning av ROWS FÖREGÅENDE med Order By inuti OVER()-satsen
Glidande aggregering kan tillämpas genom att lägga till ROWS
Till exempel, om vi vill aggregera data för endast två rader åt gången för varje kund behöver vi glidande aggregering som ska tillämpas på ordertabellen enligt följande:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
För att förstå hur det fungerar, låt oss titta på den ursprungliga tabellen i samband med ramar och fönster:
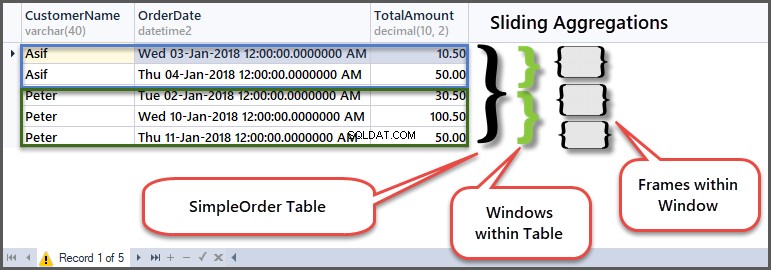
I den första raden av kunden Peters fönster lade han en beställning med beloppet 30,50 eftersom detta är början på ramen inom kundfönstret, så min och max är desamma eftersom det inte finns någon tidigare rad att jämföra med.
Därefter förblir minimibeloppet detsamma men maxbeloppet blir 100,50 eftersom föregående rad (första raden) beloppet är 30,50 och detta radbelopp är 100,50, så det maximala av de två är 100,50.
När du sedan flyttar till den tredje raden kommer jämförelsen att ske med den andra raden så att det minsta beloppet av de två är 50,00 och det maximala beloppet för de två raderna är 100,50.
MDX Year to Date (YTD) funktion och löpande aggregationer
MDX är ett flerdimensionellt uttrycksspråk som används för att söka efter flerdimensionell data (som kub) och används i Business Intelligence (BI)-lösningar.
Enligt https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx fungerar funktionen Year to Date (YTD) i MDX på samma sätt som körande eller glidande aggregering fungerar. Till exempel, YTD som ofta används i kombination utan att någon parameter tillhandahålls visar en löpande summa hittills.
Det betyder att om vi använder den här funktionen på år så ger den all årsdata, men om vi borrar ner till mars kommer det att ge oss alla summor från början av året till mars och så vidare.
Detta är mycket användbart i SSRS-rapporter.
Saker att göra
Det är allt! Du är redo att göra lite grundläggande dataanalys efter att ha gått igenom den här artikeln och du kan förbättra dina färdigheter ytterligare genom följande saker:
- Försök att skriva ett körande aggregeringsskript genom att skapa fönster på andra kolumner, t.ex. Totalt belopp.
- Försök också att skriva ett glidande sammanslagningsskript genom att skapa ramar i andra kolumner, som totalt belopp.
- Du kan lägga till fler kolumner och poster i tabellen (eller till och med fler tabeller) för att prova andra aggregeringskombinationer.
- Exempelskripten som nämns i den här artikeln kan omvandlas till lagrade procedurer för att användas i SSRS-rapporter bakom datauppsättning(ar).
Referenser:
- Ytd (MDX)
- dbForge Studio för SQL Server